

AI能写论文、画图、考高分,但连「看表读时间」「今天是星期几」都错得离谱?最新研究揭示了背后惊人的认知缺陷,提醒我们:AI很强大,但精确推理还离不开人类。
有些任务对人类来说轻而易举,但AI频频出错。
比如,单词「strawberry」中有几个字母「r」一度难倒一众顶尖LLM。
最新的研究揭示:看钟表或日历,对AI来说也很难。

图1:在测试实例中,6款大模型均无法正确读取指针式时钟,仅2款能理解日历
来自英国爱丁堡大学等机构的研究者,揭示了这个令人深思的AI现象。
他们模拟了时钟和年历,系统考察了多模态语言大模型(MLLM)解读时间与日期的能力。
结果令人失望:
AI系统读取时钟的准确率仅为38.7%,判断日历日期的准确率则只有26.3%。
在ICLR 2025的LLM推理与规划研讨会(ICLR 2025 Workshop on Reasoning and Planning for LLMs)上,他们展示了这些LLM出人意料的缺陷。

论文链接:https://arxiv.org/abs/2502.05092
为了探究MLLMs处理时间任务的能力,他们我们构建了精确定制的测试集,包含两个子集:ClockQA和CalendarQA。
ClockQA涵盖了六类模拟时钟图像(含罗马数字、缺失秒针及不同表盘颜色等变体)及其对应的时间问题;
CalendarQA包含了十年的年历图像,问题设置从简单到复杂:
元旦是星期几?
3月15日是星期几?
当年的第153天是哪天?
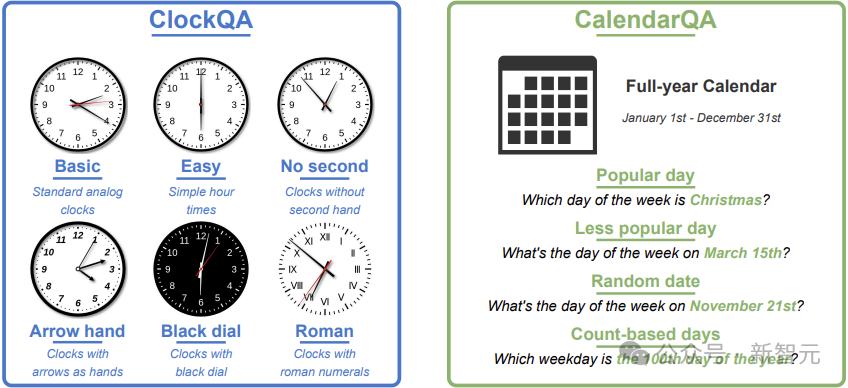
图2:DateTimeReasoning任务概览及其两个主要子集:ClockQA和CalendarQA
虽然数据集规模较小,但它的设计能有效探测时间推理、视觉解析和日期/时间推断的核心维度。
初步发现表明:尽管某些模型在时钟读时或日历问答中展现潜力,但根本问题依然存在。
其中,在时钟读时中,Gemini-2.0的时分针误差较低;在日历问答中,o1模型的准确率最高。

详细结果
表1总结了各模型在两个任务中的表现。
在ClockQA任务中,Gemini-2.0取得了最高的精确匹配(Exact Match, EM)分数(22.58%)和最小的小时/分钟误差,显示出其在理解时钟方面相较其他模型更具优势。
然而,整体的EM分数仍然偏低,说明多模态大语言模型(MLLMs)在读表任务上依旧存在明显困难。
相比之下,GPT-o1在CalendarQA任务中表现突出,准确率达到80%,展现出其在日期运算和逻辑推理方面的强大能力。其他模型则明显落后,表明日期计算和结构化布局解析仍然是AI面临的难点。
整体而言,除了GPT-o1在CalendarQA中的高表现外,其余模型在ClockQA和CalendarQA两个任务中的总体表现都不理想。
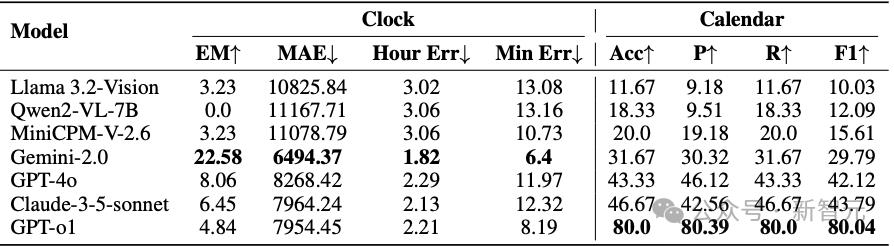
表1:各模型在时钟任务(左)和日历任务(右)中的表现。↑表示数值越高越好;↓表示数值越低越好
钟表读时任务仍容易出错。
在ClockQA子集中,模型的表现明显不如日历类问题(见表1)。
图4a和图3a显示,即使是在标准表盘下,模型的表现仍较差,有些模型甚至倾向于给出某个「默认」时间。
使用罗马数字或风格化的指针会进一步增加错误率。
而去掉秒针后,并没有简化模型的推理过程,说明模型在识别指针和理解角度方面存在根本性的问题。
日历推理分析稍好。
与之相比,部分模型在日历类任务和某些题型上表现更佳。
GPT-o1在CalendarQA子集中表现尤为突出,总体准确率高达80%(见表1和图3b)。
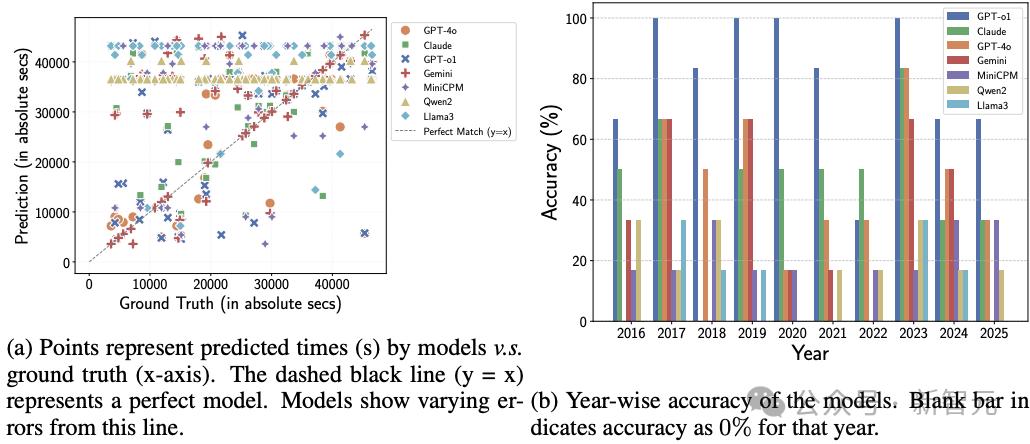
图3:ClockQA与CalendarQA的错误分析
图3(a)中的点表示模型预测的时间(纵轴)与真实时间(横轴)之间的关系。黑色虚线(y=x)代表理想情况下模型预测完全正确的情况。
图3(b)展示了各模型按年份的准确率表现。空白柱表示该模型在对应年份的准确率为0%。
像GPT-o1和Claude-3.5等闭源模型,在处理常见节假日的问题上优于开源模型。
这可能是因为训练数据中包含了这些节日的记忆模式(见图4b)。
然而,对于一些不太知名或需要复杂计算的问题(例如「第153天」),模型的准确率大幅下降,这说明偏移类推理能力难以迁移。
在这类问题上的表现,小型或开源模型(如MiniCPM、Qwen2-VL-7B和Llama3.2-Vision)几乎是随机的,这一点尤为明显。
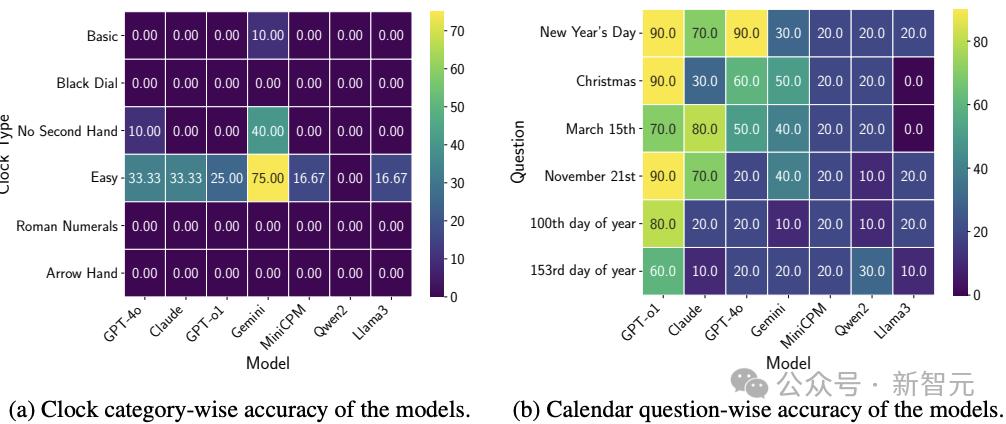
图4:基于问题类型与类别的ClockQA及CalendarQA分析
研究还揭示了另一个问题:当AI在训练时接触到的数据有限,特别是面对像闰年或复杂日历计算这样的少见现象时,它的表现就会明显下滑。
尽管大语言模型(LLM)在训练中接触过大量关于「闰年」概念的解释,但这并不意味着它们能够完成涉及视觉判断的相关任务所需的推理。
这项研究强调了两个方面的改进需求:
一是需要在训练数据中加入更多有针对性的示例;
二是需要重新思考AI如何处理逻辑推理与空间感知相结合的任务,尤其是那些它们平时接触不多的任务。
尽信AI,不如无AI
AI系统正确读取时钟的准确率仅为38.7%,判断日历日期的准确率则只有26.3%。
早期的系统通过标注样本进行训练,但读取时钟需要的是另一种能力——空间推理。
这可能是AI这次表现不佳的原因,论文作者、爱丁堡大学研究人员Rohit Saxena解释道:
模型必须识别指针重叠、测量角度,还要适应各种不同的表盘设计,比如罗马数字或艺术化的刻度。
AI要认出「这是个钟表」相对容易,但真正读出时间就难多了。

日期判断同样令人头疼。
当被问到日期推理问题时,AI的错误率也很高。比如, 「今年的第153天是星期几?」这类问题。
这个缺陷也令人意外,因为算术本应是计算机的基本能力之一。
但正如Saxena所解释的那样,AI处理算术的方式和传统计算机不同:
算术对传统计算机来说很简单,但对大语言模型就不是这样了。AI并不是运行数学算法,而是根据训练数据中学到的模式来预测答案。
所以它有时可以答对算术问题,但推理过程既不一致也不基于规则,而我们的研究正是揭示了这个差距。
这项研究是近年来不断增长的一个研究方向的一部分,聚焦于AI的「理解」方式与人类理解方式之间的差异。
AI模型是通过识别熟悉的模式来得出答案的,当训练数据中有足够的示例时,它们表现优秀,但在需要泛化或进行抽象推理时就会失败。
最重要的是,研究再次提醒我们,过度依赖AI的输出可能带来风险。
Saxena表示:「AI的确很强大,但当任务既涉及感知又需要精确推理时,我们仍然需要进行严格测试、设置备用逻辑,很多情况下还必须有人类介入。」

另一名作者、爱丁堡大学博士生Aryo Pradipta Gema,则表示如今的AI研究往往强调复杂的推理任务,但具有讽刺意味的是,很多系统在应对更简单的日常任务时仍显吃力。
我们的研究发现表明,现在已经到了必须解决这些基础能力缺陷的时候了。否则,AI在那些对时间敏感的现实应用中,可能始终难以真正落地。
参考资料:
https://www.livescience.com/technology/artificial-intelligence/ai-models-cant-tell-time-or-read-a-calendar-study-reveals
https://arxiv.org/abs/2502.05092
https://www.ed.ac.uk/news/most-ai-struggles-to-read-clocks-and-calendars
