

神译局是36氪旗下编译团队,关注科技、商业、职场、生活等领域,重点介绍国外的新技术、新观点、新风向。
编者按:资深AI实践者以亲历百小时开发为据,揭示AGI落地最大瓶颈——模型缺乏人类的那种持续学习的能力。作者通过深度剖析“学萨克斯”的悖论与数据天花板,预言短期变革有限,但十年内智能爆发的概率陡增,为狂热讨论注入一股冷静思考。文章来自编译。
“事情的发生总比你预想的慢,而后又比你想象的要快。” ——鲁迪格·多恩布什(Rudiger Dornbusch)
在我的播客里,关于通用人工智能(AGI)何时实现的时间表争论从未停止。
有嘉宾认为还需20年,也有坚信只需2年。
以下是2025年6月的时候我的思考脉络。
持续学习的困境
常有人说:即便AI发展完全停滞,现有系统对经济的变革力仍远超互联网。
我对此存疑。
当今大语言模型(LLM)确实神奇,但财富500强企业未用它改造工作流,绝非管理层守旧—— 根本问题在于,人类级别的常规劳动输出本就难以实现。 这涉及模型底层能力的缺失。
自认是“AI先锋派”的我,投入超百小时构建LLM小工具。实操体验反而让我调长了预期时间线。我尝试让LLM像人类那样重写机器转录稿提升可读性, 或从访谈中摘取推特素材, 又或是逐段协作撰写文章。这些短周期、语言输入输出的封闭任务,本该是LLM的核心能力范围。实际表现却仅勉强及格(5/10)——当然,这已足够惊艳。
核心症结在于:LLM无法像人类那样持续进步。缺乏持续学习能力是致命伤。虽然多数任务大模型的基线水平已超普通人,但想让模型给出高水平反馈却没门。模型开箱即用的能力就是天花板,纵使反复调试系统提示词,实际效果也远比不上人类员工积累的经验成长。
人类价值的核心并非原始智力,而是构建语境、反思失误、在实操中持续优化细节的能力。
想象一下教孩子吹萨克斯:让她试吹→辨音→调整。 若换成这种模式:学生首次尝试出错,你会立即打断,写下详细错误分析;下个学生阅读笔记后直接挑战查理·帕克曲目;失败后再优化笔记,教给给第三位学生。
这样注定是行不通的。 再精妙的提示词,也没法让人光靠文字说明学会萨克斯—— 而这就是我们“教导”LLM的唯一途径。
是,是有强化学习微调(RL fine-tuning)这样的东西,却LLM缺乏人类学习的主动适应性。我的编辑之所以出色,正因他们在工作中能自主发现细节:思考观众偏好、洞察我的兴奋点、优化日常流程。如果每项子任务都需定制强化学习环境,根本不可能达成这种成长。
或许未来会有更聪明的模型自建强化学习闭环: 我给出高阶反馈,模型自动生成可验证的训练问题,甚至搭建演练环境弥补短板。 但这个的实现难度极大,且技术泛化性存疑。虽然终有一天模型能像人类一样在工作中自然学习,但未来几年内,我看不出将在线持续学习嵌入现有LLM架构的清晰路径。
LLM在单次对话中确能展现灵光。比如合写文章时,前四段建议都很糟糕。当我亲自重写并直言“你写得烂透了,看我的版本”,它后续建议反而变好了。但这种对偏好的微妙理解,会话结束后即刻就归零了。
表面解决方案或许是长上下文窗口(如Claude Code每30分钟将记忆压缩为摘要)。但在软件工程之外,将丰富经验浓缩为文本概要注定脆弱——试想用文字总结教人吹萨克斯?即便Claude Code也常在压缩后丢弃来之不易的优化方案,只因摘要未能保留关键决策逻辑。
因此我反对播客嘉宾肖托(Sholto)与特伦顿(Trenton)的断言(引自特伦顿):
即便AI停滞不前且缺乏通用智能,其经济价值仍巨大。白领工作数据极易采集,未来五年必将全面自动化。
如果AI今天发展停滞的话,我认为不到25%的白领岗位会被取代。固然许多任务可自动化(如Claude 4 Opus确实能重写转录稿),但因模型无法持续学习适应我的偏好,还是会选择雇佣人类。没有持续学习的突破,采集再多数据也难改现状:AI或可勉强处理子任务,但上下文构建的缺失导致AI永远无法成为真正的“员工”。
这让我对近期变革性AI持悲观态度,却对十年之后格外乐观。一旦突破持续学习,模型价值将现断层式跃升。即便没有纯粹的“软件奇点”(模型自主迭代出更智能后代),仍可能爆发广泛部署的智能革命:AI渗透各经济领域,像人类般在工作中学习。更可怕的是——它们能整合所有副本的学习成果,相当于单个AI同步学习全球所有岗位。具备在线学习能力的AI,无需算法突破即可迅速蜕变为超级智能。
不过我并不指望某天打开OpenAI直播后,听到“持续学习已彻底攻克”的消息。实验室有快速发布创新的动机,人类必将先迎来残缺的早期版本(或称测试期训练),而后才获得真正类人的学习能力。在这个巨大瓶颈突破前,我们有充足时间做好准备。
计算机操作能力
在我采访Anthropic研究员肖托·道格拉斯和特伦顿·布里克顿时,他们预言明年末将出现可靠的计算机操作智能体。
现在虽然也有计算机操作智能体,但表现糟糕。他们设想的是截然不同的存在。到明年年底,你只需对AI说“去帮我报税”,它就会自动完成——翻遍你的邮件、亚马逊订单和Slack记录,向供应商追索发票,整理所有收据,区分业务支出,对模糊地带寻求你的确认,最终向国税局提交1040表格。
我对此存疑。我虽不是AI研究员不敢妄论技术细节,但基于现有认知,质疑理由如下:
随着任务时长增加,执行链必然延长。AI需完成两小时的计算机操作才能验证结果正确性,这还没算上处理图像视频的额外算力消耗。进度放缓几乎不可避免。
关于计算机操作的多模态数据的先天不足。Mechanize关于自动化软件工程的精辟论述我很喜欢:“过去十年的模型扩展得益于海量免费互联网文本数据,但这只解决了自然语言处理的问题。想训练出可靠的操作智能体?想象用1980年的文本数据训练GPT-4——就算有算力也白搭。”
或许纯文本训练已让模型理解UI逻辑?也许强化学习微调(RL fine-tuning)能突破数据限制?但我还没见任何证据表明模型数据饥渴症已得到缓解,尤其在它们本就不熟练的领域。
还有一种可能:模型作为前端编码高手,能自创百万模拟UI进行练习?我的看法见下一条。
DeepSeek在R1论文中描述的强化学习流程看似简单,但从GPT-4发布到o1问世却用了两年。当然,说R1/o1研发简单是荒唐的——这背后是海量工程调试与方案筛选。但这恰恰印证我的观点:连“训练模型解决可验证的数学编码题”这种“简单”构想都耗时如此之久,面对数据更匮乏、模态完全不同的计算机操作难题,我们显然低估了破局的难度。
推理
先别急着泼冷水。我可不愿像Hackernews上那群被宠坏的孩子,就算得到下金蛋的鹅,也只会抱怨鹅叫太吵。
读过o3或Gemini 2.5的思考轨迹吗?它们确实在推理!拆解问题→揣摩用户需求→审视内心独白→发现方向错误立即调整。而我们竟习以为常:“机器当然会思考推演给出聪明答案,这不就是机器的本职?”
部分人过度悲观,只因未接触顶尖模型在其擅长领域的表现。给Claude Code模糊需求,十分钟后它直接零样本生成可用程序——这种震撼体验让人不禁怀疑:“它竟真的做到了?”你可以大谈电路图、训练分布或强化学习,但最直白的解释只能是:婴儿级通用智能已然觉醒。此刻你心底必然有个声音在说:“成了,我们真的造出了智能机器。”
我的预测
概率分布极广(这恰是我坚信概率论的原因)。即便为2028年错位的超级智能(ASI)做准备也完全合理——这结果绝非天方夜谭。
以下是我愿押注五五开的时间点:
2028年
AI能像称职的总经理那样,一周内搞定我的小企业税务:翻遍各类网站找票据,补全遗漏单据,邮件追讨发票,填表提交国税局全套流程。
当前计算机操作能力相当于GPT-2阶段:缺乏预训练数据,模型要用陌生操作指令在长周期内优化稀疏奖励。但基础模型够聪明,或许自带计算机操作潜质,加上如今全球算力与研究员数量激增,可能追平进度。小企业报税对计算机操作的里程碑意义,堪比GPT-4之于语言模型。而从GPT-2到GPT-4正好走了四年。
(注:2026-2027年必有惊艳demo问世,就像当年GPT-3般炫酷却不实用。但它们无力处理涉及计算机操作、长达一周的复杂端到端项目。)
2032年
AI在职学习能力媲美人类白领:若雇佣AI视频剪辑师,半年后它就能像人类同事那样,深刻理解我的偏好、频道调性、观众喜好等可操作知识。
尽管现有模型难嵌持续学习模块,但七年足够漫长!七年前GPT-1才刚刚面世。未来七年找到模型在职学习方案绝非痴人说梦。
你或许会问:“刚才还强调持续学习是致命短板,转眼预言七年后智能爆发大普及?”没错,我确实预见了短期内剧变的世界。
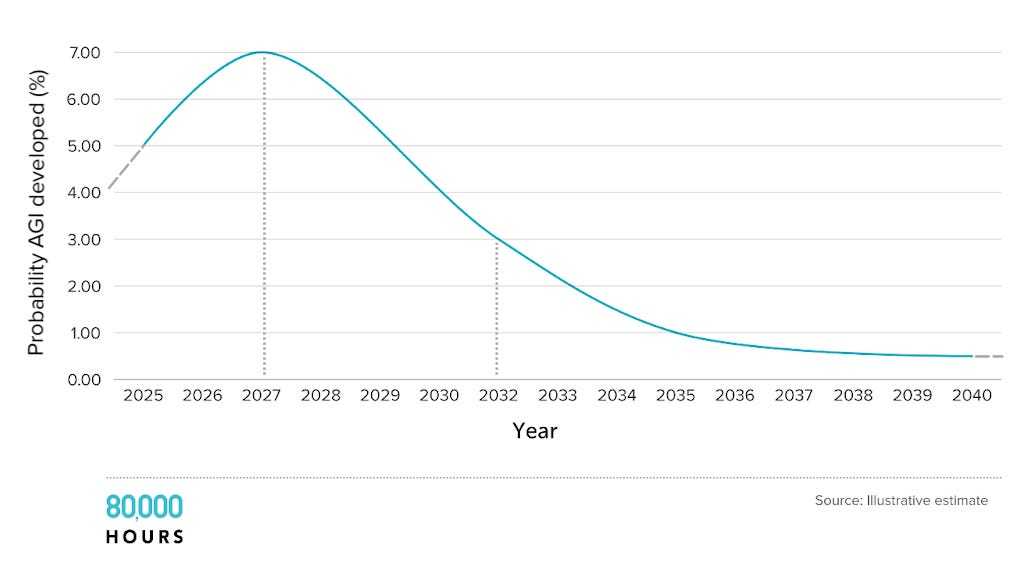
AGI时间线预测
成败尽在本十年。(严格说是逐年边际概率递减,但“不成功便成仁”更顺口)。过去十年AI进步依赖前沿系统训练算力年增四倍——无论芯片、电力还是训练消耗GDP占比,这种增长本十年后必然终止。2030年后,AI进展只能靠算法突破,而深度学习范式的低垂果实终将被摘尽,AGI年现概率将直线下跌。
这意味着:如果现实走向我预测中较长的时间线,2030甚至2040年代世界仍将大体如常;但只要偏离这条路径,即便清醒认知AI当前局限,我们也该准备好迎接真正疯狂的时代。
译者:boxi。
