

IT之家 12 月 8 日消息,智谱 AI 今日官宣发布并开源 GLM-4.6V 系列多模态大模型,包括:
GLM-4.6V(106B-A12B):面向云端与高性能集群场景的基础版;
GLM-4.6V-Flash(9B):面向本地部署与低延迟应用的轻量版。

作为 GLM 系列在多模态方向上的一次重要迭代,GLM-4.6V 将训练时上下文窗口提升到 128k tokens,在视觉理解精度上达到同参数规模 SOTA,并首次在模型架构中将 Function Call(工具调用)能力原生融入视觉模型,打通从「视觉感知」到「可执行行动(Action)」的链路,为真实业务场景中的多模态 Agent 提供统一的技术底座。
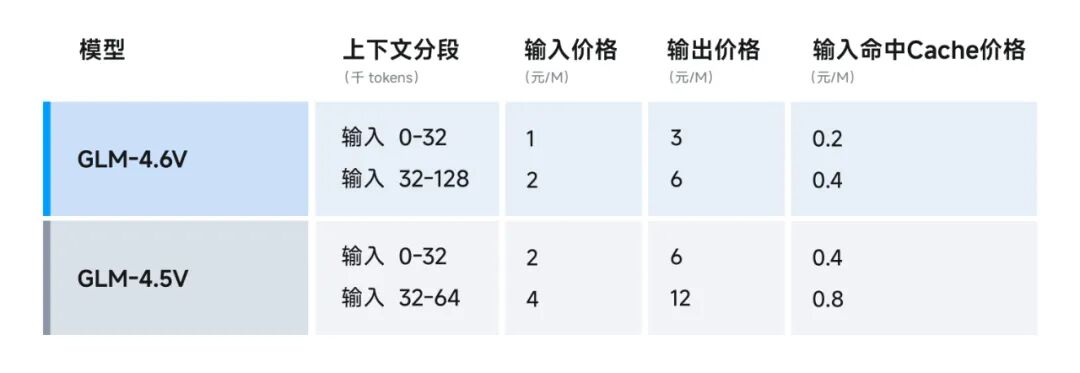
在性能优化之外,GLM-4.6V 系列相较于 GLM-4.5V 降价 50%,API 调用价格低至输入 1 元 / 百万 tokens,输出 3 元 / 百万 tokens。
同时,GLM-4.6V-Flash 免费开放使用。
GLM-4.6V 即日起融入 GLM Coding Plan,针对用户 8 大类场景定向开发了专用 MCP 工具,模型可自主调用最匹配的接口。
智谱 AI 介绍称,传统工具调用大多基于纯文本,在面对图像、视频、复杂文档等多模态内容时,需要多次中间转换,带来信息损失和工程复杂度。GLM-4.6V 从设计之初就围绕「图像即参数,结果即上下文」,构建了原生多模态工具调用能力:
输入多模态:图像、截图、文档页面等可以直接作为工具参数,无需先转为文字描述再解析,减少链路损耗。
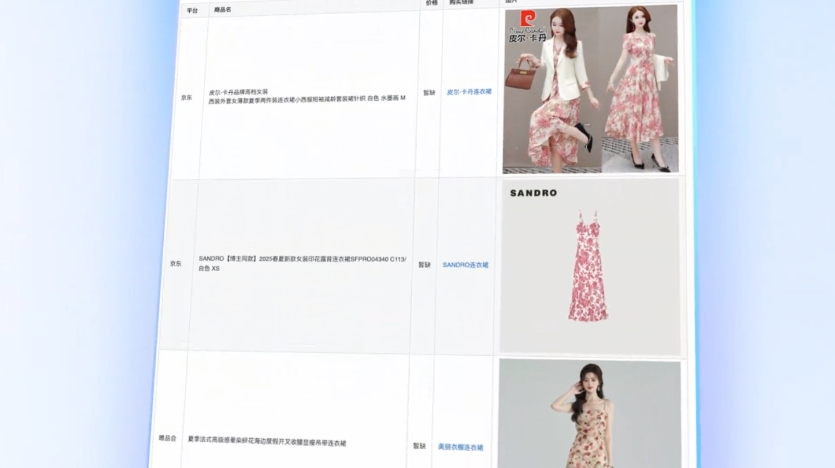
输出多模态:对于工具返回的统计图表、渲染后网页截图、检索到的商品图片等结果,模型能够再次进行视觉理解,将其纳入后续推理链路。
模型原生支持基于视觉输入的工具调用,完整打通从感知到理解到执行的闭环。这使得 GLM-4.6V 能够应对图文混排输出、商品识别与好价推荐、以及辅助型 Agent 场景等更复杂的视觉任务。
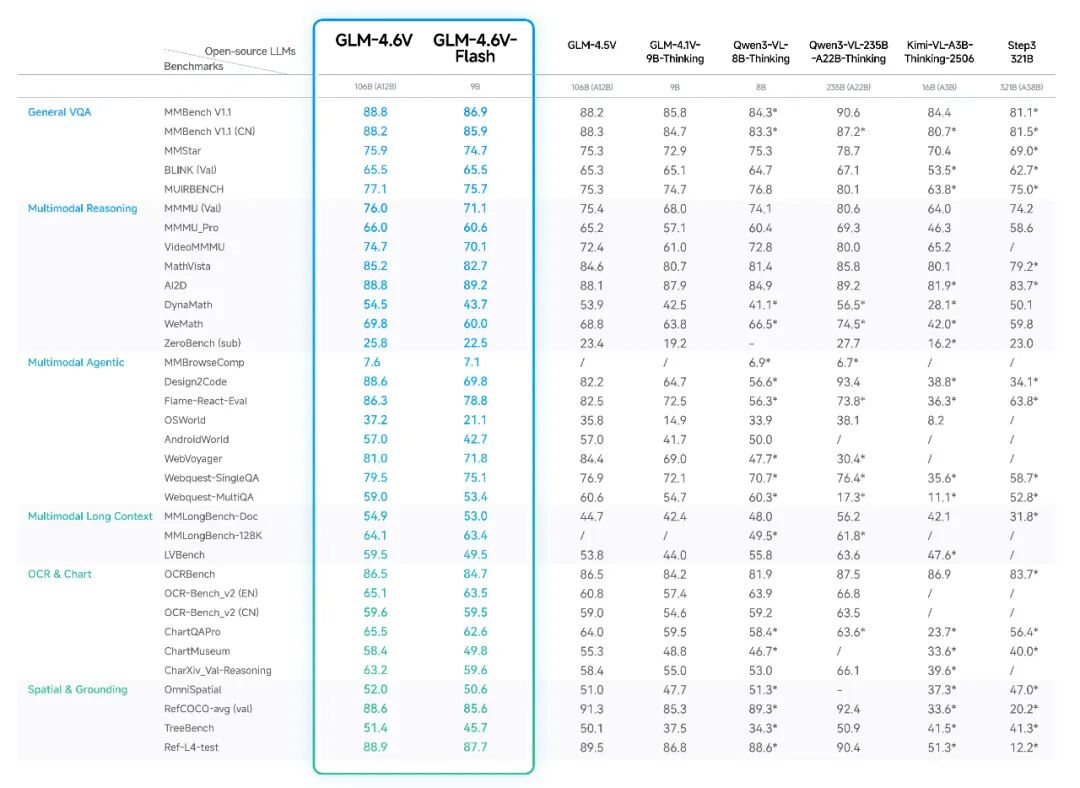
GLM-4.6V 在 MMBench、MathVista、OCRBench 等 30+ 主流多模态评测基准上进行了验证,较上一代模型取得显著提升。在同等参数规模下,模型在多模态交互、逻辑推理和长上下文等关键能力上取得 SOTA 表现。其中,9B 版本的 GLM-4.6V-Flash 整体表现超过 Qwen3-VL-8B,106B 参数 12B 激活的 GLM-4.6V 表现比肩 2 倍参数量的 Qwen3-VL-235B。
智谱 AI 开放了 GLM-4.6V 的模型权重、推理代码与示例工程,IT之家附开源地址如下:
GitHub:https://github.com/zai-org/GLM-V
Hugging Face:https://huggingface.co/collections/zai-org/glm-46v
魔搭社区:https://modelscope.cn/collections/GLM-46V-37fabc27818446
