

近期,一个80亿参数的「小模型」引发AI圈热议。
这个名为Rnj-1的开源模型,由Ashish Vaswani与Niki Parmar创办的Essential AI Labs推出。
他们是2017年那篇著名论文《注意力就是你所需要的一切》(Attention is All You Need)作者中的两位。

以上八位作者同等贡献 ,其中Ashish与Illia共同设计并实现了首个Transformer 模型,并深度参与了全部研究工作。

Ashish Vaswani
Niki在研究的早期阶段负责设计、实现、调优并评估了大量模型变体,是模型架构探索与实验验证的核心贡献者之一。

Niki Parmar
ChatGPT、Gemini、Claude、Llama……几乎所有我们熟知的大模型都采用了Transformer框架。
这些早期玩家们在几年后将整个行业引向了比拼参数规模的AI军备竞赛。
前不久,Google DeepMind CEO哈萨比斯(Demis Hassabis)还断言,要实现通用人工智能(AGI),当下主流大模型必须把「扩规模」这件事推到极致。
他所指的「扩规模」是更多数据、更多算力、更大的模型,并强调它「至少是通往 AGI 的关键组件,甚至可能就是全部路径」。
哈萨比斯的观点,在一定程度上代表了大模型领域由Transformer和Scaling Law所催生的「模型越大越强」的主流观点。
7年后,同为Transformer论文的作者,Ashish Vaswani和Niki Parmar开始向这一主流观点发起了挑战:
模型不一定越大就越聪明。
至少从算力效率的角度来看,就像上面这位网友说的那样:
「大模型时代已经结束,真正懂行的人打造的小模型时代开始了。」
在ChatGPT、Gemini、Claude之外,以Rnj-1为代表的小模型开辟了另一种思路。
Vaswani的担忧与Rnj-1的诞生
过去几年,砸向AI领域的钱越来越多、模型越来越大、训练越来越昂贵。
Vaswani认为,AI领域巨额资金的涌入可能会妨碍技术本身的发展,因为以利润为导向的企业逐渐从科学家和学者手中夺取了主导权:
「少数公司掌控着先进AI技术的生产、节奏和方向。他们决定了AI的演化方式,也决定了谁能从中受益……我们不能让封闭式的AI开发阻碍我们探索新的前沿。」
Vaswani和Parmar希望推动构建一个健康、开放的生态,而不是封闭的塔尖。
Essential AI Labs以及它的首款开源模型Rnj-1正是在这种理念下诞生的。

Essential AI将构建前沿开源平台和智能工具作为自己的使命。
Rnj-1的名称,则是来自著名数学家拉马努金(Srinivasa Ramanujan)。
据Essential AI官方介绍,这款从零开始训练的80亿参数模型,在代码、数学与「智能体」推理上可「对齐前沿」水平,还可以在消费级GPU上运行,自由使用与修改。
一把「瑞士军刀」式的小模型
和动辄万亿参数的前沿大模型相比,Rnj-1并不起眼。
它只是一个80亿参数的小模型,仅仅32k的上下文长度,遵循开源Gemma 3架构。
既然不能和比别人比「身板」,就要拼技术。
Rnj-1采用全局自注意力机制(global self-attention)和YaRN技术。
global self-attention好比为模型配备了一双「全景眼睛」,无论给它多长的输入,都能一次全部看清。
而YaRN则像是「长距离阅读辅助器」,让模型能在32k上下文中仍然保持清晰思考。
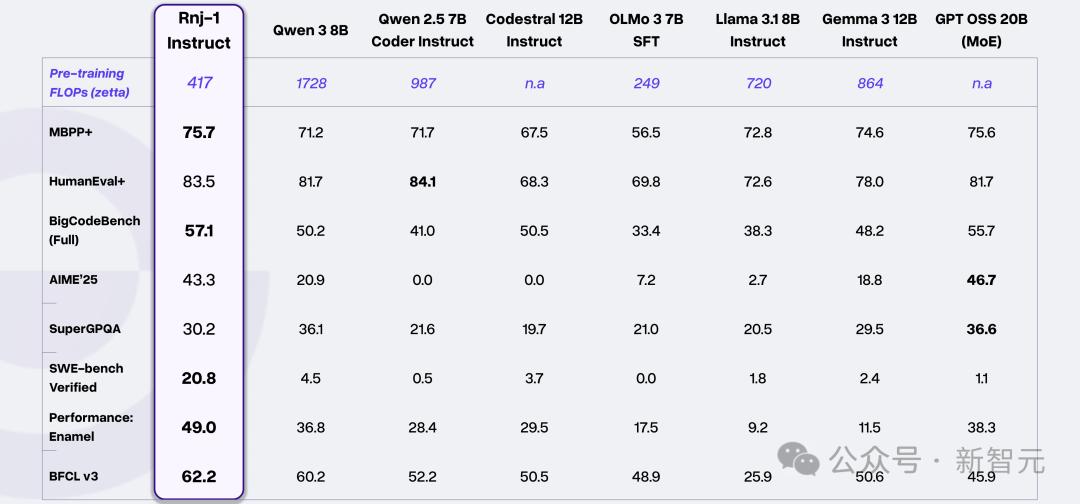
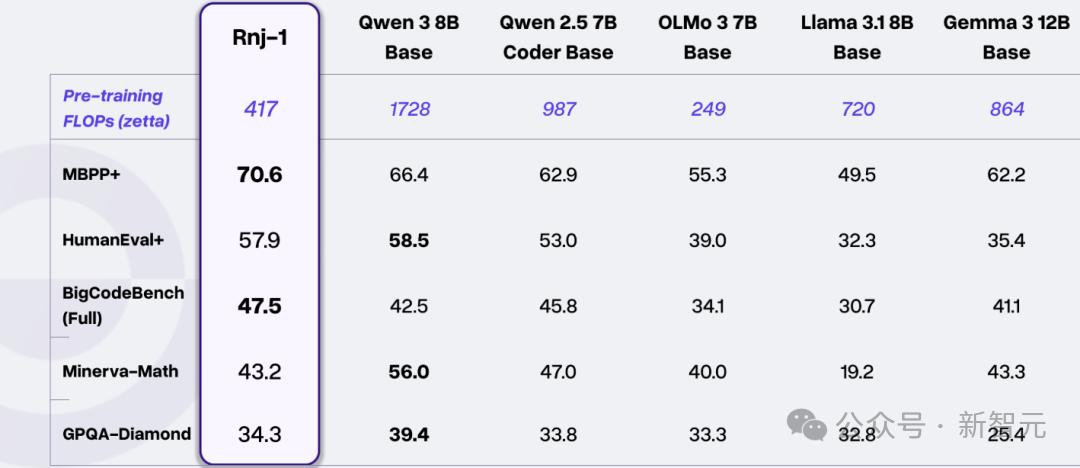
Rnj-1的基础版与指令版在同尺寸开源模型中表现十分亮眼。
代码生成
在HumanEval+、MBPP+ 等算法类代码任务,以及BigCodeBench这类更广泛的编程任务中,Rnj-1 Base与Instruct的表现能与最强同规模开源模型竞争,有时甚至超越更大的GPT OSS 20B。
智能体能力
Rnj-1 Instruct是Rnj-1重点打造的能力之一, 在智能体式编码任务中表现尤为突出。
在SWE-bench 上,Rnj-1 Instruct的表现比同尺寸模型强出近一个数量级,已接近大规模模型的水平。
它会用 profiler(性能分析器)检查瓶颈,然后主动提出优化方案,甚至多轮迭代。
例如在Enamel这一考察高效算法实现的任务中,Rnj-1 Instruct 超过了强力基线。
在伯克利函数调用排行榜(BFCL)中,Rnj-1 Instruct的工具使用能力也领先同类模型。
数学与科学推理
在AIME'25(高难度高中数学)中,Rnj-1 Instruct的数学能力可与最强开源模型匹敌。
Rnj-1 Base在Minerva-MATH上也与同规模模型保持一致。
在GPQA-Diamond(包含生物、物理、化学的高难度题目)上,Rnj-1的表现也接近同尺寸模型中的领先水平。
量化稳定,不掉质量
Rnj-1对量化也非常稳健。
这意味着它能在更便宜、更省电的显卡上跑得很快,模型质量几乎不受影响,真正实现人人可用。
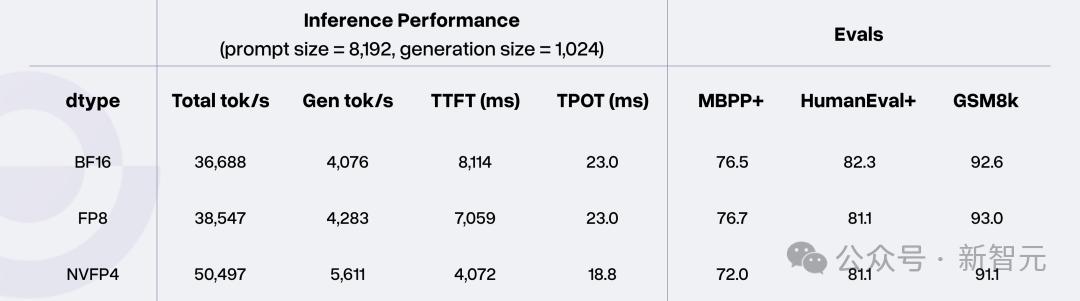
从BF16到FP8再到NVFP4,在显著提升提示密集型工作负载的token吞吐量的同时,模型质量几乎不受影响。
Token吞吐量数据基于NVIDIA B200 GPU测得,其中KV Cache的数据类型设为FP8,批大小为128。
回到起点,不想再做「宇宙巨兽」了
今年2月,Essential AI做了一个重要的决定:
专注于基础能力的本身。
在做研究和做产品两者之间,Essential AI更倾向于提升模型能力。
DeepSeek R1发布后,世界都在讨论RL的强大,但Vaswani认为,压缩是模拟智能的核心要素,而语言模型的预测式预训练才是更合理的路径。
Essential AI在早期预训练阶段便观察到模型出现反思与探索式推理的迹象,这印证了「强预训练是下游成功基础」的判断。
他们认为强大的预训练本身就会产生推理能力,而不是靠后期堆RL补课。
这是Essential AI迄今为止第一个也是最具根本性的抉择。
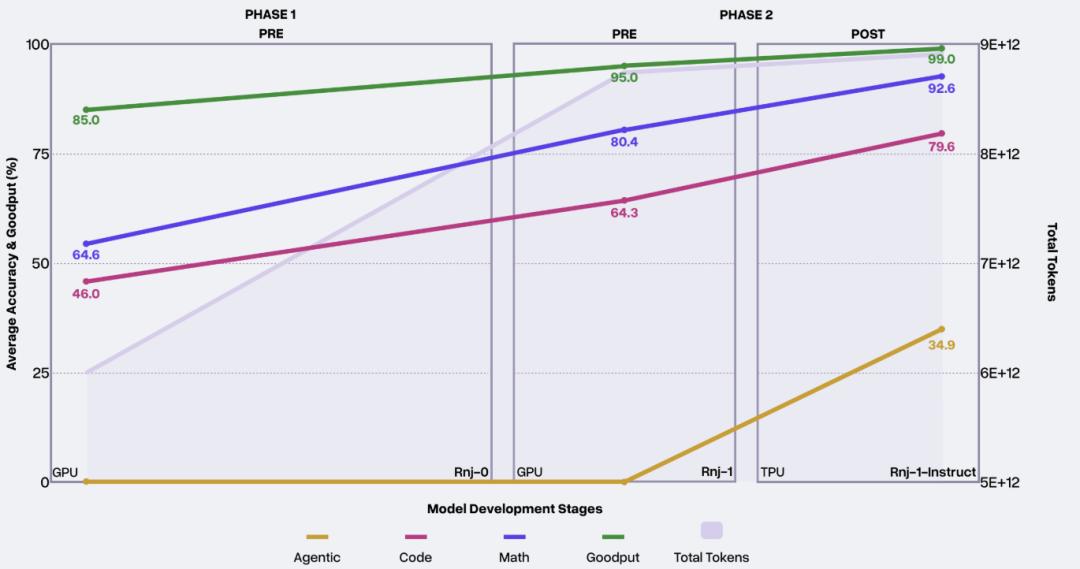
上图记录了Essential AI在每个阶段所取得的进展。
Rnj-1是Essential AI从头开始训练的大模型。
他们希望大模型在学习阶段不仅是「看很多数据」,而是能自己把数据分类、转换、混合,形成更好的理解方式。
这样模型的「可测能力」(比如数学、代码、科学等可验证任务)会更强。
研究团队通过数据分类研究,得到了一种新的「带重复惩罚的数据分布聚类与混合方法」,这种方法尤其提升了模型在STEM(科学、技术、工程、数学)方面的能力。
此外,训练模型需要「优化器」来调整参数。
Essential AI证明了Muon优化器相较AdamW更高效, 并开发了适配大模型的分片策略。
Essential AI的研究人员认为,大模型应该不仅能理解代码,更应该模拟程序在不同环境中的执行行为,Rnj-1在这一方向上进行了大规模尝试。
为了让基础模型学会自动「改进代码」,研究人员还投入研究「代码演化」的建模。
这些方向均在小模型上通过验证,显著提升了Rnj-1的工程能力。
在预训练末期,Essential AI团队确信Rnj-1已具备数学、编程与科学知识等潜在能力。
接下来的问题是如何通过适量监督微调,唤醒其指令遵循与复杂推理能力,并验证其在长对话与现实难题中的表现。
Essential AI在后训练方案上借鉴了YaRN长上下文中期训练、Nemotron以及简单智能体环境。
其后训练主要有三项任务:
研究定向数据对推理与智能体能力的影响;
团队亲自「上手体验」模型,观察质变;
收集下游反馈,为下一轮预训练下注提供依据
Vaswani认为,有许多令人难以抗拒的想法正在争夺研究团队的注意力。
比如,他们对条件计算、扩展并增强模型处理更长上下文的能力,以及低精度训练充满热情。
在中期内,Essential AI将继续推进压缩这一核心理念,拓展计划模拟的程序行为的类型和范围,并推动代码演化。
Vaswani预计,诸如将强化学习等扩展性思路用于培养复杂推理能力的方法,将很快出现在Essential AI的路线图上。
在官方博客中,Vaswani用先驱计算机科学家Alan Perlis的话表达了自己的心声:
我认为,在计算机科学领域,我们必须始终让计算保持趣味性,这一点极其重要……
我认为,我们有责任不断拓展计算机的边界,引领它们走向新的方向,并让这种乐趣持续存在……
最重要的是,我希望我们不要变成传教士。不要觉得自己像个推销圣 经的推销员。这世上那样的人已经太多了。你所了解的计算知识,别人终会学到。不要觉得成功计算的钥匙只掌握在你手中。
我相信并希望,你手中握有的是智慧:一种能够超越最初接触机器时的认知,看到它更多可能性,并让它变得更强的能力。
开源平台Essential AI的创建,以及此次Rnj-1的推出,旨在推动美国AI开源领域的发展,抢夺在轻量化开源生态话语权,目前这一领域正由中国企业主导。
开源生态,将推动大模型在「越大越好」行业竞争格局之外,探索开放、轻量化的新路径,加速AI人人可用时代的到来。
参考资料:
https://www.bloomberg.com/news/articles/2025-12-08/transformer-paper-authors-at-ai-startup-debut-open-source-model?srnd=phx-ai%20
https://www.essential.ai/research/rnj-1
