12月19日,“AI独角兽”北京智谱华章科技股份有限公司12月19日通过聆讯并公布了IPO招股书等资料。紧随其后,12月21日MiniMax也通过港交所聆讯,并披露招股书。
智谱、MiniMax(稀宇科技)是业界所谓“大模型六小龙”中的两员,其余四家公司为月之暗面、阶跃星辰、百川智能和零一万物,这些公司聚焦基础大模型研发,是中国AI初创企业的第一梯队的代表。

值得注意的是,智谱、MiniMax的上市步伐在OpenAI、Anthropic等海外大模型明星企业之前。智谱与MiniMax也将争夺“全球大模型第一股”。
智谱、MiniMax此番上市,可以说是一次具有行业破冰意义的关键跨越,它试图为大模型赛道搭建起“技术研发-资本融资-商业变现”的闭环。这一动作对资本市场的价值尤为特殊,这是市场首次对纯大模型企业进行价值锚定,其估值范式或将成为后来者的重要标尺。
而在全球AI博弈的视角下,中国大模型企业率先登陆资本市场,更意味着中美AI竞赛已突破技术层面的角力,迈入资本维度深度角逐的新阶段。
01
颇具竞争力的产品
根据公开信息,北京智谱华章科技股份有限公司成立于2019年,秉承着在中国追求通用人工智能(AGI)创新的大胆理念而创立,系由清华大学计算机系知识工程实验室成果转化而来的人工智能企业,专注认知智能大模型研发,为北京市“专精特新”中小企业和人工智能芯片标准化创新合作伙伴。
智谱公布的招股书显示,2021年,智谱发布了中国首个专有预训练大模型框架GLM框架,并推出了模型即服务(MaaS)产品开发及商业化平台,透过该平台提供大模型服务。2022年,智谱开源首个1000亿规模的模型(GLM-130B)。智谱运营于大语言模型(LLM)市场,其为更广泛AI市场的一个细分领域。
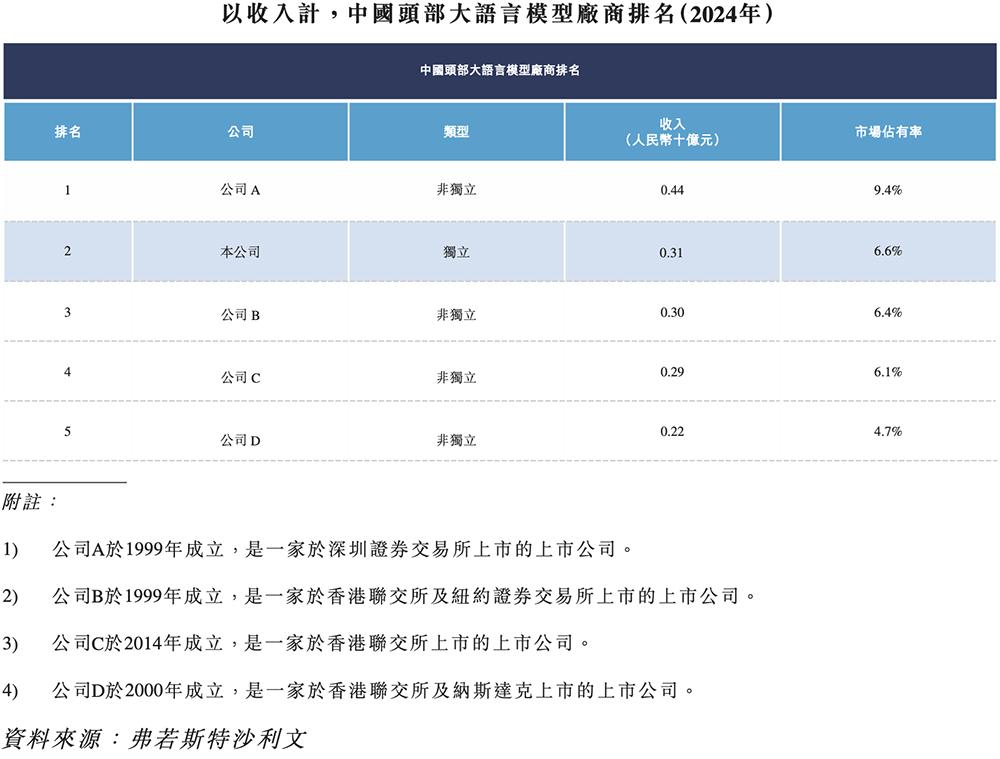
智谱为机构客户(包括私营企业及公共行业实体)及个人用户(包括个人终端用户及独立开发者)提供通用大模型服务。截至2025年6月30日,智谱的模型已为逾八千家机构客户提供支持,截至最后实际可行日期,已为约80百万台设备提供支持。
智谱公布的数据显示,截至2025年9月30日止9个月,智谱拥有超过12000名机构客户,较截至2025年6月30日止6个月大幅增加。此外,2025年11月,智谱的日均token消耗量为4.2万亿。
从发展阶段来看,智谱在招股书中称,公司已根据大语言模型的五个阶段,在前三个阶段中开发出了大模型及智能体。
此次募集资金用途方面,约70%将用于持续增强公司在通用AI大模型方面的研发能力;约10%将用于通过提供最新的基座模型以及训练╱推理工具及基础设施持续优化公司的MaaS平台;约10%将用于发展业务合作伙伴网络以及进行战略投资;约10%将用于营运资金及其他一般企业用途。
值得注意的是,公司产品近来不断迭代。2025年7月及8月,智谱发布GLM-4.5、GLM-4.5V及AutoGLM升级版本。GLM-4.5为旗舰基座模型。通过多阶段训练并结合微调与强化学习的全方位后训练,GLM-4.5在智能体、推理及编码任务上均展现出卓越性能。GLM-4.5V是视觉语言基座模型(VLM),专为通用视觉理解及推理任务而设计,可自主执行多类高度复杂的视觉理解及推理任务。AutoGLM升级版本由GLM-4.5及GLM-4.5V驱动,并能够在更广泛的移动应用程序及网站中模拟人类操作行为,可在云端自主完成指定任务,无需占用用户的手机或计算机,让用户可继续使用其设备而不会中断。
2025年9月,智谱发布GLM-4.6,GLM-4.6为基座模型的进一步升级版本,主要强化了编码能力。
12月23日,智谱AI正式上线并开源GLM-4.7模型。新版本主要针对编程场景进行优化,提升了代码生成、任务规划与工具调用能力。在多项主流公开基准测试中,GLM-4.7展现了具有竞争力的性能,部分指标超越了目前市场的领先模型。数据显示,在全球百万用户参与盲测的专业编码评估系统Code Arena中,GLM-4.7位列开源第一、国产第一,并超越了GPT-5.2。同时,该模型在SWE-bench-Verified和LiveCodeBench V6等测试中均取得了开源SOTA(当前最佳)分数,对齐Claude Sonnet 4.5。
02
持续亏损的业绩
从招股书公布的财务数据来看,近年来,智谱收入显著增长。2022年、2023年及2024年,智谱收入分别为57.4百万元、124.5百万元及312.4百万元,复合年增长率为130%以上。截至2025年6月30日止6个月,收入为190.9百万元。
根据弗若斯特沙利文的资料,按2024年的收入计,智谱在中国独立通用大模型开发商中位列第一,在所有通用大模型开发商中位列第二,市场份额为6.6%。
尽管业务实现持续增长,智谱净亏损却呈整体上升趋势。财务数据显示,2022年、2023年、2024年以及截至2025年6月30日止6个月分别录得年内亏损143.7百万元、788.0百万元、2958.0百万元及2357.9百万元。
从毛利率来看,2022年至2024年,智谱毛利率分别为54.6%、64.6%、56.3%,2025年上半年毛利率为50%。

对于亏损上升的原因,智谱解释称,主要由于随着公司业务扩张,扩大研发团队,并从第三方及相关计算硬件采购更多计算服务,导致研发开支大幅增加。另外,扩大销售及营销团队,并增加广告投资,以迅速把握新兴市场机遇,导致销售及营销开支增加。
智谱在招股书中表示,研发对公司业务及运营至关重要。公司一直在研发工作上投入大量资源,专注于提升基座模型的智能水平。2022年、2023年及2024年以及截至2024年及2025年6月30日止六个月,我们的研发开支分别为84.4百万元、528.9百万元、2195.4百万元及1594.7百万元,分别占各期间总收入的147.0%、424.7%、702.7%及835.4%。
人工智能行业面临快速技术变革,且在技术创新方面发展迅速。智谱表示,公司必须在研发方面投入大量资源以推动公司的技术发展、扩展产品范围,并确保公司的模型和解决方案保持创新性及竞争力。因此,公司未来可能继续产生巨额研发开支。
03
迅猛发展的市场
大模型市场正以前所未有的速度发展,并迅速重塑人类社会。近年来,特别是2022年以来,大语言模型的发展经历了巨大的飞跃。目前最前沿的研究主要在美国和中国开展,两国都涌现出了一批领军公司。
世界范围来看,全球大模型市场规模预计2030年将超过3000亿美元。IDC预计,到2030年人工智能将累计为全球经济贡献19.9万亿美元,并推动2030年全球GDP增长3.5%。

以收入计,2024年中国大语言模型市场规模已达到53亿元,其中机构客户贡献47亿元,个人客户贡献6亿元。随着大语言模型技术的不断进步以及机构与个人用户需求的不断增长,估计到2030年该市场规模将增至1011亿元,2024年至2030年的复合年增长率为63.5%。机构客户仍将是市场增长的核心驱动力,估计到2030年中国企业级大语言模型市场规模将达到904亿元,2024年至2030年的复合年增长率为63.7%。
中国大语言模型市场的参与者可分为独立提供商及非独立提供商。独立提供商从业务开展初期就具备大语言模型技术原生、大语言模型产品原生及大语言模型商业模式原生的特点;而非独立提供商则通常为涉足AI领域的科技巨头。智谱则为独立通用大模型厂商的一员。
与非独立提供商相比,独立提供商面临着非常不同的竞争动态。例如,非独立提供商利用其原有的多元化业务线,积累了庞大的用户群,这有利于其大语言模型产品的推广。然而,另一方面,如果科技巨头经营的业务线与客户自己的业务直接竞争,企业客户可能不愿意选择其提供的大语言模型产品。
04
高速演进的态势
AI在释放社会生产力的同时,也丰富了创造力。如今,AI已渗透到企业和个人生活的各个层面,从社交媒体内容推荐系统、chatbot、智能个人助理,到自动驾驶系统、智能风控模型、AI辅助诊断等,AI已成为推动社会与产业智能化转型的核心力量。
和前几代AI相比,过去三年的大模型是重要的技术范式变化,也是社会发展的必然需要。传统AI基于小模型,针对不同需求场景进行定制化训练。而目标是达到能够执行人类所有思维任务的智能水平。个人用户的需求是个性化且长尾的,亟待更为通用的AI技术。大模型的本质正是解决通用性问题,其具有扩展性和泛化能力,是通往该目标可能性最高的路径。
过去三年,大模型领域取得了飞跃式的发展。从模型规模和智能水平的大幅提升,到多模态能力的拓展,再到商业价值的释放,行业呈现出高速演进的态势。
2025年开始,头部大模型公司的模型更新频率也在加快,从2024年的四个月以上加速至三个月内,持续推动智能水平提升。例如,2024年,Anthropic于3月推出了Claude 3系列,随后推出Claude 3.5系列——包括分别于6月和10月推出的Sonnet和Haiku系列,共同构成对Claude 3家族的重大升级。2025年,Anthropic于2月推出Claude3.7 Sonnet,于三个月后的5月又推出Claude 4,于8月推出Opus 4.1,更新速度比2024年快了近50%。
另一个趋势是,开源正在推动闭源开发者迭代提速。
过去几年中,闭源模型与开源模型共同发展。OpenAI发布了闭源模型(如GPT-4),而Meta通过推出开源的LLaMA2推动了开源模型的普及,降低了微调模型的门槛。学术界也与产业界协作,共同加速研究进展。斯坦福的Alpaca和LMSYS的Vicuna等项目使指令遵循模型的探索更加大众化。学术界还为大模型架构创新贡献力量,同时助力推动模型评估和安全性的发展。
开源的发展势头正推动闭源开发者加速迭代,同时为用户提供更多可定制的模型选择。中国公司也在推出具有竞争力的开源模型,包括阿里巴巴的Qwen3、DeepSeek的V3和R1以及MiniMax的M1和M2。
12月9日,智谱宣布开源其核心AIAgent模型AutoGLM,这是全球首个可自主操作手机的智能体,用户通过语音指令即可完成点餐、订票、文稿撰写等跨应用任务。
此外,全球大模型的智能水平也持续进步。参考OpenAI的5级路线图,当前,大模型已经发展至临近L3的交界处,未来将加速演进。