快科技4月23日消息,距离月底只剩下一周时间了,各家大模型最近都有新品或者升级发布,就是DeepSeek V4等得让人心急。
DeepSeek V4最让人期待的还是它这次会用什么新技术让国产AI大模型站上世界之巅,就算不是最强的,至少也要能达到跟闭源顶级AI掰手腕的水平。

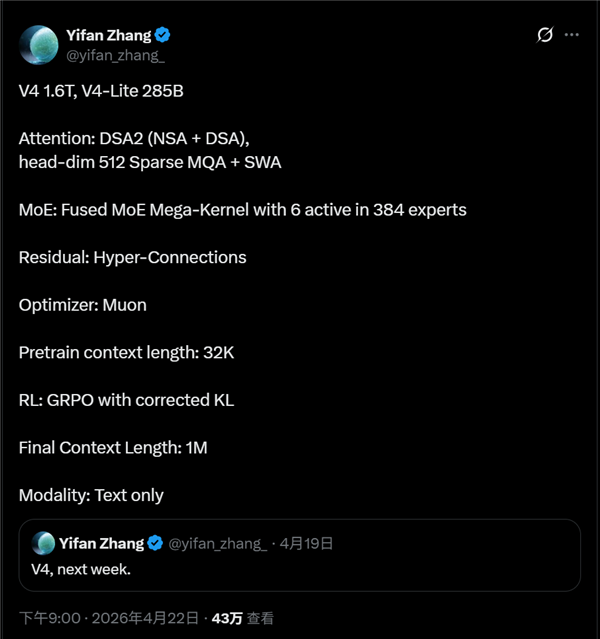
普林斯顿大学的博士生Yifan Zhang今天在X上公开了DeepSeek V4的完整技术规格,V4这次有两个版本大家都知道了,一个完整版,参数量高达1.6万亿,还有个V4 Lite,参数量2850亿,这些都很符合之前的传闻。
注意力机制上,DeepSeek V4采用了DSA2,融合了之前的DeepSeek V3/R1中的DSA机制,以及今年初DeepSeek论文中提出的NSA两种稀疏注意力机制。
MoE混合专家技术采用了融合方案,Mega内核,每层384个专家,每次激活6个专家。
残差连接则是之前论文中提出的Hyper-Connections,前不见的DeepGemm更新中也有提到。
后端训练及优化也涉及了非常多的新技术,优化器是Muon,RL强化学习使用的是GRPO及KL散度修正,最终将预训练的32K上下文扩展到了1M上下文。
此外,DeepSeek之前的更新中暗示会支持视觉,意味着是多模态的,但这里称它依然是纯文本大模型,有点意外。
总的来说,他这份爆料内容不少,但是真实性不好说,因为他也不是DeepSeek公司的研发人员,介绍的这些技术看起来也像是网上的资料综合起来的,很多细节在网上已经有过爆料或者官方资料露出了蛛丝马迹,就是不能完全确认而已。
DeepSeek R1发布至今已经过去15个月了,距离DeepSeek V3.2最终版也过去5个月了,这段时间各家大模型公司至少更新了一代大版本+两三个小版本迭代升级,DeepSeek V4面临的压力可不小,越是发布晚就越面临这个问题。
现在只能希望下周真的可以看到DeepSeek V4完整版及Lite版上线。