


新智元报道
编辑:好困 桃子
【新智元导读】就在刚刚,奥特曼深夜掷出GPT-5.5!全方位暴击Claude Opus 4.7,重新夺回地表最强王座。从写代码到搞科研,AI独立接管电脑的时代真的来了!
硅谷今夜未眠!
就在刚刚,GPT-5.5震撼登场——OpenAI迄今最强、最全能的新一代旗舰模型。
它是一种全新级别的智能,彻底进化为Agent时代的「原生大脑」。
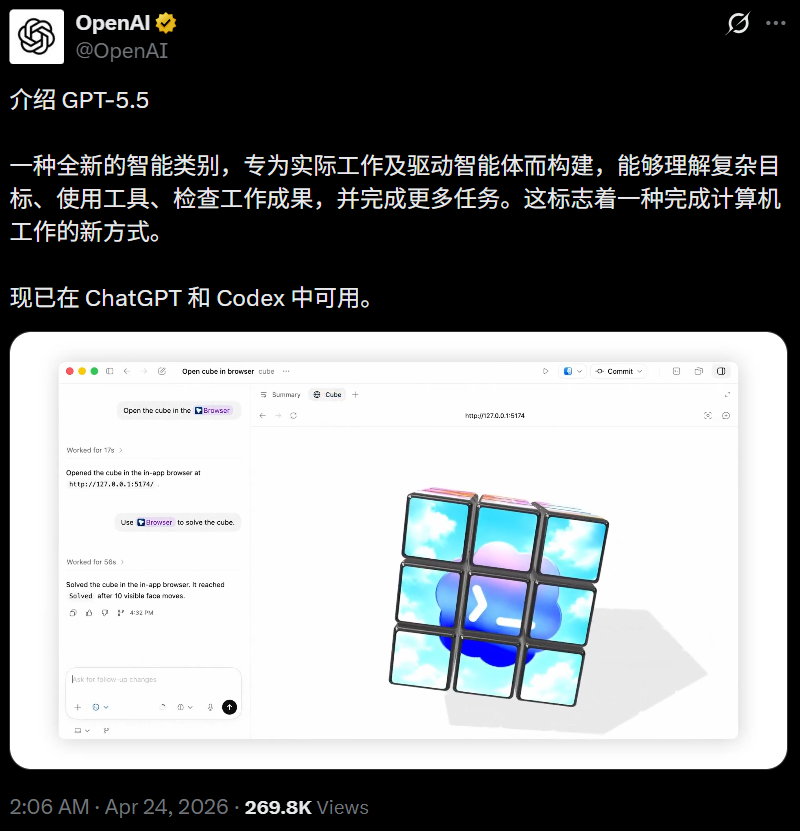
没错,就是那个万众期待的「土豆」(Spud),终于在今天杀出来了。


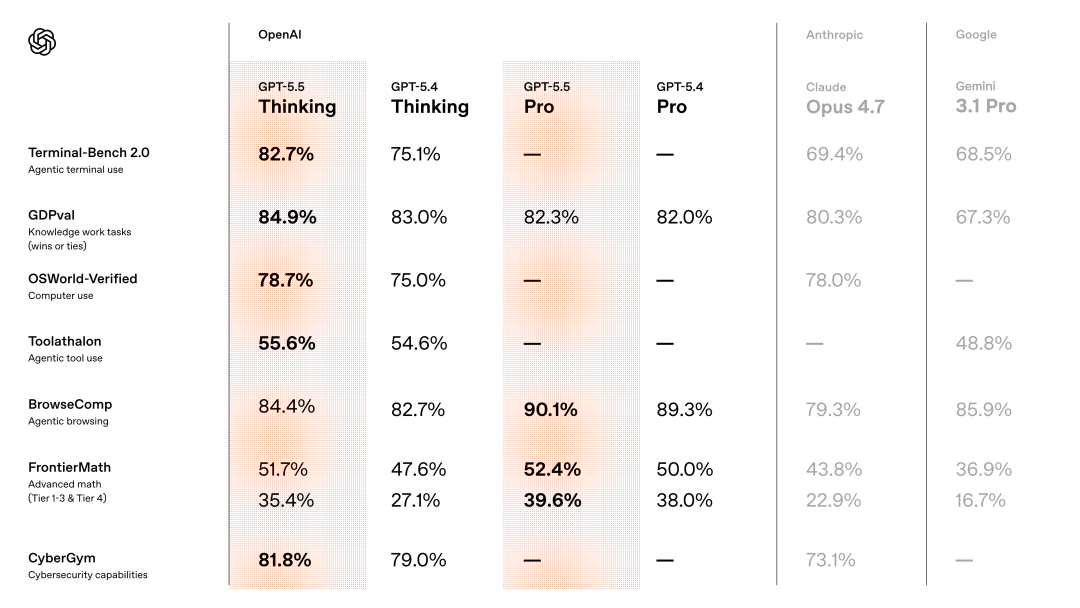
最值得看的是,GPT-5.5在各项基准测试中:全榜第一!
不论在编程、推理、数学,还是智能体任务上,Claude Opus 4.7、Gemini 3.1 Pro完全被GPT-5.5踩在了脚下。
相较于上一代,GPT-5.5 Thinking堪称「降维打击」,拉开了代际差距。
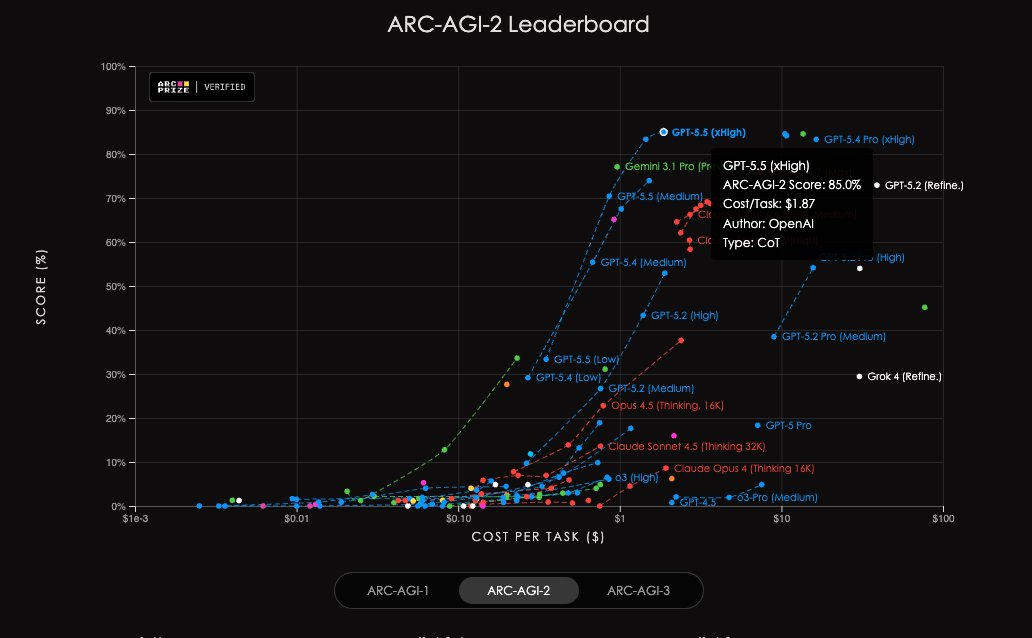
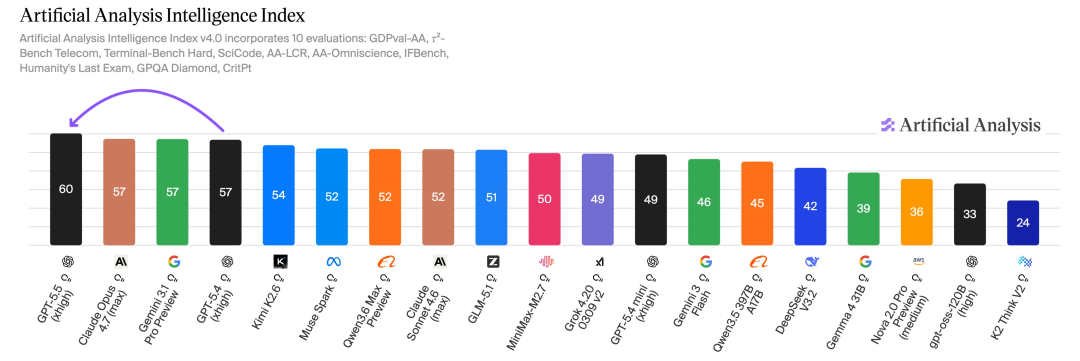
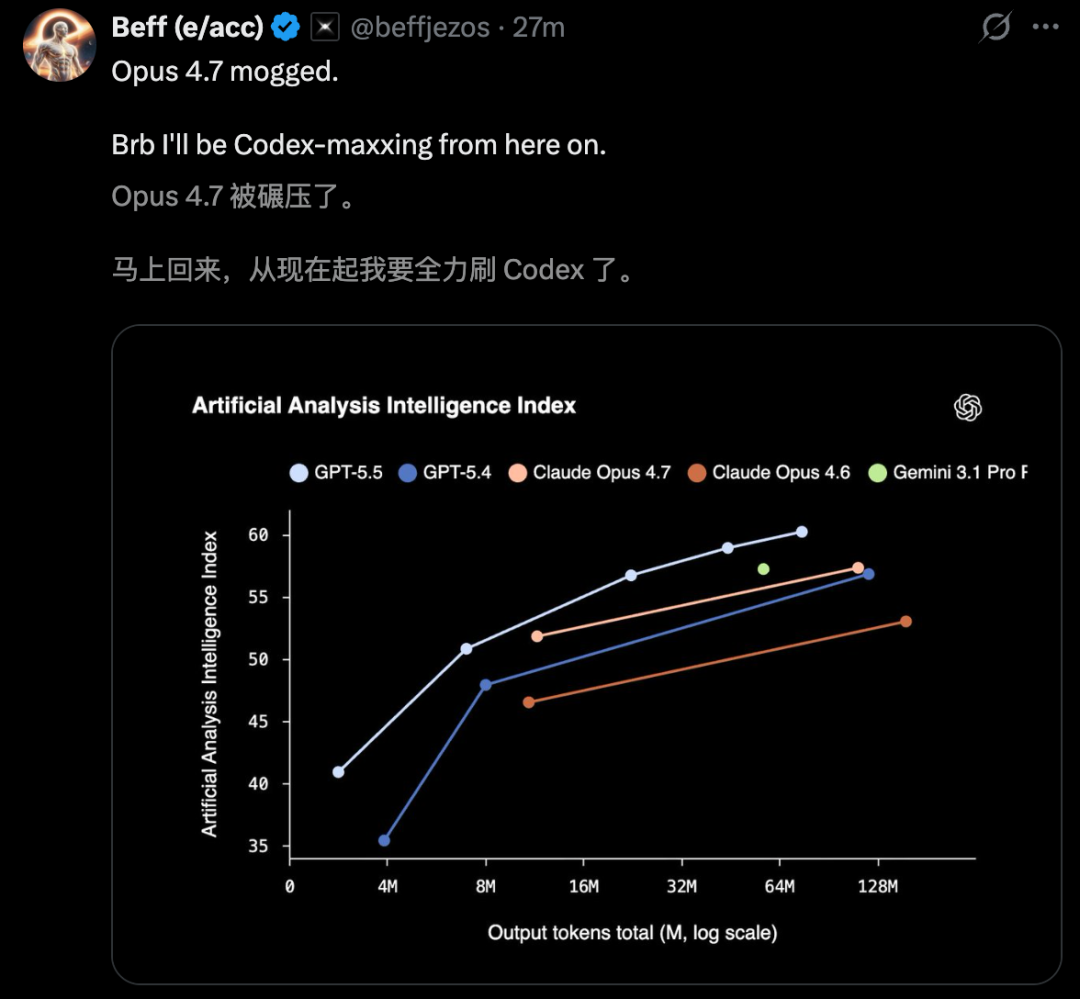
在AAI测试中,相同输出token下,GPT-5.5智能指数冠绝全球;另在ARC-AGI-2上,同样刷新了SOTA。
|
|
奥特曼忍不住大加赞赏,「GPT-5.5既聪明又快速」。
每个token的速度与GPT-5.4一样快,且每个任务使用token量显著降低。
它可以几乎做到心领神会,知道自己该做什么!

总裁Greg激动称,「这朝着一种全新的计算机工作方式迈出了一步」。

今天起,GPT-5.5在ChatGPT、Codex中正式上线。
编程新王登场
Opus 4.7跌落神坛
先看最核心的编程领域,GPT-5.5可谓是打了一场漂亮的翻身仗!
用OpenAI的话来说,它是迄今为止最强大的智能体编程模型。
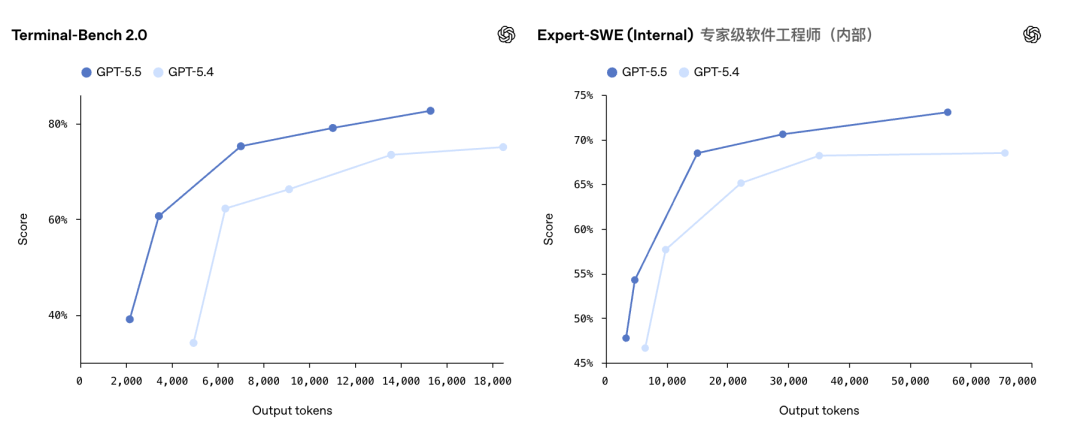
Terminal-Bench 2.0测试考的是全链路Agent工程实力。
题目会给模型一个终端环境和一个模糊目标,让它自己规划路径、调工具、写脚本、处理报错、反复迭代。
在这里,GPT-5.5拿下82.7%,GPT-5.4是75.1%,Claude Opus 4.7只有69.4%。13个百分点的差距,碾压级别。
OpenAI内部的Expert-SWE评测,专门测那些人类预估中位完成时间20小时的长周期编程任务,GPT-5.5拿到73.1%,同样高于GPT-5.4的68.5%。
在业界公认最能反映真实GitHub问题解决能力的评测SWE-Bench Pro中,GPT-5.5得分58.6%,略逊色于Claude Opus 4.7(64.3%)。
不过,OpenAI在这个数据旁边标了一个星号,写着「Anthropic报告称在部分问题子集上存在过拟合(记忆)迹象」。
换句话说就是,Opus 4.7虽然考试成绩好,但我怀疑你背过答案。

Codex研究员直言:SWE-Bench早已不能衡量顶尖编程能力了
最关键是,在这三项的评估中,GPT-5.5使用了更少的token,但仍全面赶超GPT-5.4。
这一能力在Codex中,体现得更为明显。
它可以完成「端到端」的编程任务,从实现、重构到调试、测试和验证等流程。
举个栗子,让GPT-5.5做一个阿尔忒弥斯II太空任务可视化应用。
首先把一张任务的截图扔给GPT-5.5,然后要求用WebGL和Vite实现一个可交互的3D轨道模拟器,轨迹数据必须来自NASA/JPL Horizons的真实矢量数据,并且还要有逼真的轨道力学。
只见,GPT-5.5从零搭完,鼠标拖拽能转,猎户座飞船、月球、太阳的相对位置都对得上。
