

今日,小米宣布永久性翻新整个模型定价体系。价格调整公告称,MiMo-V2.5 系列 API 实施永久降价,最高降幅达 99%,于北京时间 5 月 27 日 0:00 正式生效且全球同步。

继 DeepSeek 之后,小米成为又一家宣布 API 永久降价的大模型厂商。然而,在大方地向全球开放模型访问的同时,小米刚刚发布的 2026 年 Q1 财报却显示利润腰斩、营收下滑。
降价力度空前,不限上下文、Token 额度翻至 8 倍
此次价格调整覆盖 MiMo-V2.5 和 MiMo-V2.5 Pro 两个版本,与原 API 定价相比,新定价最高可减少 99%,且不再根据输入长度进行区分。
具体来看,MiMo-V2.5 Pro 的输入缓存命中价格降至 0.025 元 / 百万 tokens,相较于原价≤256k 规格 1.40 元降幅达 98%,对比 256k-1M 规格 2.80 元降幅更是触及 99%;输入未命中缓存定价 3.000 元 / 百万 tokens,较原价 7.00 元下降 57%,对比长窗口原价 14.00 元降幅 79%;输出定价 6 元 / 百万 tokens,相较原价 21 元、42 元分别下降 71% 与 86%。
MiMo-V2.5 的输入缓存命中价格降至 0.02 元 / 百万 tokens,较≤256k 原价 0.56 元降幅 96%,较 256k-1M 原价 1.12 元降幅 98%;输入未命中缓存定价 1.000 元 / 百万 tokens,相比原价 2.80 元降幅 64%,对比长窗口原价 5.60 元降幅 82%;输出定价 2 元 / 百万 tokens,较原价 14 元、28 元分别下滑 86% 与 93%。
除了 API 价格下调外,MiMo 的 Token Plan 计费体系也同步迎来重大优化:增加数量但不涨价,使用量提升到原来的 5-8 倍。在公告中,小米列出了调整后的详细计费规则,如下:
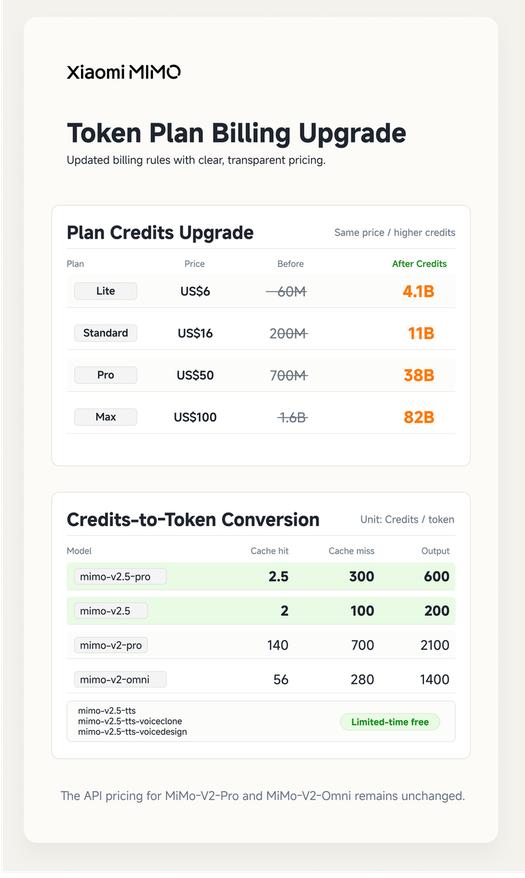
此外,无论当前使用情况如何,所有已订阅代币计划且仍在有效期内的用户(包括参与 Quadrillion 代币创建者激励计划并获得代币计划的用户,涵盖 Apache 软件基金会独家福利的用户)的积分配额于北京时间 5 月 27 日 0:00 完全重置,并根据新的计费规则实施。对于代币计划已过期的历史付费用户,小米准备了惊喜礼物,将在下周内公布。
值得注意的是,本次调价主要聚焦 MiMo-V2.5 核心系列,MiMo-V2.5-TTS 系列依旧保持限时免费接入政策,而 MiMo-V2-Pro 与 MiMo-V2-Omni 两款高阶模型 API 价格维持原价不变,同时其 Token Plan 套餐也不再参与调整并即将下线,引导开发者向高性价比的 V2.5 系列迁移。
据了解,MiMo-V2.5 系列的迭代由曾任职 DeepSeek 的 95 后 AI 技术人才罗福莉负责。在整个 MiMo 大模型产品矩阵中,MiMo-V2.5-Pro 主打高性能复杂推理,适配企业级智能体开发、深度业务分析等高阶商用场景;MiMo-V2.5 聚焦轻量化通用需求,主打中小开发者日常调用与轻量化应用落地;MiMo-V2.5-TTS 则瞄准语音合成赛道,以免费策略抢占音频生态入口。
营收利润都跌麻了,雷军:AI 还得再投 600 亿
对于此次价格调整的原因,小米称,这背后是其技术团队对推理系统的持续优化。“我们完全支持基于 SGLang HiCache 的 SWA(滑动窗口注意力),将 KV 缓存在 GPU 内存、CPU 内存和 SSD 等多级存储之间的数据传输量减少到优化前的近 7 分之一,并将可缓存 token 数量提升到优化前近 5 倍,显著提升了缓存命中率和推理效率。同时,我们通过优化专家并行方案、输入长度分桶策略等,进一步提升了集群的输入吞吐量容量,持续降低每枚 token 的服务成本,同时确保服务质量。”
在公告中,小米还强调,“技术的价值最终在于其广泛的使用。让更多人使用更好的模型,这是 MiMo 坚定不移的使命。”
据了解,小米当前在 AI 方面的底层研发投入数额已然十分庞大。北京时间 5 月 26 日晚,小米发布了 2026 年第一季度财报(截止 2026 年 3 月)。在技术创新领域,小米本季度研发支出达 90 亿元,同比增长 33.4%,研发团队规模扩大至 26048 人。不过相较从 2025 年第四季度 96 亿元的研发开支,这季度已经减少 6.7%,小米称“主要是基于手机 xAIoT 相关的研发项目进度所致”。
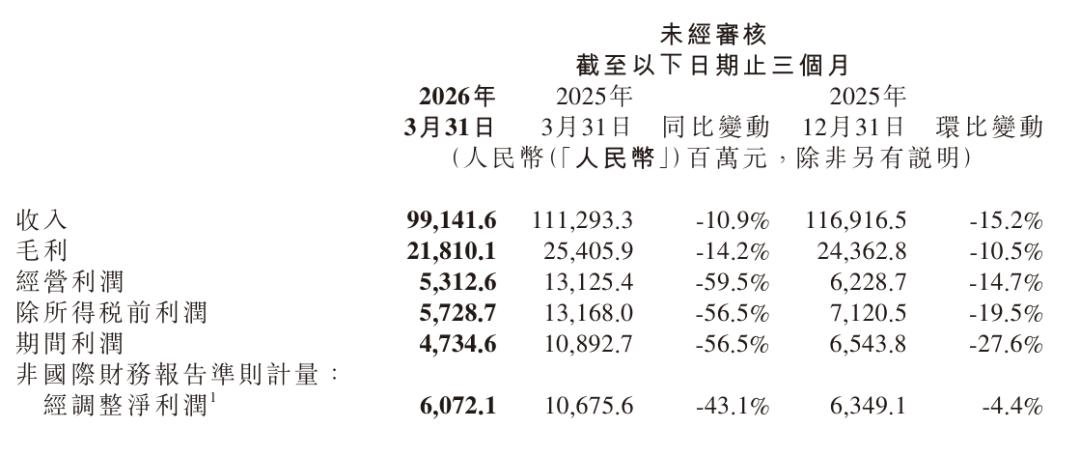
然而,从整体财报数据来看,小米这季度的营收、毛利率、经营利润、经调整利润无论是同比还是环比都出现不同程度地下滑。一季度小米总收入录得 991.4 亿元,同比下跌 10.9%;经调整净利润也从 106.8 亿元回落至 60.7 亿元,跌幅达 43.1%;毛利为 218.1 亿元,同比下跌 14.2%。经营利润承压更为严重,从去年同期的 131.3 亿元大跌 59.5% 至 53.1 亿元。
尽管如此,小米仍计划持续加大 AI 领域的资金投入。就在昨日,小米创始人雷军表示,“Xiaomi MiMo-V2.5-Pro 跻身 Artificial Analysis 榜单综合智能指数、Agent 指数全球开源模型并列第一。小米今年 AI 投入至少 160 亿元,未来三年在 AI 领域计划投入 600 亿元。”
国内外 AI 定价分化,海外网友:疑惑但“我选中国模型”
在小米宣布降价前不久,国内另一头部大模型公司 DeepSeek 已先一步开启“永久降价”。该公司宣布,DeepSeek-V4-Pro 模型 API 价格在 5 月 31 日结束 2.5 折的限时优惠后,永久调整为原定价的 1/4。调价后,这一模型的输入缓存命中 0.025 元 / 百万 tokens、未命中缓存 3 元 / 百万 tokens、输出 6 元 / 百万 tokens,相较原价实现 75% 的降幅。
实际上,在 4 月 24 日上线并同步开源后,DeepSeek V4-Pro 模型的原价只维持了两天。4 月 26 日,DeepSeek 就宣布限时 2.5 折优惠,优惠期截至 5 月 5 日。4 月 28 日,该公司又宣布将优惠期延长至 5 月 31 日。现在,定价直接降至了原来的 1/4。如今,DeepSeek V4-Pro 的调用价格,已经低得有些“离谱”了,比 GPT-5.5 便宜 34 倍。
有海外网友表示,“我已经迫不及待想搭建一个大模型集群,用上百个 DeepSeek 和 Mimo 模型协同运行。如今真是技术狂飙的时代。”网友们表示,“在人工评测榜单上,小米 MiMo 仅比 Opus 低 3 分,价格便宜了百倍以上,性能差距却微乎其微。即便只是 DeepSeek V4 Flash(还不是 Pro 版),调到高性能档位后,能力基本比肩 Claude Opus 4.7,响应速度极快,成本还极低。连续对话数小时,花费也才几美分。”
还有人指出,“除了 Deepseek 和小米,现在很多 AI 实验室都会骗你缓存读取。如果你为缓存读取花了不少钱,实际上是在为几秒钟的显存时间付出高昂的代价。自回归语言建模的本质在于,每一个输出 token 都会‘读取’缓存。所以原则上,缓存命中的价格下限是 1 个输出 token 的固定成本。但实际上,情况可能不止于此,因为你用缓存占用了显存,迫使其他用户退出。”
“所有美国公司(OpenAI、Anthropic、Google、MS Copilot)最近都涨价了,而中国公司则在降价。问题是,他们是怎么做到的?按理说,他们本应因芯片制裁更吃力才对。其次,为什么是现在?原本美国公司也被认为会通过补贴来维持竞争力,但现在他们已经跟不上了。大家都在转向按使用量计费的模式,这对他们来说似乎不可持续。毕竟他们的资金也很充足。如果真的存在能够降低算力需求的硬件突破,我相信这对全世界来说都是一件好事。“有海外网友发出疑问。
据了解,除小米与 DeepSeek 外,国内的阿里云通义千问、字节跳动豆包等通用型大模型相继下调 API 调用价格。
今年以来,全球在线 AI 托管平台 OpenRouter 上,中国大模型连续占据前列,包括小米 MiMo 、阶跃星辰 Step 3.5 Flash、MiniMax、DeepSeek、Kimi 等。而 OpenRouter 的“霸榜”逻辑无非是,在 API 够用的情况下,调用成本越低廉,调用总量排名就越高。
“借助中国模型,谁都能用上高性价比的 AI 服务。”有网友说道,“当前美国 AI 公司几乎没有机会收回哪怕一小部分估值。”
