

IT之家 5 月 27 日消息,据凤凰网财经报道,在 2026 凤凰湾区财经论坛 · 金融峰会上,华为技术有限公司金融系统部 CTO 郑俊表示,在中美 AI 行业竞争中,双方在模型层面的差距已十分微小。根据斯坦福最新报告数据,中国 AI 模型整体水平仅落后美国 2.7%,整体实力已无限接近国际先进水平。
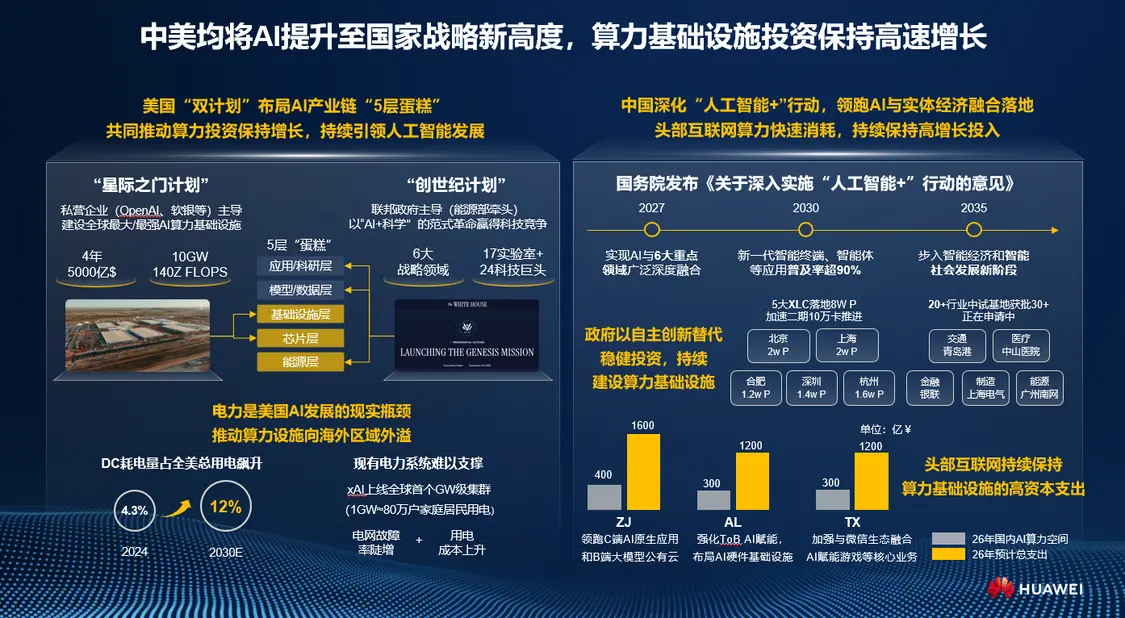
郑俊指出,自今年 2 月份以来,中国模型的调用量持续碾压美国模型。他分析称,这一现象主要源于两大核心原因,一是国内开源模型能力大幅提升,已逼近美国闭源模型水平;二是依托中国基础设施优势,叠加算力、电力资源优势,国产 AI 模型具备更强的价格经济性。
据IT之家今日早些时候报道,国务院新闻办公室举行了“开局起步‘十五五’”系列主题新闻发布会。会上提到,我国将加快研究推进人工智能健康发展综合性立法、低空经济立法等。
本月早些时候,国家发改委政策研究室副主任、新闻发言人李超表示,发改委推动人工智能与经济社会各行业各领域广泛深度融合,指导国产大模型加大力度适配国产算力芯片,在保持快速发展的同时,确保自主可控、向善发展、行稳致远,让全体人民共享人工智能发展成果,这也是我国人工智能发展的一大突出特征。
另外,截至 4 月 30 日,我国累计有 868 款生成式人工智能服务完成备案,530 款生成式人工智能应用或功能完成登记。国家数据局数据显示,2025 年,我国用于人工智能训练和推理的数据总量为 199.48EB(Exabyte,艾字节 | 1EB=1024PB=1,048,576TB),同比增长 42.86%,推理数据量首超训练数据量,达 101.34EB。
相关阅读:
《国家发改委:指导国产大模型加大力度适配国产算力芯片》
《我国将加快研究推进人工智能健康发展综合性立法、低空经济立法等》
《2025 年我国用于人工智能训练和推理的数据总量达 199.48EB,同比增长 42.86%》
《网信中国:截至 4 月 30 日,我国累计有 868 款生成式人工智能服务完成备案》
