

上周,Claude Code 发布了一个新能力:动态工作流。
该功能允许 Claude 根据具体任务即时编写定制化执行框架,协调多个子 Agent 并行工作,解决大规模、高并行、对抗性任务中的系统性失效问题。
近日,Anthropic 工程师 Thariq 发了篇长文,分享了他最初的工作流经验和心得。
我们对此进行了全文整理译述。
在深入技术细节之前,Thariq 先提供了一些示例提示,来让我们理解工作流的潜力:
- 「这个测试可能每 50 次运行失败一次。设置一个工作流,重复运行测试,形成假设,并在工作树中对其进行对抗性验证 / 目标:不停尝试,直到有一个假设成功。」
- 「使用工作流,回顾我最近的 50 次会话,挖掘我反复犯的错误,并将这些重复性问题生成 CLAUDE.md 规则。」
- 「用工作流翻查过去六个月 Slack 的 #incidents 频道,找出反复出现、但还没有人提交工单的根本原因。」
- 「拿我的商业计划,运行一个工作流,让不同的 Agent 从投资者、客户和竞争对手的角度进行拆解。」
- 「这里有一个包含 80 份简历的文件夹,用工作流对其进行排名,选出后端岗位的最佳候选,并对前十名进行复核。使用 AskUserQuestion 工具进行面试评分。」
- 「我需要给这个 CLI 工具取名。使用工作流生成多个选项,并进行淘汰赛选出前三个最佳方案。」
- 「使用工作流,将我们的 User 模型重命名为 Account。」
- 「审查我的博客文章草稿,使用工作流验证每一项技术声明是否符合代码库,确保不发布错误信息。」
动态工作流如何工作
动态工作流执行一个包含特殊函数的 JavaScript 文件,这些函数帮助生成和协调子 Agent。
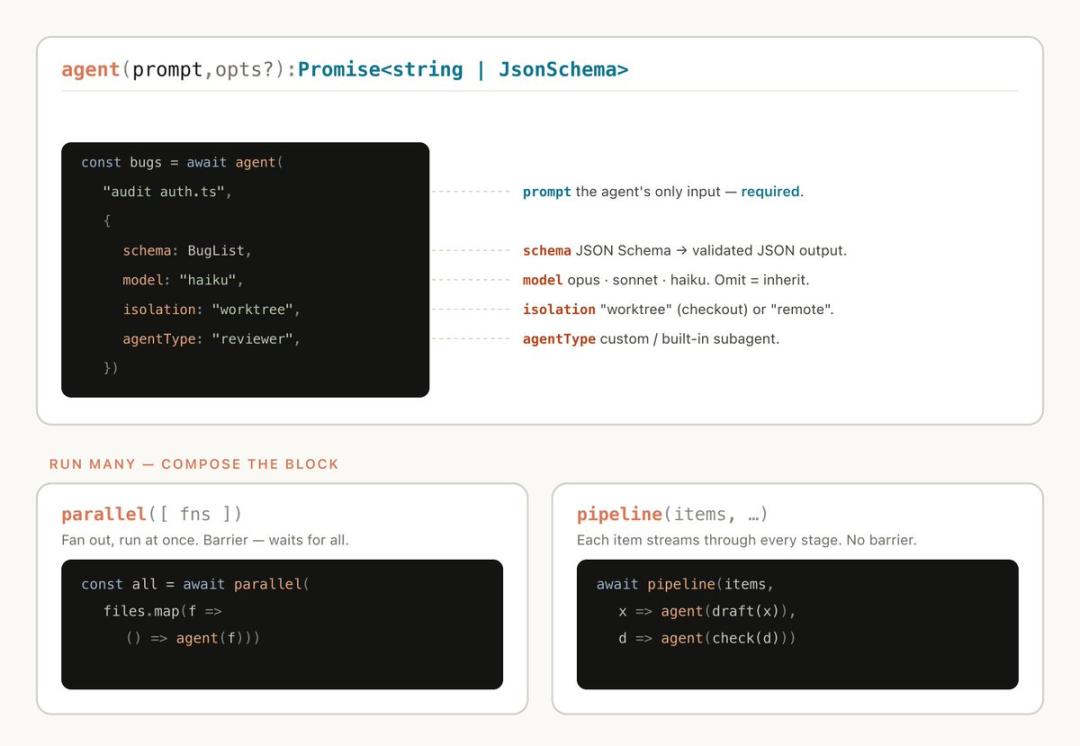
同时,动态工作流还包括标准 JavaScript 功能,如 JSON、Math 和 Array,用于处理数据。
动态工作流可以决定一个 Agent 使用的模型类型,以及子 Agent 是否在独立的工作树中运行,从而让 Claude 选择所需的智能水平和隔离方式。
如果工作流中断,例如被用户操作或终端退出,恢复会话时,工作流可以从中断点继续执行。
为何使用动态工作流
当我们使用默认 Claude Code 框架执行任务时,它需要在同一个上下文窗口中同时进行计划和执行。对于许多编程任务,这非常有效,但在长时间运行、大规模并行或高度结构化的对抗任务中,有时会出现问题。
原因在于,Claude 在单个上下文窗口中处理复杂任务时间越长,就越容易出现以下几类失败模式:
- 智能体懒惰(Agentic laziness):Claude 在处理复杂多步骤任务时可能提前停止,宣称任务完成,例如只处理 50 条安全审查中的 20 条。
- 自我偏好偏差(Self-preferential bias):Claude 倾向于偏向自己的结果或发现,尤其在需要验证或评估时。
- 目标漂移(Goal drift):在多轮操作中,任务目标逐渐偏离,特别是在压缩总结之后,细节如边缘案例或「禁止做 X」的约束可能丢失。
创建工作流可以通过为不同目标分配独立上下文窗口的 Claude 实例来避免这些问题,每个实例专注、隔离任务目标。
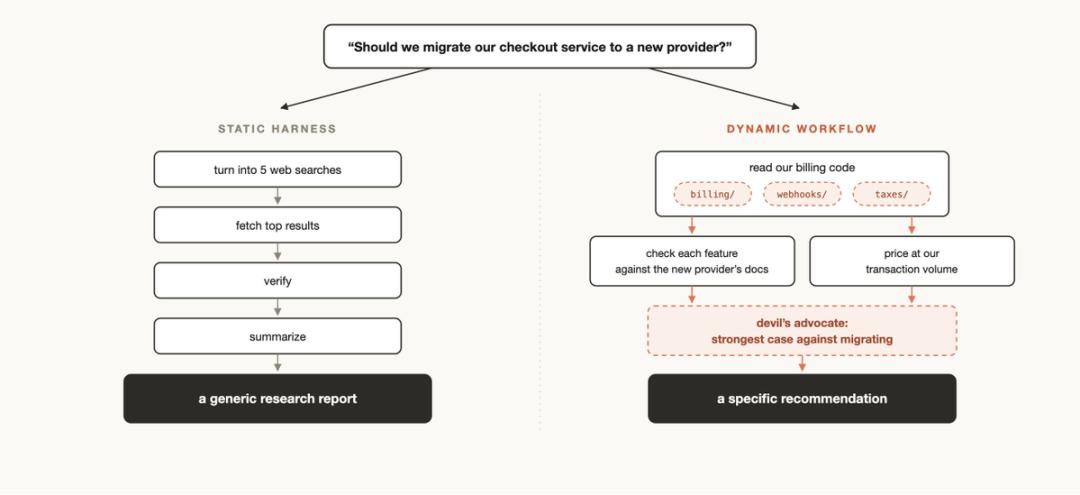
动态与静态工作流的区别
你可能之前使用 Claude Agent SDK 或 claude -p 创建过静态工作流,以协调多个 Claude Code 实例。
静态工作流需兼顾所有极端情况,因此通常更通用。而使用 Claude Opus 4.8 的动态工作流,Claude 现在能够生成针对你的特定用例定制的智能框架。
动态工作流的常用模式
你可以直接让 Claude 生成动态工作流,或者使用触发词「ultracode」确保 Claude Code 创建工作流。
理解动态工作流的常用模式,有助于判断何时使用以及如何通过提示引导 Claude:
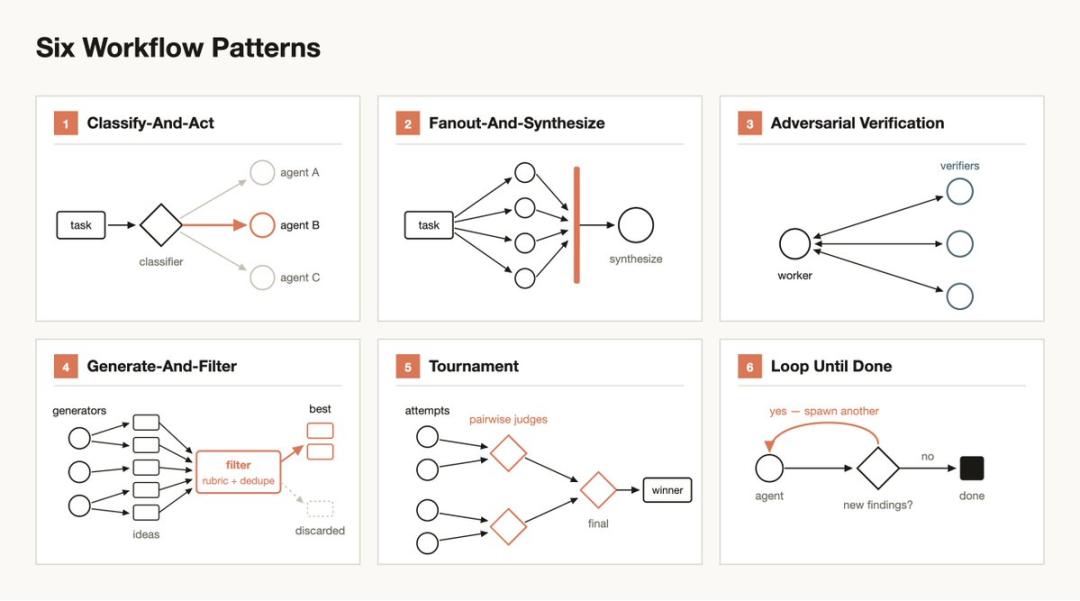
- 分类并执行(Classify-and-act):使用分类器 Agent 决定任务类型,然后根据任务路由到不同 Agent 或行为,也可在最后使用分类器判断输出。
- 分发并汇总(Fan-out-and-synthesize):将任务拆分成多个小步骤,每个步骤由一个 Agent 处理,然后汇总结果。特别适合大量小步骤或每步需要独立上下文的情况。汇总步骤会等待所有分发 Agent 完成,然后将结构化输出合并。
- 对抗性验证(Adversarial verification):每个子 Agent 的输出都由另一个 Agent 对照评判标准进行对抗性验证。
- 生成并筛选(Generate-and-filter):生成多个想法,然后根据评判标准筛选,去重,只返回高质量且验证过的想法。
- 竞赛(Tournament):让多个 Agent 以不同方式执行相同任务,再通过评判 Agent 两两比较结果,选出最优。
- 循环直到完成(Loop until done):对于工作量未知的任务,循环生成 Agent,直到满足停止条件(无新发现或日志中无更多错误),而非固定轮次。
用例
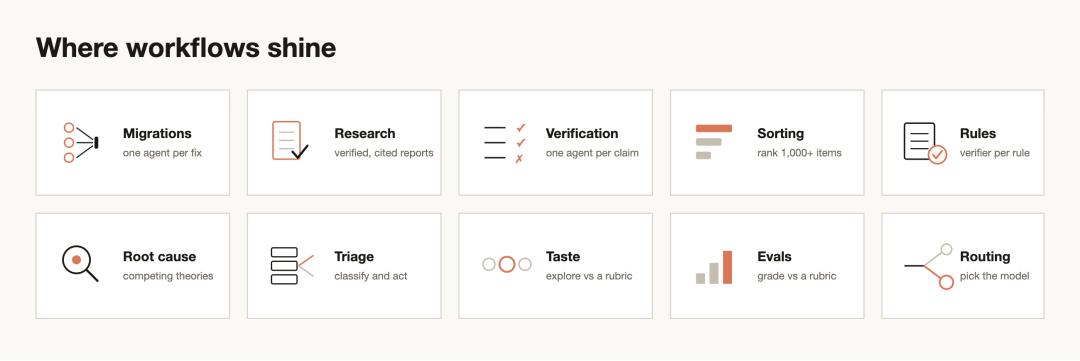
迁移与重构
Bun 从 Zig 重写到 Rust,就是用 workflows 完成的。
关键是把任务拆成一系列可以逐步处理的小单元,比如调用点、失败测试、模块等。每一个修复都在独立的 worktree 里派出一个子 Agent 去完成;之后再让另一个 Agent 做对抗式审查,确认没问题后再合并。
如果希望尽可能并行,又不想把本机资源打满,可以明确告诉 Agent 不要运行资源消耗很高的命令。
深度研究
我们在 Claude Code 里发布了一个深度研究 skill(/deep-research),它使用的就是动态 workflows。
具体来说,它会并行展开网页搜索,抓取资料来源,对其中的说法做对抗式验证,最后整合成一份带引用的研究报告。
不过,这类研究并不只限于网页搜索。比如,你也可以让 Claude 从 Slack 的上下文里整理一份状态报告,或者让它深入浏览代码库,研究某个功能到底是怎么实现的。
深度验证
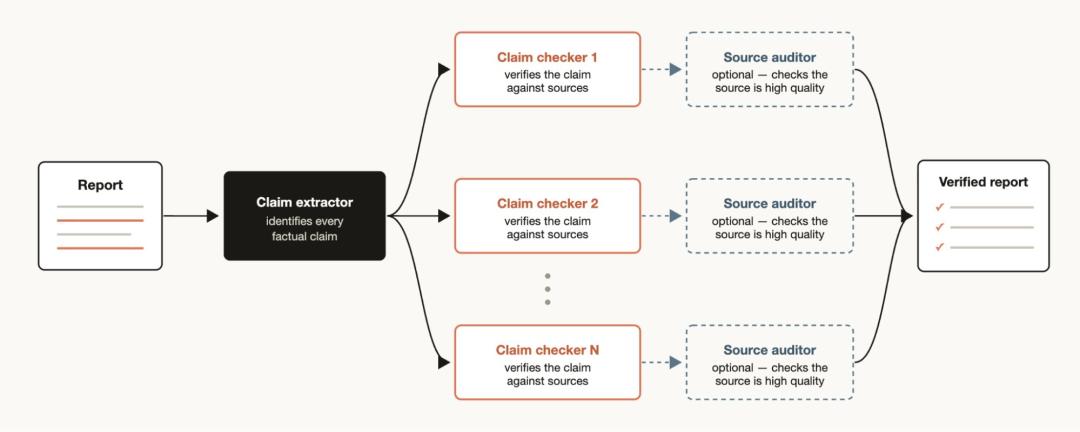
另一方面,如果你有一份报告,并希望逐一核查其中引用的每一项事实陈述及其来源,你可以构建一套工作流:先由一个智能体负责识别出所有的事实陈述,随后派生出一个子智能体,对每一项陈述进行详尽的核查。此外,你还可以引入一个验证智能体,专门对负责溯源的子智能体进行复核,以确保其所引用的来源具备高质量。
排序
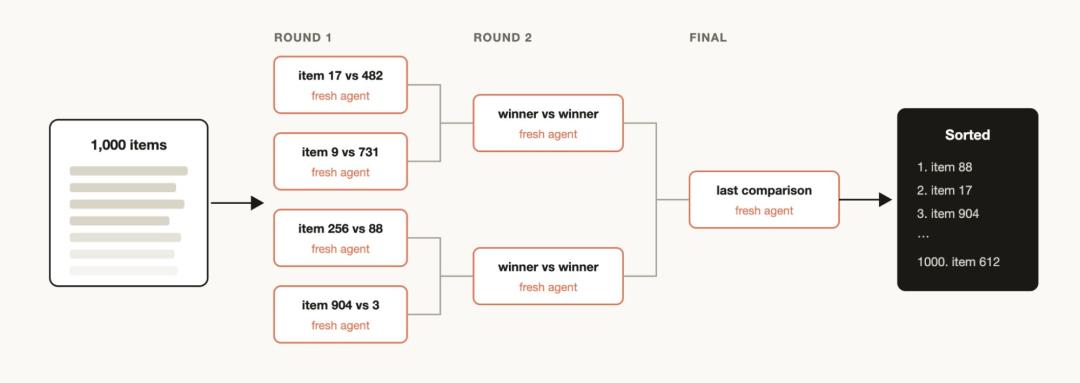
你可能会有一批条目,想按某种定性的标准来排序,而这个标准又是 Claude Code 比较擅长判断的。比如,把支持工单按 bug 严重程度排序。
但如果你想在一个 prompt 里一次性处理 1000 多行,质量很容易下降,而且上下文也放不下。更好的做法是跑一场「锦标赛」:搭建一条由两两比较 Agent 组成的流水线。相比直接打绝对分,两两比较通常更可靠。
也可以先并行分桶排序,再把结果合并。每一次比较都交给一个独立 Agent 完成,确定性的循环负责维护整个比赛括号,真正留在上下文里的,只有当前正在执行的顺序。
记忆与规则遵循
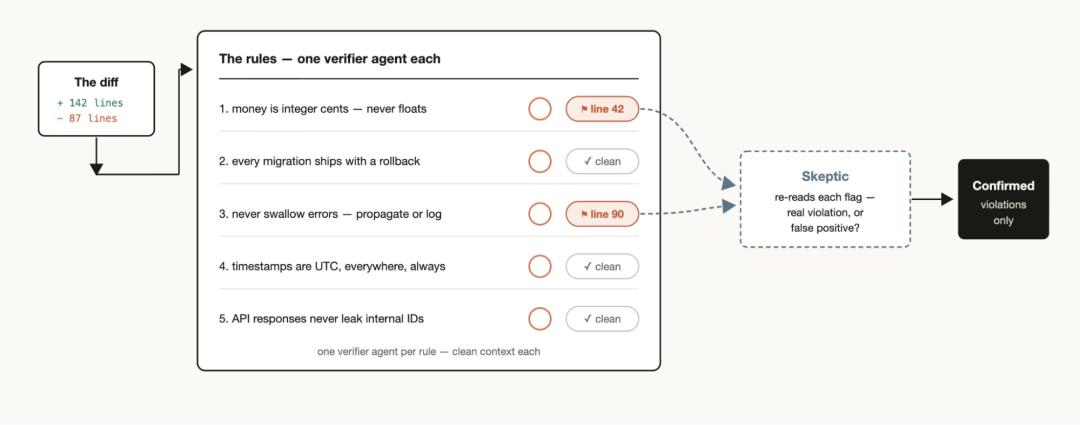
如果你发现有一组规则,即便写进 CLAUDE.md,Claude 仍然经常漏掉或执行不好,则可以专门做一个工作流:把这些规则列出来,让验证 Agent 逐条检查。每条规则对应一个验证 Agent。
同时,再创建一个带有怀疑者视角的子 Agent,专门复核这些规则是否合理、是否真的对齐目标,这样可以减少过多误报。
反过来也成立:你可以从最近的会话和代码审查意见里,挖出那些你反复纠正的问题;再让多个 Agent 并行归类整理;然后对每条候选规则做对抗式验证,比如追问:这条规则当时真的能避免一个真实错误吗?最后,把通过验证的规则再提炼回 CLAUDE.md。
根因调查
调试最有效的方法,通常是先提出几个相互独立的假设,再逐一验证。但如果只依赖一个上下文窗口,Claude 很容易陷入某种「自我偏好」:越看越相信自己最初的判断。
工作流可以从结构上避免这一点。它可以让多个 Agent 基于彼此隔离的证据分别提出假设。比如,一个 Agent 只看日志,一个只看文件,一个只看数据。随后,每个假设再交给一组验证者和反驳者来检验。
这种方法并不只适用于代码。销售场景也可以用,比如分析 3 月销售额为什么下滑;数据工程也可以用,比如排查某条数据管道为什么失败。任何需要做复盘、找根因的问题,都可以用类似的工作流来处理。
大规模工单分拣
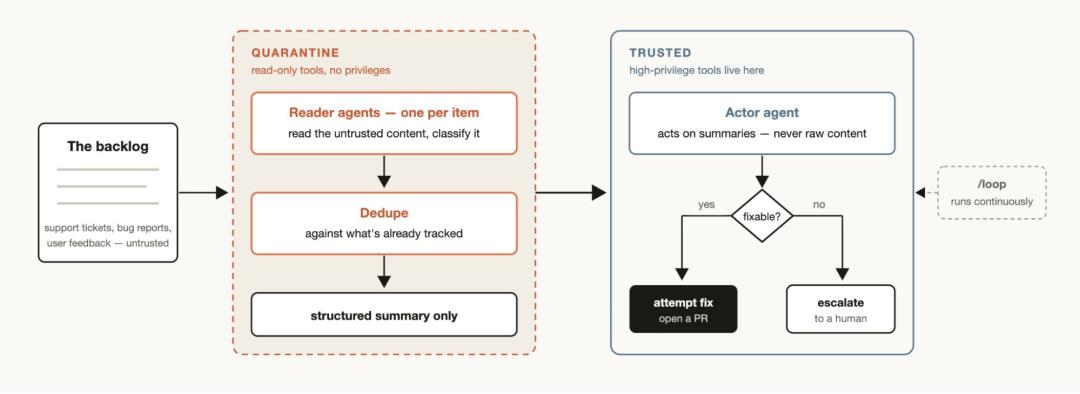
每个团队都面临着支持工单队列、Bug 报告或其他积压任务,这些任务往往无法仅凭人工完全处理。分流工作流(Triage workflow)能够对每一个待办事项进行分类,与已追踪的条目进行去重比对,并采取相应的行动。这些行动可能包括尝试直接修复问题,或者将其升级转交给人工用户处理。
在分流工作流中,「隔离」(Quarantine)是一种非常实用的模式。其核心做法是:禁止那些负责读取非受信公共内容的智能体执行高权限操作;相反,这些高权限操作将交由专门负责基于信息采取行动的智能体来执行。将分流工作流与 /loop 指令结合使用,即可让 Claude 持续不断地自动执行此类任务。
探索与品味判断
在探索针对某一解决方案的不同实现路径时,工作流显得尤为有用 —— 特别是当任务涉及主观「品味」判断(如设计或命名工作)且需要依据一套既定标准(Rubric)进行评估时。
不妨尝试让 Claude 探索并生成一系列潜在的解决方案,随后指派一个「评审智能体」,并为其提供一套明确的评估标准,用以界定何为「优质」的解决方案。当该评审智能体判定某方案已完全符合既定标准时,该任务即宣告完成。此外,还可以依据这套评估标准,通过「锦标赛」式的比拼机制对各类解决方案进行排序或最终筛选。
评估
你可以针对特定任务运行轻量级的评估流程:首先在独立的「工作树」(Worktree)中衍生出一组智能体来执行任务;随后再衍生出一组「对比智能体」,依据既定的评估标准对前述智能体生成的具体输出结果进行比对与评分。举例而言,你可以利用这一机制,依据特定的评估标准,对你所创建的某项 Skill 进行评估,并在此基础上加以迭代优化。
模型与智能路由
你可以创建一个专门针对你的任务进行调优的「分类智能体」,由其负责决策应调用哪一个基础模型来执行任务。当你的任务涉及大量的工具调用时,这一机制尤为实用 —— 通过在正式执行任务前进行预先分析与调研,该分类智能体能够精准识别出最适合当前任务的基础模型。
举例来说,针对「解释认证模块(Auth module)的工作原理」这一任务,其最佳的基础模型选择并非一成不变,而是取决于该认证模块内包含的文件数量以及整个代码库的整体结构形态。此时,分类智能体便可承担起这项预先分析的职责,并依据对任务预期复杂度的判断,将任务智能路由至 Sonnet 或 Opus 等不同的基础模型进行处理。
何时不宜使用动态工作流
「工作流」是一项相对较新的功能。尽管在许多应用场景下,它能带来事半功倍的显著成效,但并非每一项任务都必须依赖工作流;若滥用工作流,反而可能导致消耗远超预期的 Token 资源。
最佳的实践策略是发挥创意,以一种前所未有的方式灵活运用工作流,从而充分挖掘 Claude Code 的潜能。对于常规的编程任务,不妨先自问一句:这项任务真的有必要投入额外的计算资源来运行工作流吗?例如,大多数传统的编码任务并不需要由五名审阅者组成的评审小组。
构建动态工作流的技巧
提示词设计
针对动态工作流,若采用我们上文详述的特定技巧来编写详细的提示词,往往能取得最佳效果。
工作流并非仅适用于大型任务。你也可以通过提示词指令,让模型执行一种「快速工作流」。比如你可以快速构建一个针对特定假设进行「对抗性审查」的工作流。
结合使用 /goal 与 /loop 指令
当你需要执行可重复的工作流(例如任务分流、资料调研或信息核实)时,建议搭配使用 /loop 指令以实现周期性执行,并结合 /goal 指令来设定明确的任务完成硬性指标。
Token 使用预算
你可以为动态工作流设定明确的 Token 使用预算,以此限制单项任务所消耗的 Token 数量。你可以在提示词中直接指定预算额度,例如输入:「use 10k tokens」(使用 10k Token),系统便会自动设定相应的上限。
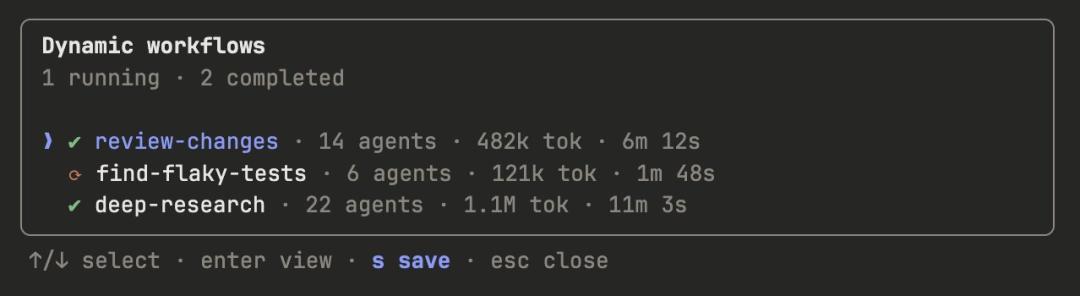
保存与分享动态工作流
你可以通过在工作流菜单中按下「s」键来保存当前的工作流。你可以将这些工作流文件归档至~/.claude/workflows 目录下,也可以将其打包为「技能」(Skill)的形式进行分发与共享。
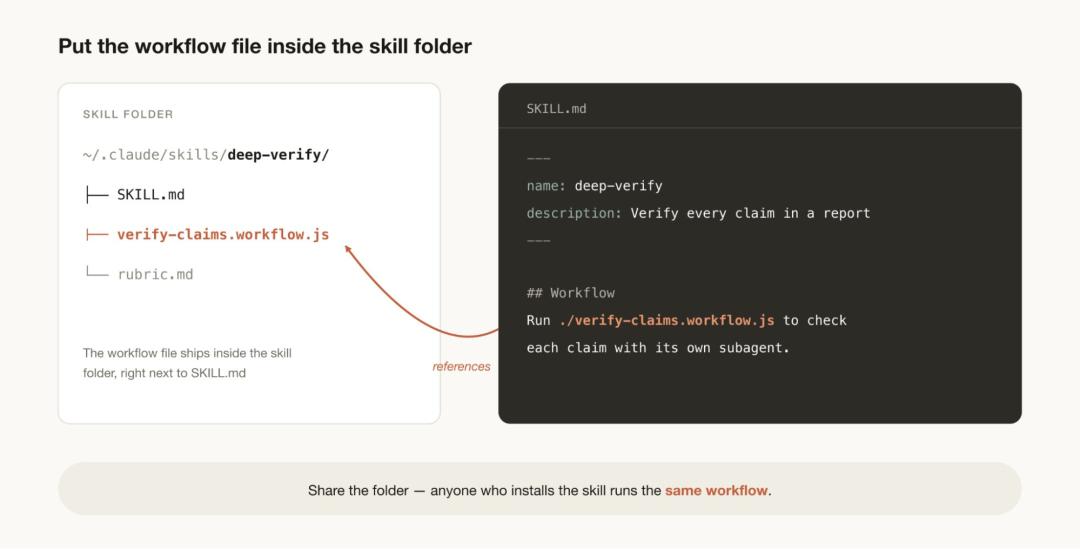
若要通过技能(Skill)来分享这些文件,请将你的 JavaScript 工作流文件放入该技能对应的文件夹中,并在 SKILL.MD 文件中引用它们。为了获得更大的灵活性,你可能希望提示 Claude 将该技能中的工作流视为「模板」,而非必须逐字逐句执行的脚本。
工作流是一种有助于扩展 Claude Code 的全新方式。大家应该将其视为一个起点 —— 关于如何充分发挥其效用,仍有许多值得探索之处。期待听到你的发现。
原文链接
https://x.com/trq212/status/2061907337154367865
