

腾讯混元提出 Stem 稀疏注意力算法,首字延迟降低 3.6 倍
4 小时前
/ 阅读约2分钟
来源:IT之家
腾讯混元提出Stem稀疏注意力算法,通过TPD和OAM创新,仅用25%算力逼近稠密注意力精度。配套HPC算子库将理论加速比转化为实测性能,实现全栈加速方案。
感谢IT之家网友 江山已旧、Domado 的线索投递!
IT之家 6 月 5 日消息,腾讯混元今日宣布提出 Stem 稀疏注意力算法,已被机器学习顶会 ICML-26 收录。

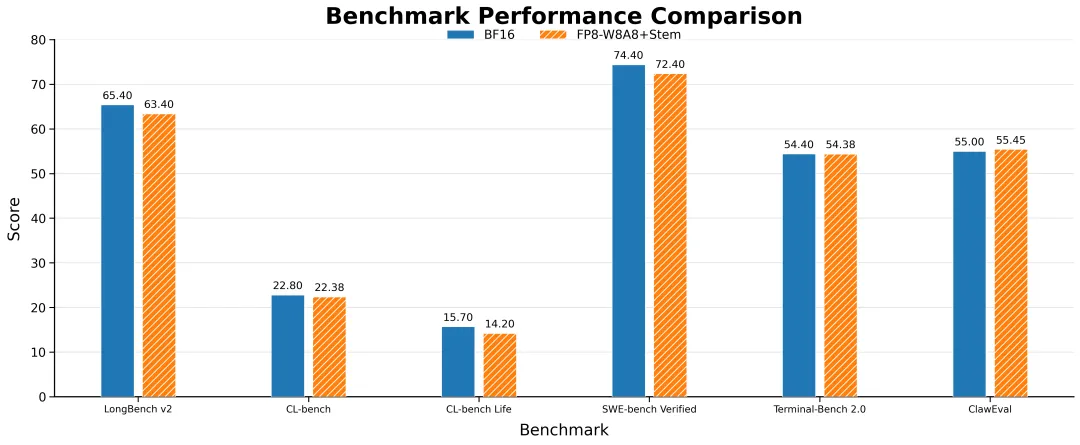
官方表示,Stem 稀疏注意力算法从“因果信息流”重新审视块级稀疏,用 Token 位置衰减(TPD)和输出感知度量(OAM)两大创新,仅用 25% 算力就逼近稠密注意力的精度。配套的 HPC 算子库则将这份理论加速比真正转化为端到端的实测性能。
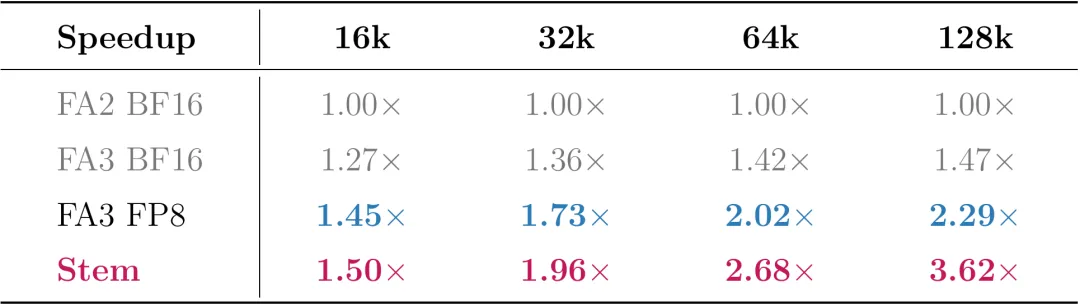
根据 Stem 算法 × HPC 算子的全栈加速方案,算法层面,Stem 通过 Token 位置衰减(TPD)和输出感知度量(OAM)实现 25% 预算下的近无损精度;算子层面,HPC 开源的 Stem+BSA 算子将稀疏收益转化为真实硬件加速,128K 上下文下首字延迟降低 3.6 倍。
IT之家附相关链接如下:
Stem 论文链接:https://arxiv.org/abs/2603.06274Stem
开源地址:https://github.com/Tencent/AngelSlimHPC
算子开源地址:https://github.com/Tencent/hpc-ops
