

6 月 13 日,智谱在 X 平台宣布 GLM-5.2 完全开放,并把正式开放的时间定在了当晚 5 点 21 分——一个「特殊时刻」。
很多人认为这个数字不是随便挑的:美国政府向 Anthropic 下发出口管制指令、切断 Fable 5 与 Mythos 5 境外访问权限的那一刻,正是美国东部时间下午 5 点 21 分。「5 点 21」这个数字上的重复,被多家媒体解读为一次刻意设计的呼应。智谱选择在这个节点站出来,相当于当着全世界开发者的面说了一句话:你们担心的「模型随时可能被收回」,开源这边没有这个问题。
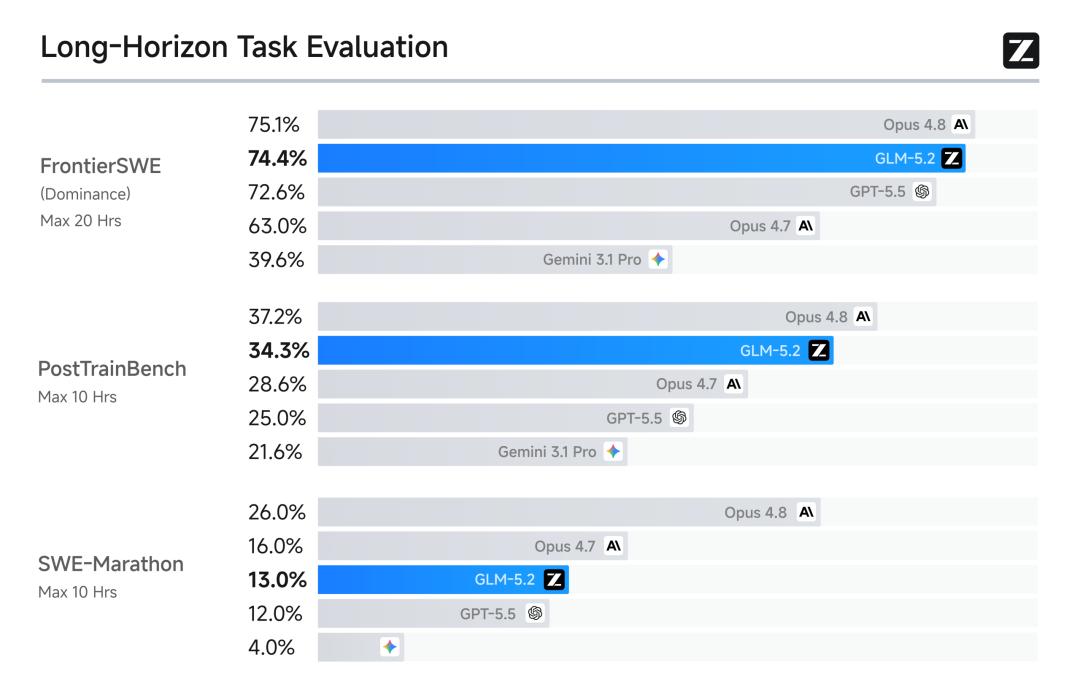
这次发布也确实给得起这个姿态。GLM-5.2 是一个 744B 参数、激活 40B 的 MoE 模型,遵循 MIT 协议完全开源,支持真正可用的 1M token 上下文。在长程任务基准 FrontierSWE 上,它拿到 74.4%,逼近 Claude Opus 4.8 的 75.1%,反超 GPT-5.5 的 72.6%。不少开发者实测后表示,这是第一个让他们认真考虑用来替换 Opus 或 GPT 工作流的开源模型。
昨天 Design Arena 发布的博客《GLM-5.2 如何在网站设计上击败了 Fable 5》更是成为爆款文章,引发了广泛关注和热议。
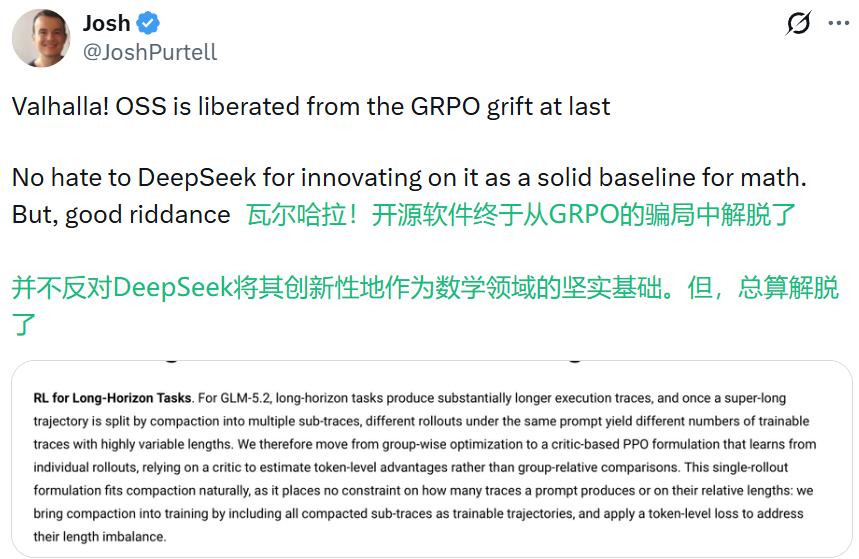
但比这些分数更让技术圈坐不住的,是一个差点被淹没在技术博客角落里的细节:GLM-5.2 在长程强化学习阶段,放弃了 GRPO。
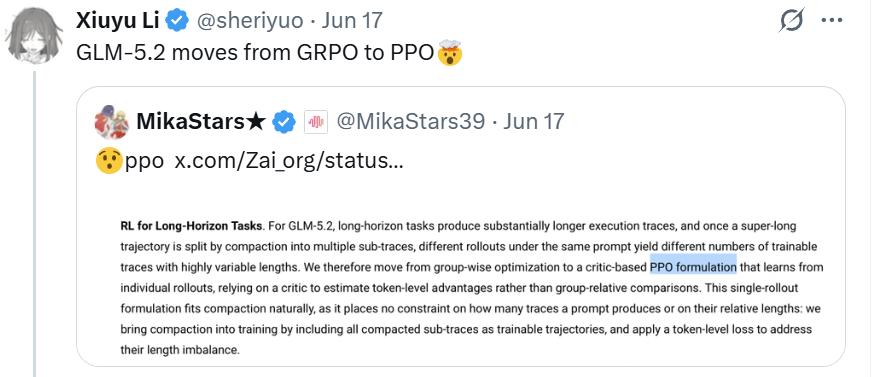
图源: X @JoshPurtell @sheriyuo @MikaStars39
这件事不大,却像一根针,扎破了一个维持了一年多的共识。GRPO(Group Relative Policy Optimization,群体相对策略优化)由 DeepSeek 于 2024 年在 DeepSeekMath 论文中提出,又经 DeepSeek-R1 验证,此后几乎成了开源社区训练推理模型的默认答案——不需要价值网络,也能训出强推理能力。GLM-5.1 的强化学习阶段,用的正是这套思路。一年多以后,GLM-5.2 悄悄把它换掉了。
一个被验证过的范式,正在被它最早的追随者之一悄悄抛弃。
技术社区的反应
消息传开后,X 上的讨论很快分成了几条线。
有人把这件事称为「critic 回来了」。开发者@hallerite 的判断很直接:群体内比较这种降低方差的办法,过了某个任务长度之后根本行不通,模型需要更细粒度的信号,OpenAI 和 Anthropic 大概早就在用价值网络了。
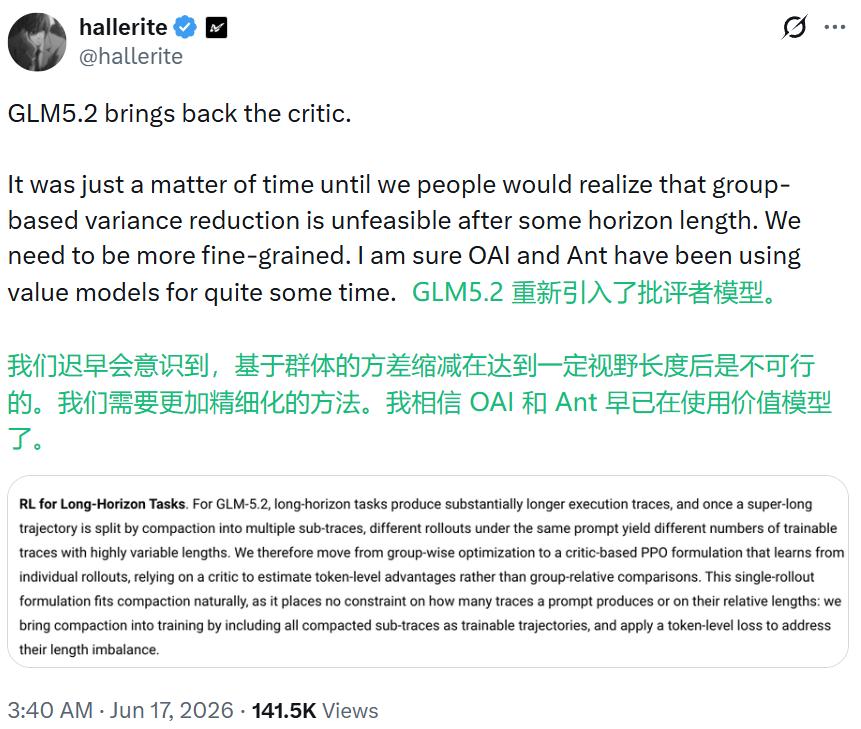
类似地帖子非常多,有人说自己在小规模项目里对比过 GRPO 和 actor-critic,结果 actor-critic 的表现明显更好;也有人怀疑,OpenAI 和 Anthropic 等前沿实验室在长程任务上本来就没有真正依赖过 GRPO,这只是长程任务迟早要撞上的一道墙;比如 @ethayarajh 就指出,曾被 NeurIPS 拒收的 PPO 这条路线其实更贴近强化学习圈子里常说的「苦涩的教训」(bitter lesson)——足够通用、能随计算量扩展的方法,往往比结构精巧但有适用边界的方法走得更远。

Xiuyu Li 提醒,一些长期做长程任务训练的团队,本来就从未真正全面采用过 GRPO,PPO 甚至 REINFORCE 一直是这些团队的底色。
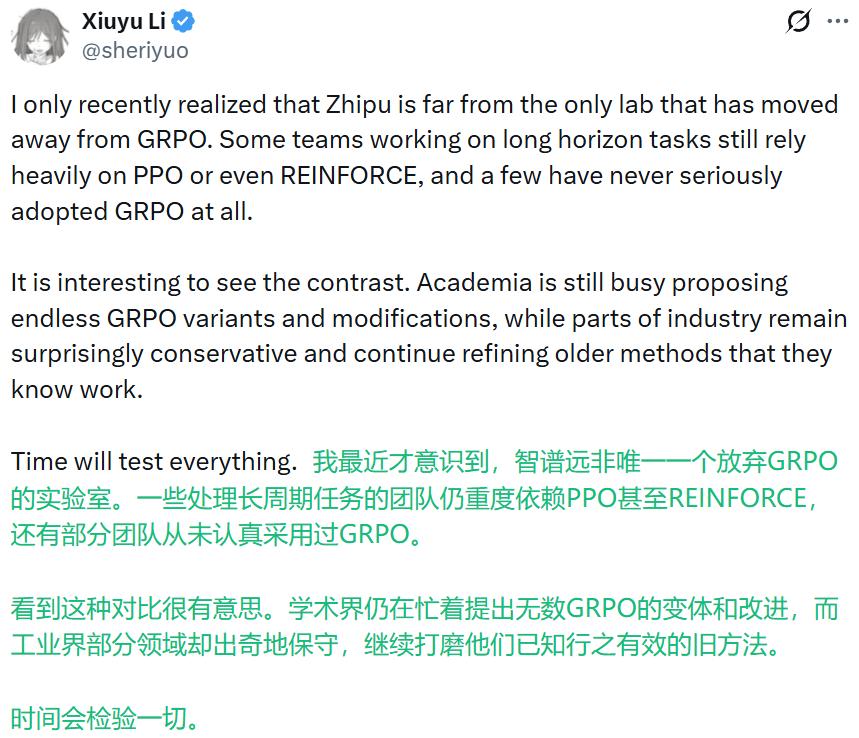
学术界则是另一幅景象:GSPO、DAPO、Dr.GRPO、GMPO、CISPO 等变体仍在源源不断地涌现,试图把 GRPO 在效率和稳定性上的毛病一个个打磨掉。
工业界悄悄回头,学术界继续往前冲。这个反差,很有意思。
智谱为什么换掉了 GRPO
要理解这次切换,得先弄清楚 GRPO 最初解决的是什么问题。
传统 PPO 需要一个价值网络(critic),专门预测「当前状态未来能拿多少奖励」,用来给每一步动作算优势值。这个网络和策略模型一样大,训练起来贵,也容易不稳定。
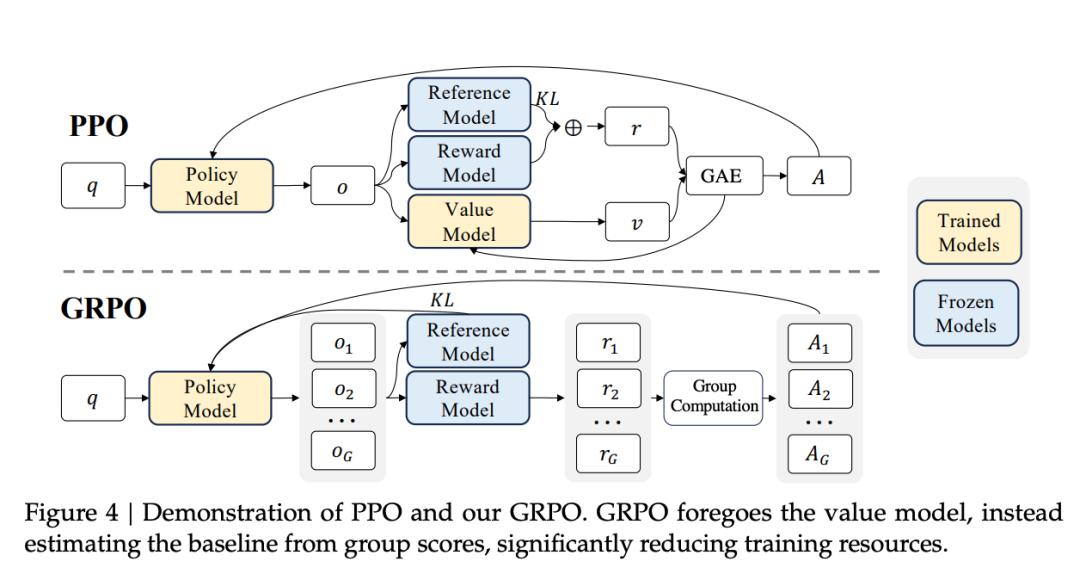
GRPO 的办法是:不训练这个价值网络了,改成让模型对同一个问题生成一组(通常是几十个)回答,拿组内平均奖励当基线,谁比组内平均分高,优势值就为正。这就像让同一道题的几十名学生同时交卷,再互相比较打分——不需要一个全知的阅卷老师,矮子里也能拔将军。
对数学题、单元测试这类有明确对错的短任务,这个办法省显存又稳定,DeepSeek-R1 之后几乎成了开源社区的默认选项。
GLM-5.1 的强化学习阶段,用的正是这套思路,组大小固定为 32。
但 GLM-5.2 瞄准的是另一类问题:长程智能体任务。根据智谱技术博客披露的内容,这类任务的执行轨迹远比解一道数学题长,涉及多轮工具调用、子任务拆解、跨多轮的环境反馈。一条轨迹经过压缩(compaction)处理后,子轨迹的数量和长度会变得参差不齐。
这正好打中了 GRPO 的软肋:它要求把同一个问题下的一组输出放在一起比较,可长程任务压缩出来的子轨迹长短不一,有的三言两语,有的拖了几十步,根本凑不成一组可以公平比较的样本。继续硬上组内比较,大量数据会变得没法用。
智谱给出的解法是:把价值网络请回来。GLM-5.2 的长程强化学习从「群体相对优化」转向了「基于 critic 的 PPO」,用 token 级别的优势值去适配长短不一的子轨迹——不再依赖一组同伴互相打分,而是重新训练一个能给任意一段轨迹独立估值的「阅卷老师」。
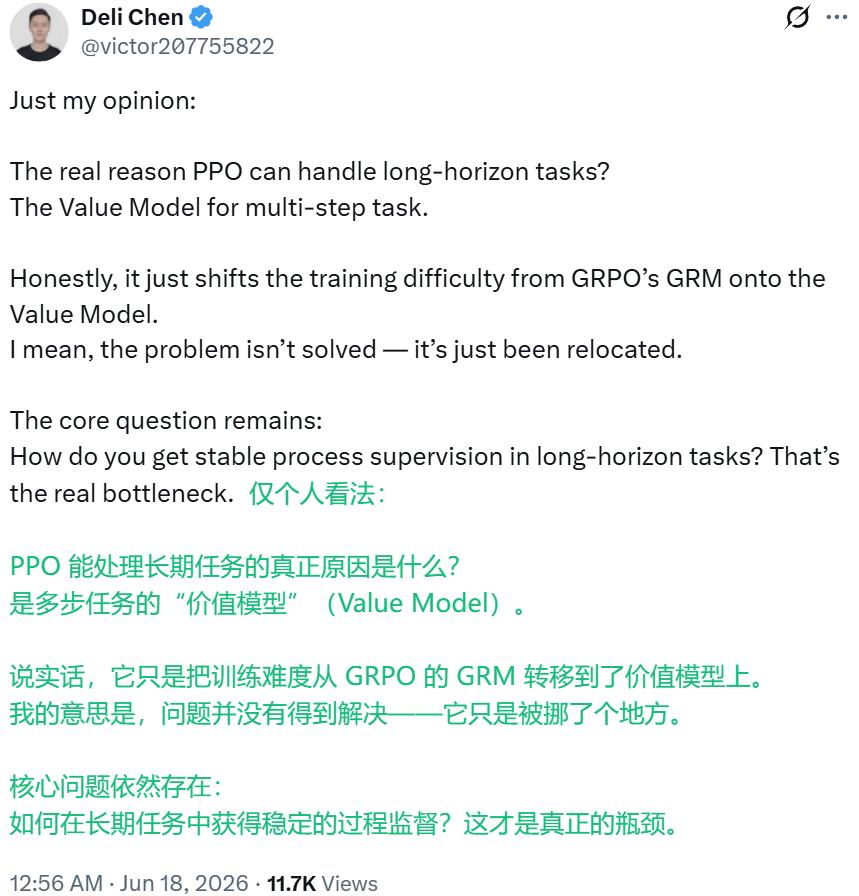
图源:DeepSeek 陈德里的推文
配合这次改动,智谱用 slime 框架把训练和大规模推理 rollout 打通,将十余个专家模型并行蒸馏合并进最终模型,整个过程只用了约两天。针对 coding 任务里常见的奖励作弊(比如直接 curl 拉取参考答案、grep 搜索隐藏测试用例文件),GLM-5.2 还引入了一套两阶段拦截机制,先用规则过滤,再用 LLM 裁判识别可疑工具调用,拦截后返回一段无意义的「假信息」,让训练轨迹继续走下去,而不是粗暴中断,以免引发训练不稳定。
简单说,GLM-5.2 并未否定 GRPO,而是发现 GRPO 的设计前提在长程智能体任务里站不住了。
GRPO 真的过时了吗
把这次切换简单总结成「GRPO 不行了」,可能是个偷懒的结论。
GRPO 当年能火起来,解决的是一个很具体的问题:在有明确对错的可验证任务上,用尽可能少的显存、尽可能稳定的方式做强化学习。这件事它依然做得很好。数学题、代码单元测试、格式校验这类短任务,答案就在那一组采样里,组内比较的成本优势依然成立。也因此,GSPO、DAPO 这些变体还在持续打磨 GRPO 在 MoE 训练、长思维链场景下的毛刺,而不是直接宣布它退场。
一个更能说明问题的例子是 GRPO 的提出者自己。今年 4 月发布的 DeepSeek V4 技术报告显示,DeepSeek 在训练数学、代码、Agent、指令跟随等分领域专家模型时,用的依然是 GRPO,只是在把多个专家合并回一个统一模型时,换成了一种叫「在策略蒸馏」(On-Policy Distillation)的新方法。
GLM-5.2 换掉的其实是 GRPO 在另一类任务(多轮、长程、奖励稀疏且延迟的智能体任务)上的适用性。这类任务里,「这一步做得好不好」往往要等到几十步之后才能从最终结果反推回来,而且任务跑出来的轨迹长短千差万别,很难找到一组「条件相同」的样本去做组内对比
这个判断不只是工业界这一轮的经验之谈,学术界也有对照实验支持。
去年底一篇题为《Learning Without Critics? Revisiting GRPO in Classical Reinforcement Learning Environments》的论文专门做过测试:在没有提前终止机制的长程任务里,不带 critic 的方法持续比不过带学习到的价值函数的 PPO;只有像 CartPole 这种短程任务,组内比较的方式才能打平。

这个结论和 GLM-5.2 这次的选择,算是从工业实践和学术实验两个完全不同的方向,得出的同一个判断。
所以更准确的说法可能是:强化学习算法的选择,正在变得任务相关,而不再有一个放之四海而皆准的「默认选项」。
短程可验证任务,GRPO 及其变体依然够用、依然便宜。长程智能体任务,价值网络重新变得重要。
GLM-5.2 引发的讨论之所以有分量,是因为它把这道分界线第一次摆在了公开的技术博客里,让一个本来只停留在小圈子传闻里的判断(前沿实验室可能压根没指望靠 GRPO 走到长程任务),有了一个开源、可复现、可供外界验证的对照样本。
结语
过去两年,GRPO 几乎成了开源大模型强化学习阶段的代名词,一种「便宜又好用」的默认信仰。GLM-5.2 的选择提醒人们,这种信仰本身是有边界的——它诞生于数学题和单元测试的世界,而现在的智能体正在被推向需要连续工作几小时甚至更久的真实任务。
对整个行业而言,这次切换的意义可能超过 1M 上下文或者基准分数本身。它说明,随着开源模型从「答题选手」走向「干活的智能体」,后训练阶段的算法选型也要跟着任务形态一起进化,而不能停留在某一篇论文定下的范式里。
下一次范式松动会发生在哪里,没有人能提前给出答案,但可以确定的是,这场关于强化学习未来走向的争论,才刚刚开始。
