

机器人模型已经能根据“把杯子放进篮子”这类指令完成任务,但用哪只手?
从哪个方向抓?抓杯身还是杯柄?——这些决定执行效果的关键细节,现有机器人数据集较少标注。

近日,来自香港大学XLANG Lab和阿里巴巴Qwen团队的研究人员提出了FineVLA,一个面向可控VLA策略的开源框架。
该框架让VLA模型不仅能完成任务,还能按照人类指定的方式完成任务——
用哪只手、从哪个角度接近、接触物体的哪个部位,都可以通过语言进行控制。
其最佳混合策略设置在RoboTwin仿真中达到86.8%/82.5%的成功率(比基线提升+15.0/+11.1),在真实双臂机器人上达到62.7/100(Raw-only为49.9),姿态(+23)、颜色(+18)、接近方向(+18)等可控因素均有提升。代码、模型和评测基准均已开源。
背景:VLA 模型为什么还不够”听话”?
VLA(Vision-Language-Action)模型已能根据自然语言完成抓取、放置等操作,但一个长期痛点仍然存在:语言监督粒度太粗。
在图像生成和视频生成中,文字描述的细节会直接影响结果可控性;机器人策略学习也类似,只是语言需要约束真实动作过程。
同样是把勺子拿起来,不同轨迹可能用左臂或右臂、绕过障碍物或直线移动,但在数据集中往往共享同一条目标级指令。
这会带来监督歧义:模型能学到“最终要成功”,却难以从语言中学到使用哪只手、从哪个方向接近、接触物体哪个部位等执行约束。
目前多数机器人数据集仍缺少这种细粒度标注。
构建可控VLA系统面临三个核心挑战:
- 缺乏从异构数据到细粒度标注的基础设施;
- 缺乏评测机器人细粒度理解的基准和可扩展低成本标注器;
- 缺乏细粒度语言是否真的提升策略学习的系统性证据。FineVLA框架逐一解决这三个问题。
技术方案
FineVLA构建了一个动作-指令对齐的完整闭环,连接细粒度数据构建、机器人视频理解、可扩展标注和可控VLA策略学习。
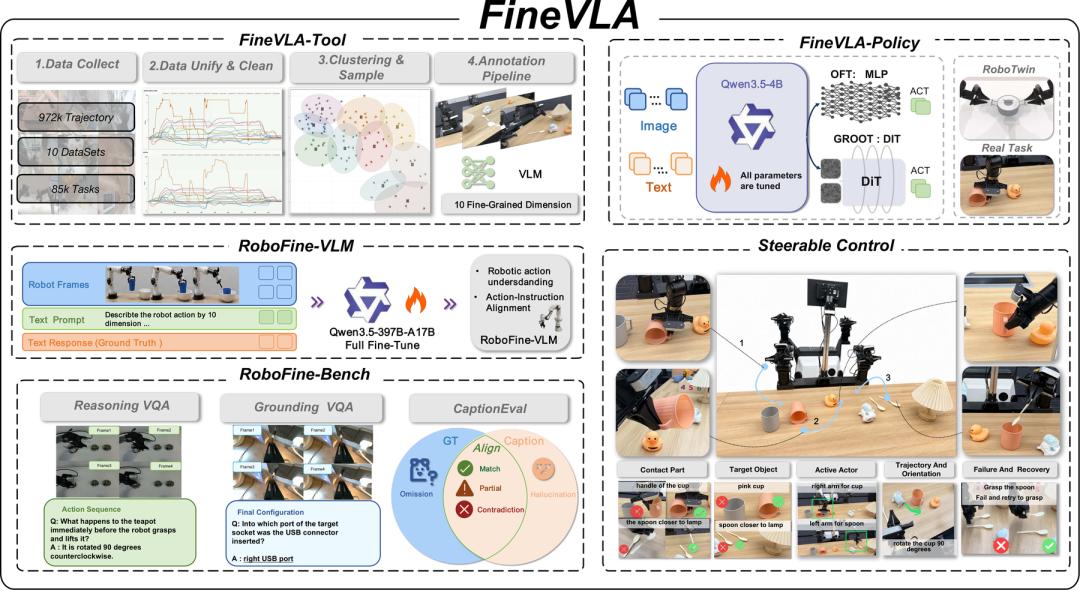
左侧:FineVLA-Tool从10个开源数据集统一异构机器人轨迹,通过聚类采样去除冗余演示,并沿十个细粒度维度为代表性轨迹标注动作对齐描述。
生成的FineVLA-Data支持RoboFine-Bench(通过Grounding VQA、ReasoningVQA和Caption评测衡量细粒度机器人视频理解)和RoboFine-VLM(面向机器人的专用VLM标注器)。
右侧:FineVLA-Policy使用原始目标级指令与细粒度过程级指令的混合数据,在两种动作解码架构下训练,并在RoboTwin仿真和真实双臂操作中评测。
可控控制示例展示了细粒度语言如何指定接触区域、目标物体、执行臂、轨迹方向和失败恢复等执行敏感因素。
FineVLA由四个核心组件构成,形成”数据—模型—评测—策略”的完整闭环。
FineVLA-Tool:97万条轨迹到细粒度数据
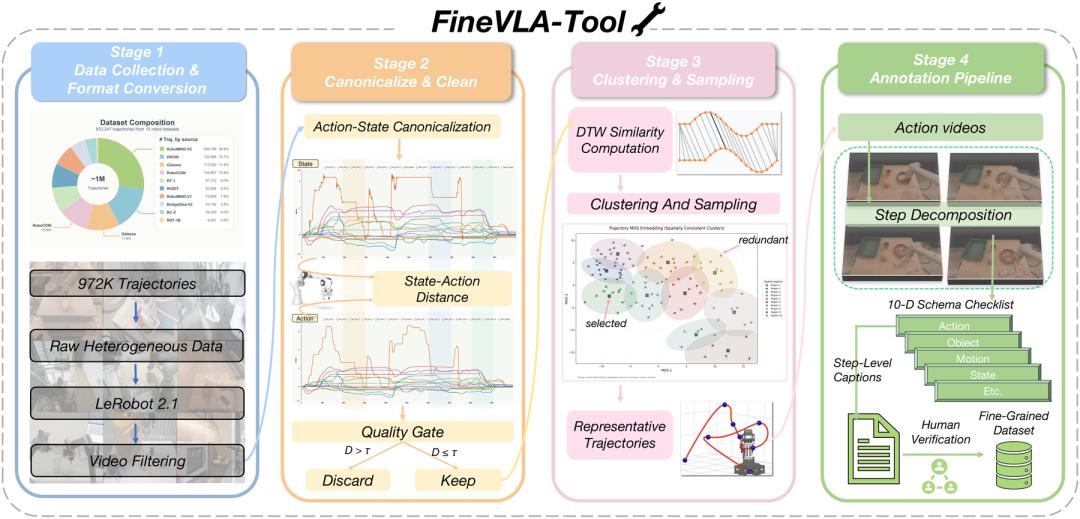
FineVLA-Tool通过四个阶段将异构机器人数据转化为高质量细粒度监督:
- 阶段一,格式统一:从Bridge V2、BC-Z、RT-1、RoboMIND等10个开源数据集汇总972247条轨迹,统一转换为LeRobot2.1格式。
- 阶段二,动作规范化:将不同数据集各异的时间参考和运动学表示统一为绝对坐标+归一化四元数旋转,移除动作和状态差距过大的损坏轨迹。
- 阶段三,DTW聚类去重:基于动态时间规整(DTW)计算动作轨迹相似度并层次聚类,从97万条中筛选出47159条代表性样本,保留操作策略多样性。
- 阶段四,十维细粒度标注:按动作序列、执行体(左/右臂)、目标物体、接触与接近方式、轨迹方向、失败恢复等10个维度标注。先由Qwen3.5-Plus生成,再经人工审核验证。标注后平均词数从9.3增至96.8(10.4倍)。
RoboFine-VLM:让VLM学会描述机器人”怎么动”
通用VLM常漏掉物体歧义区分、接触区域、运动路径等执行细节。研究人员进一步对Qwen3.5-VL-397B-A17B进行全参数监督微调,并基于前述人工验证的细粒度指令得到RoboFine-VLM,能输出覆盖10个控制维度的步骤级动作描述,作为未来数据扩展的可扩展标注器。
RoboFine-Bench:评测细粒度动作理解
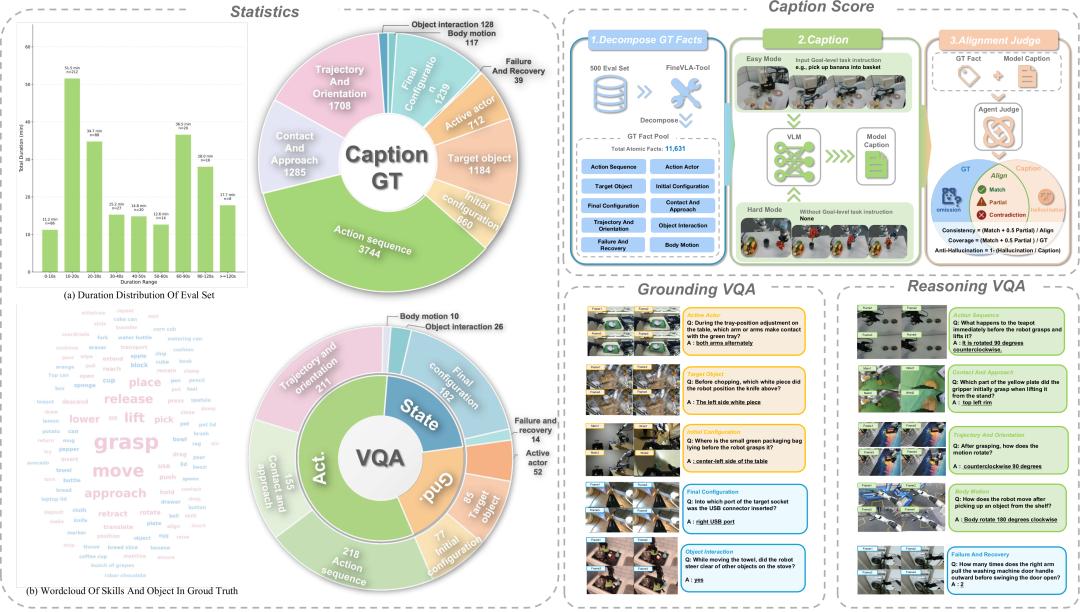
RoboFine-Bench包含500段视频、32种机器人形态和11631个原子事实,与训练集严格不重叠,设有两个轨道:
- VQA轨道:包含1030道问题,沿标注的十个细粒度维度分布,汇聚为三个评测轴——实体与场景定位(Grounding)、动作与运动理解(Action)、交互与状态推理(State)。模型接收视频帧和全部问题,答案通过确定性匹配评分。
- Caption轨道:要求模型生成动作对齐的步骤级细粒度描述,由LLM评判模型输出与预提取的11631个原子事实的对齐程度,产出一致性(Consistency)、覆盖率(Coverage)和反幻觉(Anti-Hallucination)三项指标。设有两种模式:easy模式提供原始任务指令作为提示,hard模式则要求模型仅从视觉观察推断操作过程,不提供任何语言线索。
FineVLA-Policy:验证细粒度语言的策略收益
保持视觉观察和动作标签不变,仅改变配对语言(Raw-only vs FG-only vs Mixed),严格隔离语言监督效果。
为系统验证细粒度标注的有效性,实验设计了三种策略配置以分离架构与数据规模的影响:RDT-OFT与RDT-GR00T使用相同预训练数据、不同动作解码架构(OFTvsGR00T),RDT-OFT与AlohaMix-OFT使用相同架构、不同规模预训练数据(AlohaMix约为RDT的13倍)。
每种配置均在七种FG:Raw指令比例下评估,确保结论不受特定架构或数据规模的影响。
实验结果
模型理解能力
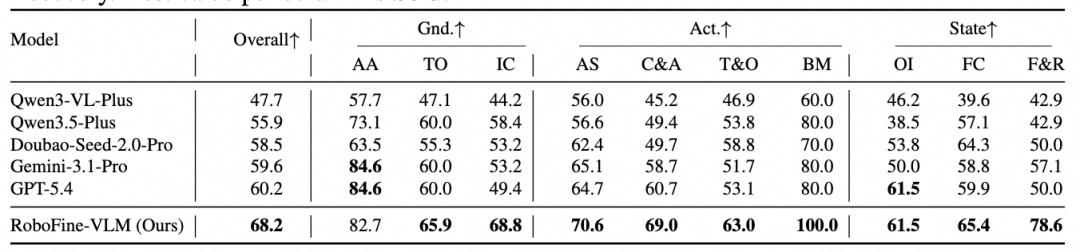
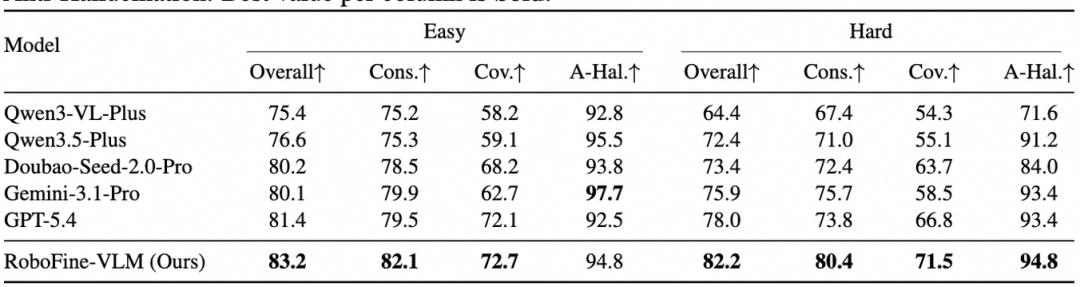
RoboFine-VLM在VQA轨道取得68.2%准确率,超过最强通用基线GPT-5.4(60.2%)+8.0个百分点;
Caption hard设置下得到82.2%,超过GPT-5.4(78.0%)。自动评分与人工排名高度一致(Spearman 0.943)。
仿真实验 RoboTwin
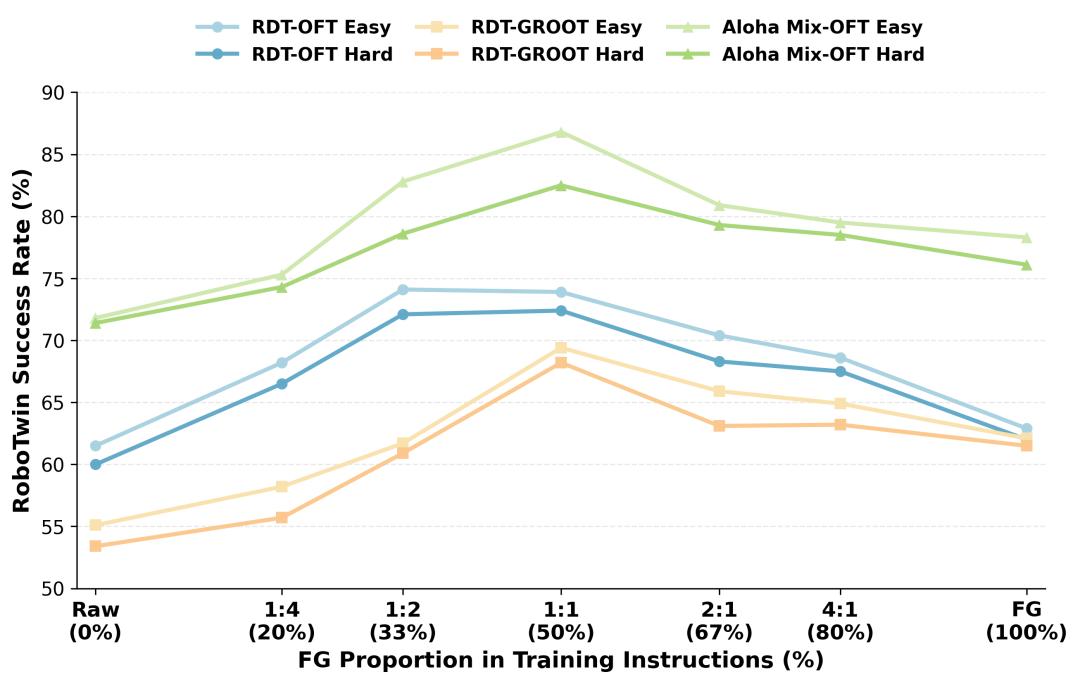
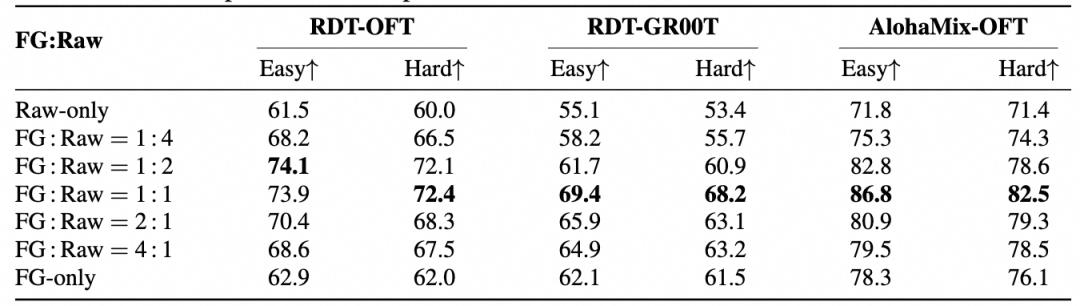
在RoboTwin上评估七种FG:Raw比例,揭示两个关键发现:
发现一:FG-only在所有设置中均优于Raw-only(增益+1.4到+8.1)。细粒度监督不损害任务成功率。
发现二:成功率呈倒U型趋势,峰值在FG:Raw=1:2到1:1。
最佳设置达86.8%/82.5%,比基线+15.0/+11.1。Raw告诉模型”做什么”,FG告诉模型”怎么做”,两者互补。
真实机器人实验

在CobotMagic双臂平台上,研究团队设计了”配对评测”:同一视觉场景下,仅改变一个语言控制因素,观察策略是否按指令改变执行方式。下表为论文原文中的真实世界评分结果,所有分数均归一化到100分。
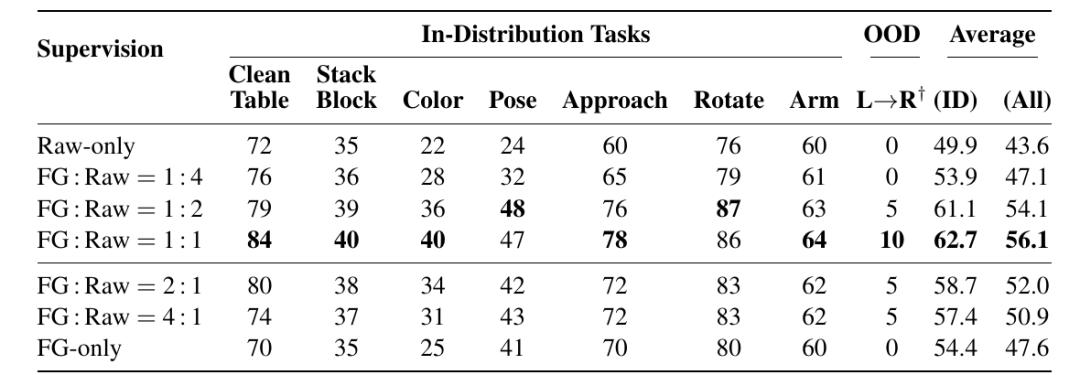
表中Avg(ID)表示7个in-distribution任务的平均分,Avg(All)进一步计入OOD L→R组合探针。FG:Raw=1:1在Avg(ID)上达到62.7/100(Raw-only为49.9,FG-only为54.4);计入OOD后,Avg(All)为56.1(Raw-only为43.6)。
在具体控制因素上,FG:Raw=1:1相比Raw-only在颜色(22→40)、姿态(24→47)、接近方向(60→78)、旋转方向(76→86)和执行臂(60→64)上均有提升。较大增益集中在目标级指令未指定的因素上:姿态(+23)、颜色和接近方向(各+18)。OOD L→R要求机器人使用左手将物体放入右侧碗中,是训练中未见过的actor-target组合;该项从0提升到10/100,提示混合细粒度监督带来一定的因子级泛化,但完整的组合式指令仍然具有挑战。
此外,细粒度监督还展现出scaling趋势:缩小架构差距(OFT vs GR00T的Easy/Hard差距从6.4/6.6降至0.8/0.5),且在更大数据规模下获益更多。
项目价值
FineVLA的核心贡献不是给数据加更长描述,而是重新定义了VLA学习中的语言监督粒度,并给出了明确结论:细粒度语言应当增强而非替代目标级指令。
该框架为社区提供了四个可复用方向:
- 数据层:从异构数据到细粒度标注的完整构建流程
- 模型层:用于可扩展机器人视频细粒度标注的RoboFine-VLM
- 评测层:用VQA和Caption衡量VLM对机器人视频理解与标注的RoboFine-Bench
- 策略层:验证混合训练提升可控性的训练配方
机器人若要进入开放环境,仅听懂目标不够——它还必须听懂人类对”怎么做”的要求。
相关链接论文地址:https://arxiv.org/abs/2605.27284
项目主页:https://finevla.xlang.ai/
GitHub 仓库:https://github.com/xlang-ai/FineVLA
评测基准:https://huggingface.co/datasets/xlangai/RoboFine-bench
标注模型:https://huggingface.co/xlangai/RoboFine-VLM-397B-A17B
作者团队:Xintong Hu、Xuhong Huang、Jinyu Zhang、Yutong Yao、Yuchong Sun、Qiuyue Wang、Mingsheng Li、Sicheng Xie、Yitao Liu、Junhao Chen、Yixuan Chen、Yingming Zheng、Shuai Bai、Tao Yu†。* 共同第一作者;† 通讯作者。来自香港大学 XLANG Lab、阿里巴巴Qwen团队两家机构。
