

长程(Long-Horizon)任务,是当前AI Agent亟需突破的难题之一。
在软件工程、科学研究和复杂决策等场景中,Agent 往往需要在长程条件下连续决策,任何一步失误都可能影响后续任务。过去,这类能力往往依赖更大的模型;扩展 Agent Horizon也是另一个重要方向,但一直面临基础设施不足和异构能力难以统一的问题。
针对这些问题,上海AI Lab 团队推出了一个 35B 参数大小的MoEAgent 模型——Agents-A1,试图不靠继续堆参数,仅通过扩展 Agent Horizon,用更小的模型逼近万亿参数级模型的长程表现。

论文链接:https://arxiv.org/abs/2606.30616
研究结果显示,Agents-A1 在多步搜索、科学研究和长指令遵循等部分任务上,已经展现出超过部分万亿参数级模型的表现,并在 35B 同规模模型中保持领先。
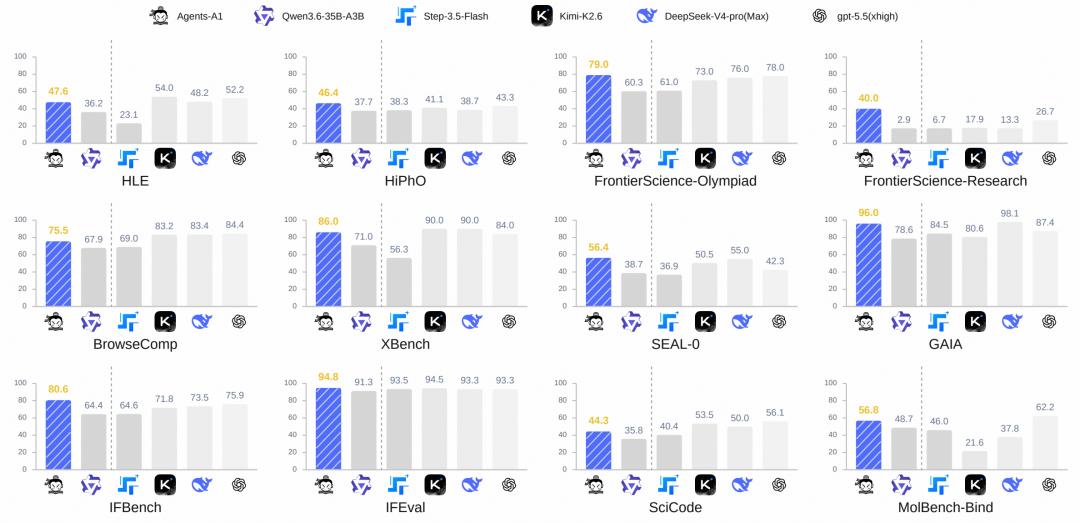
图|Agents-A1 的基准测试表现。
不过,研究团队也表示,Agents-A1 在工程类任务上仍与前沿大模型存在差距。
这项研究提出了一种更经济的强大AI Agent开发方法:教它们养成更持久的、经过验证的工作习惯,而不仅仅是扩大它们的参数规模。
Agent- A1 是如何设计的?
Agents-A1 是一个面向长程任务的 35B 参数 MoE Agent 模型。它依托长程知识-动作基础设施,通过三阶段训练把多种 Agent 能力整合进同一个模型:先进行全领域 SFT,再专门训练各领域教师,最后通过多教师 on-policy distillation(OPD)完成统一。具体流程如下:
1.全领域监督微调(SFT)
该阶段旨在建立模型的通用 Agent 能力。研究团队使用多领域、多任务的高质量长程轨迹数据进行训练,增强模型在长上下文条件下的理解、推理和指令遵循能力;训练中采用 sample packing,将多个较短样本拼接到单个训练序列中,并配合注意力掩码防止样本间串扰,从而减少 padding 开销、提升 GPU 利用率。
2.领域级教师模型训练
研究团队将模型能力拆分为搜索、科学推理、指令遵循和工具调用四类专长教师,分别设计训练方案。
- 搜索教师:采用“先 SFT、后 RL”的两阶段训练,并结合 GRPO 提升复杂问题拆解、多跳搜索和工具协同能力,目标是在保证正确率的同时减少冗余搜索。
- 科学教师:通过两阶段 SFT,先强化科学推导能力,再通过工具增强轨迹训练外部交互和证据整合能力。 让模型学会何时借助外部工具,并整合检索或计算得到的证据。
- 指令遵循教师采用:采用两阶段 RL 和 GRPO 训练:第一阶段提升格式、长度、关键词和语言等细粒度约束满足能力;第二阶段强化长上下文 ICL 中的证据定位、信息整合和上下文规则遵循能力。
- 工具调用教师:采用工具 SFT 与工具 RL 的两阶段优化,重点学习何时调用工具、如何纠错以及何时结束任务,并结合结果奖励、过程奖励和高质量困难任务复用提升工具使用能力。
3.统一模型阶段
研究团队先收集学生轨迹,再由对应领域教师打分指导。与离线模仿不同,教师直接评估学生自身生成的轨迹。最终,模型通过按领域路由的蒸馏和显著词汇对齐,兼顾全领域 SFT 的广泛能力与各领域教师的专长。
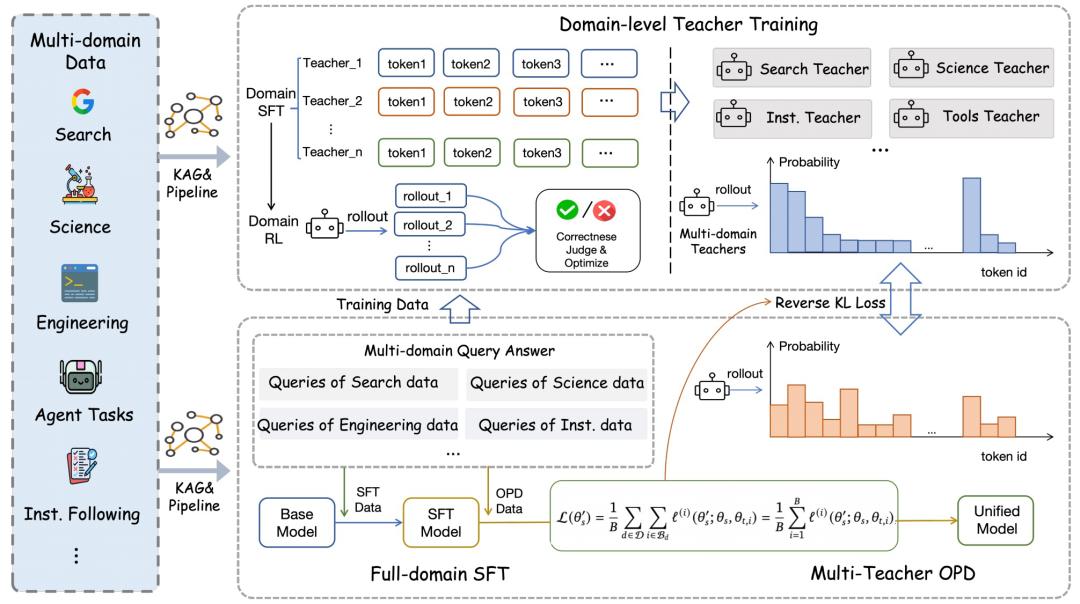
图|Agents-A1 三阶段训练流程概览。
为支撑这一训练流程,研究团队构建了以知识-动作图 KAG为核心的知识-动作基础设施,并通过自博弈不断扩展高质量长轨迹数据。这样训练样本不仅包含问题和答案,也能完整保留工具使用与验证过程。
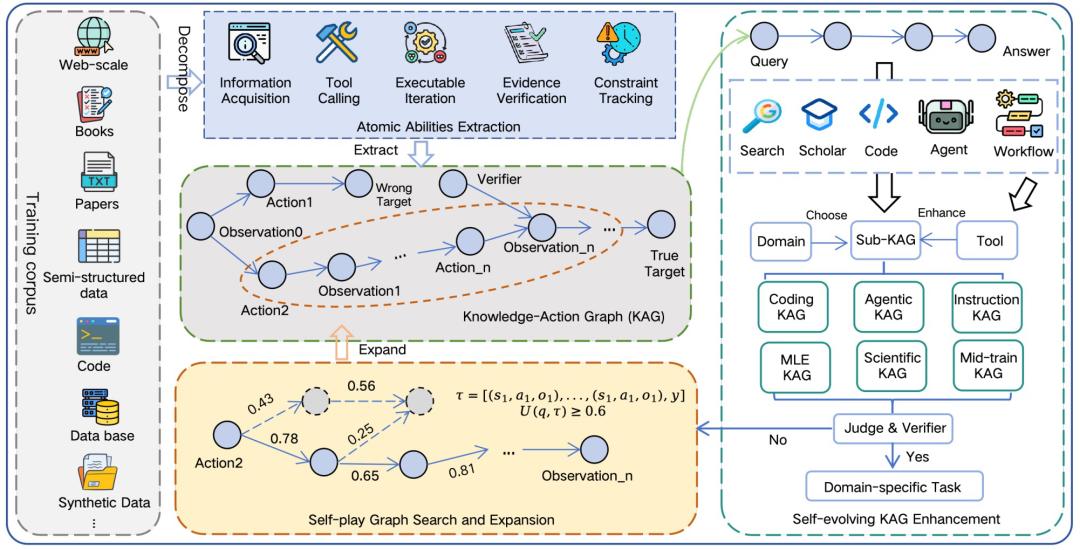
图| Agents-A1 的知识-动作基础设施概览。
实验结果
整体来看,Agents-A1 在长程搜索、指令遵循和科学推理等任务上表现突出,不仅领先同规模 35B 模型,也在部分基准上超过了部分万亿参数级模型。具体结果如下:
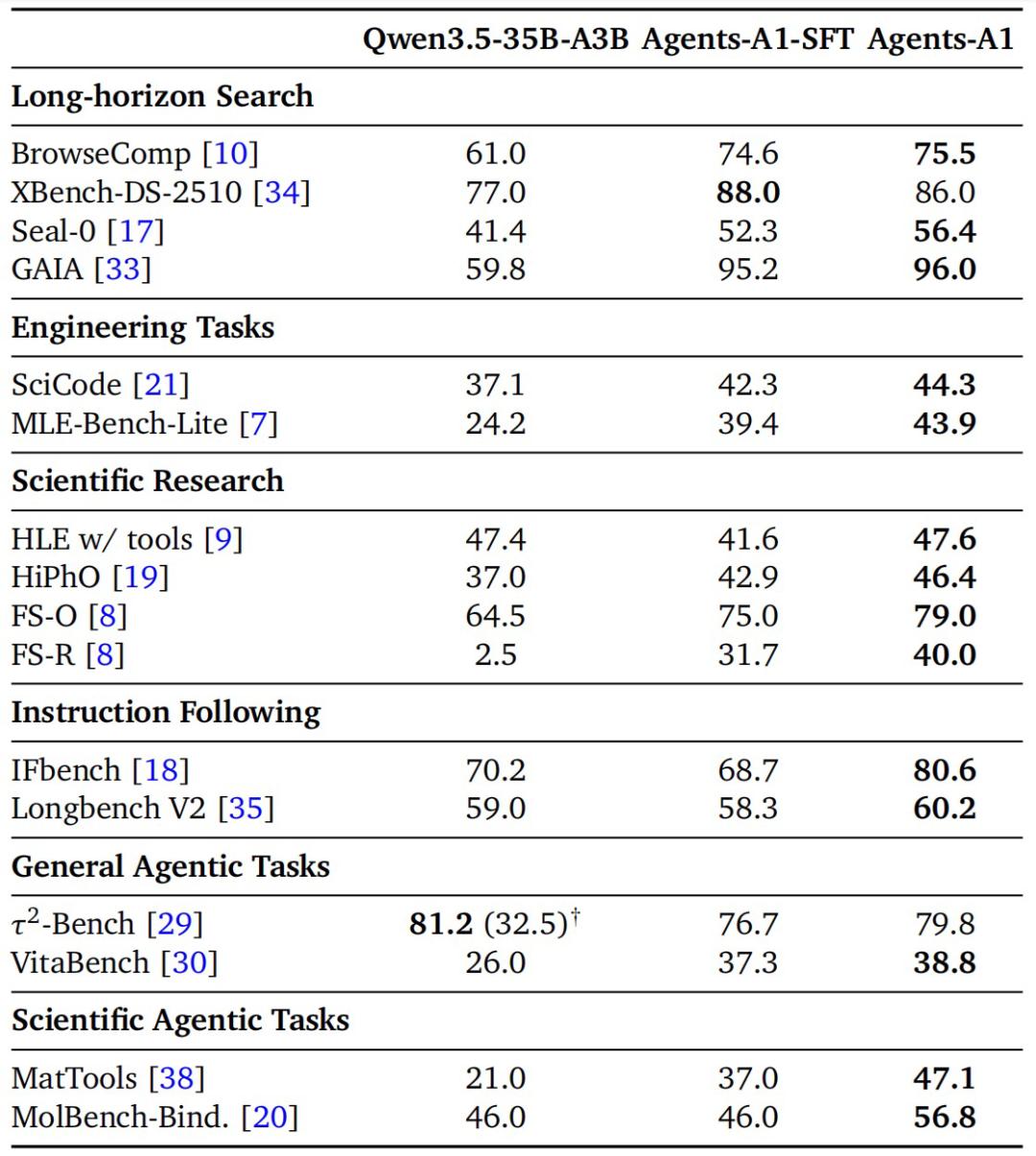
图|Qwen3.5-35B-A3B、Agents-A1-SFT 和 Agents-A1 的性能对比。
1.全领域 SFT
结果显示,Agents-A1-SFT 在长程搜索、工程任务和科学研究等方向上明显提升,但在通用 Agent 任务、指令遵循和 HLE 上出现回落。这也说明,仅靠全领域 SFT 还难以缓解不同推理模式之间的冲突。
2.领域教师模型训练
搜索增强教师:在四个基准上都稳定优于 Qwen3.5-35B-A3B。尤其在通用AI 助手基准 GAIA 上提升最为明显,数值从 59.8 提升到 95.1。

图|Qwen3.5-35B-A3B 与搜索增强教师模型的性能对比。
科学增强教师:两阶段 SFT 显著增强了教师模型的科学推理和工具交互能力;相较基线模型,科学增强教师在各项科学任务上整体更优,尤其在 FS-R 上实现了从 2.5 到 54.3 的大幅提升。

图|Qwen3.5-35B-A3B 与科学增强教师模型的性能对比。
指令遵循与长上下文学习实验:强化学习显著提升了模型的长上下文理解、指令遵循及对可验证指令约束的泛化能力。总体上,RL 增强教师在相关评测中优于 Qwen3.5-35B-A3B,其中 LongBench V2 和 IFBench 的提升尤为明显。
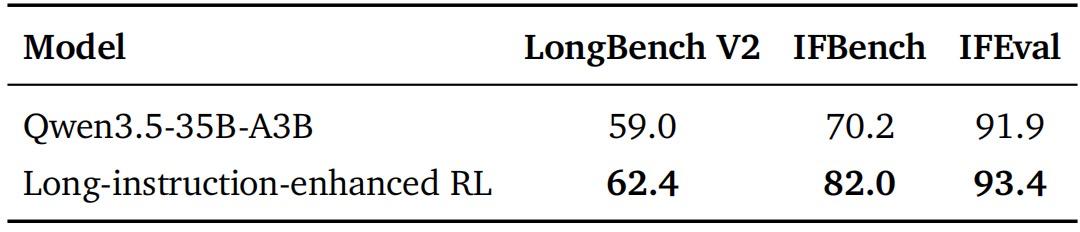
图|Qwen3.5-35B-A3B 与 RL 增强教师模型在 LongBench V2、IFBench 和 IFEval 上的评测结果。
工具调用实验:显式工具使用监督与强化学习显著提升了模型的工具调用能力,尤其在需要多轮、结构化交互的任务中效果更明显;具体而言,工具增强模型在 τ²-Bench 和 VitaBench 上均取得了显著提升。

图|Qwen3.5-35B-A3B 与工具增强 RL 教师模型在 τ²-Bench 和 VitaBench 上的性能评测结果。
统一模型实验:结果表明,多教师 OPD 较单纯的全领域 SFT 更能缓解不同任务推理模式之间的冲突,在保留广泛能力覆盖的同时,更好地整合各领域专长,并进一步提升长程任务表现。
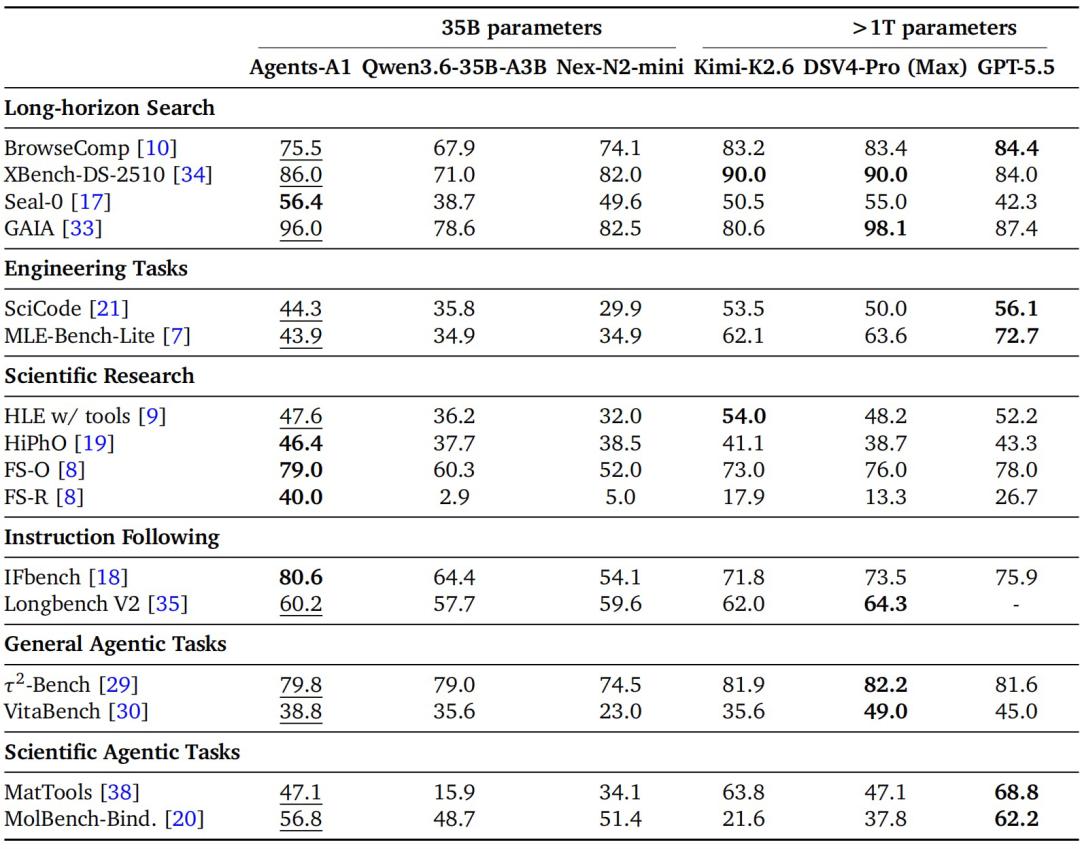
图|Agents-A1 与 35B / 1T 级模型的对比。
除标准基准外,研究团队还通过两个案例展示了 Agents-A1 的长程 Agent 能力。以鲸鱼叫声检测任务为例,Agents-A1 已经能够在较长时间跨度内持续优化完整机器学习流程。模型在一次 12 小时运行中从简单 CNN 基线出发,将验证集 AUC 从 0.58 提升至 0.9935。这表明,Agents-A1 已超越局部调参,具备在多轮迭代中持续改进方案并提升泛化能力的能力。
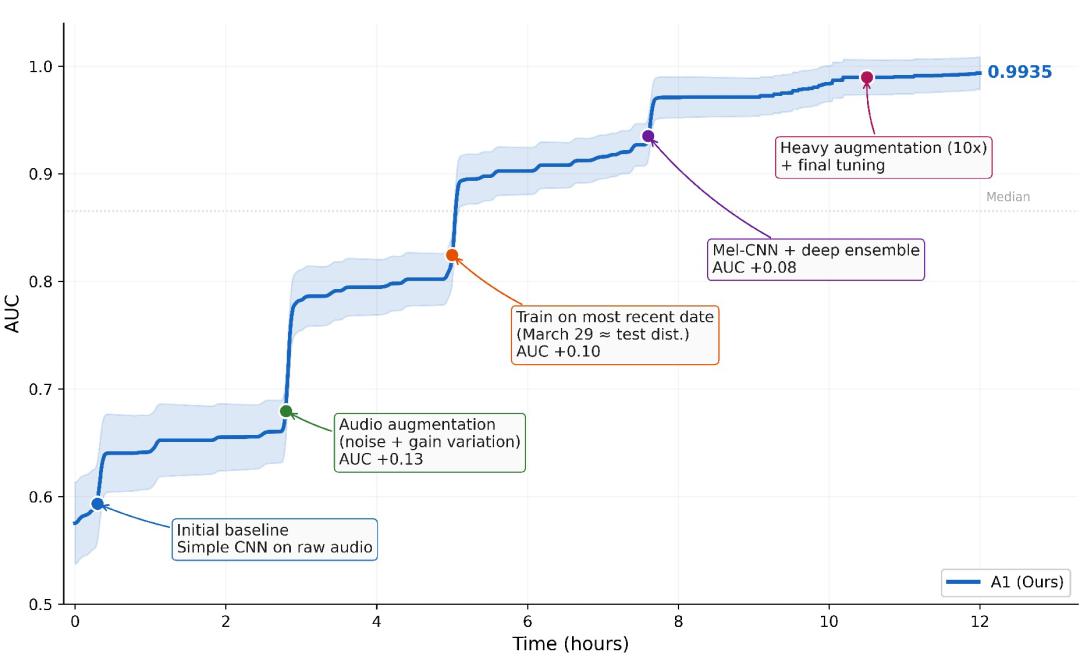
图|Agents-A1 在 ICML 2013 Whale Challenge 上一次 12 小时运行中的优化轨迹。
Agents-A1在地球科学任务中也具备较完整的端到端分析能力。以 2008 年热带气旋 Nargis 为例,模型能够自动识别数据源,并完成数据提取、清洗、派生指标计算、可视化和结果综合,形成从规划到报告生成的多阶段闭环,同时较高保真度地重建了风暴演化过程。
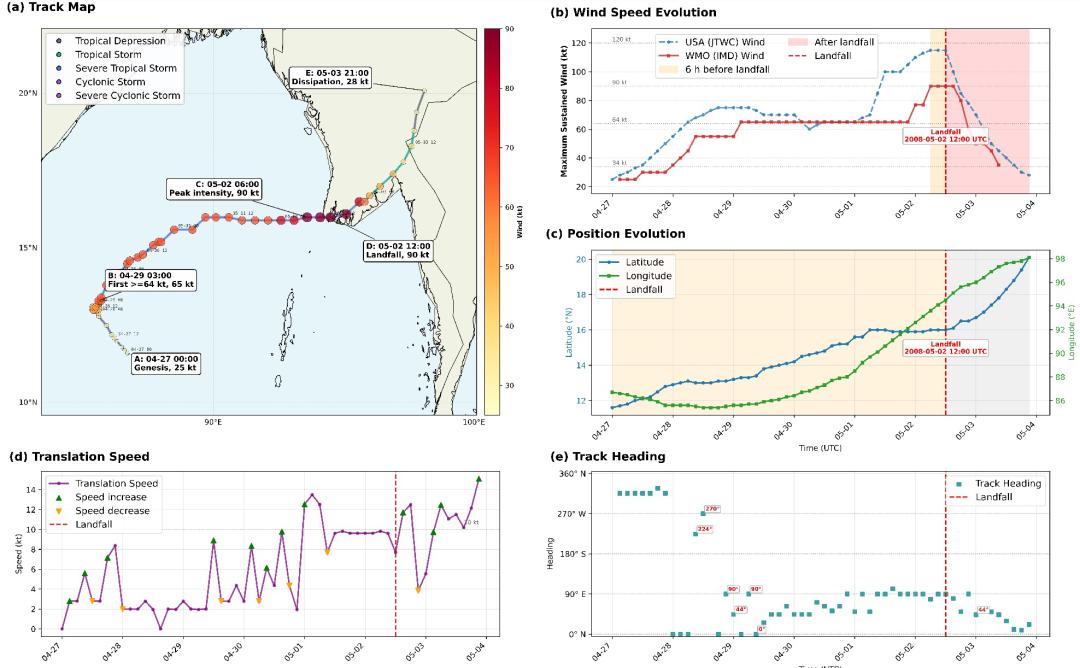
图|由 Agents-A1 生成的 2008 年热带气旋(Nargis)的路径。
不足和未来方向
尽管Agents-A1在多项长程任务上表现较强,但仍存在一些不足。具体如下:
首先,模型在“先规划再推理”“先反思再行动”、长上下文关键信息总结和重要历史信息识别等基础原子能力上仍有提升空间,这些能力会直接影响长程任务中的稳定性、目标一致性与执行效率。未来,需要重点强化这些基础能力,并以此进一步提升 Agents-A1 的长过程求解能力。
其次,在机器学习工程任务上,Agents-A1 与更大模型之间仍有明显差距。未来,如何增强模型在完整工程流程中的目标一致性、决策记忆与试验效率,仍是一个重要研究方向。
最后,经过 OPD 训练的统一学生模型,并不能在所有领域都稳定超过对应的教师模型。未来,如何在模型统一性与领域专长之间取得更好平衡,仍是后续需要解决的问题。
更多技术细节,详见原论文。
