


新智元报道

【新智元导读】全硅谷都在拼命卷AI,最后赚翻的是裁判!伯克利团队搞的免费擂台Arena,不造AI只靠「卖水」,8个月狂揽1亿美元营收,估值直接冲破17亿大关。
一个不造AI的公司,年入1亿美元!
缔造这一商业神话的,是硅谷AI巨头争相角逐的「大模型擂台」——Arena。
它的前身叫Chatbot Arena,最初仅仅是UC伯克利团队,在2023年发起的一项开源研究项目。

谁能想到,短短时间,它就成了拿捏大模型命脉的核心阵地。
就在今天,在Arena商业化服务上线仅仅8个月后,年化营收达到了1亿美元,创下新里程碑。
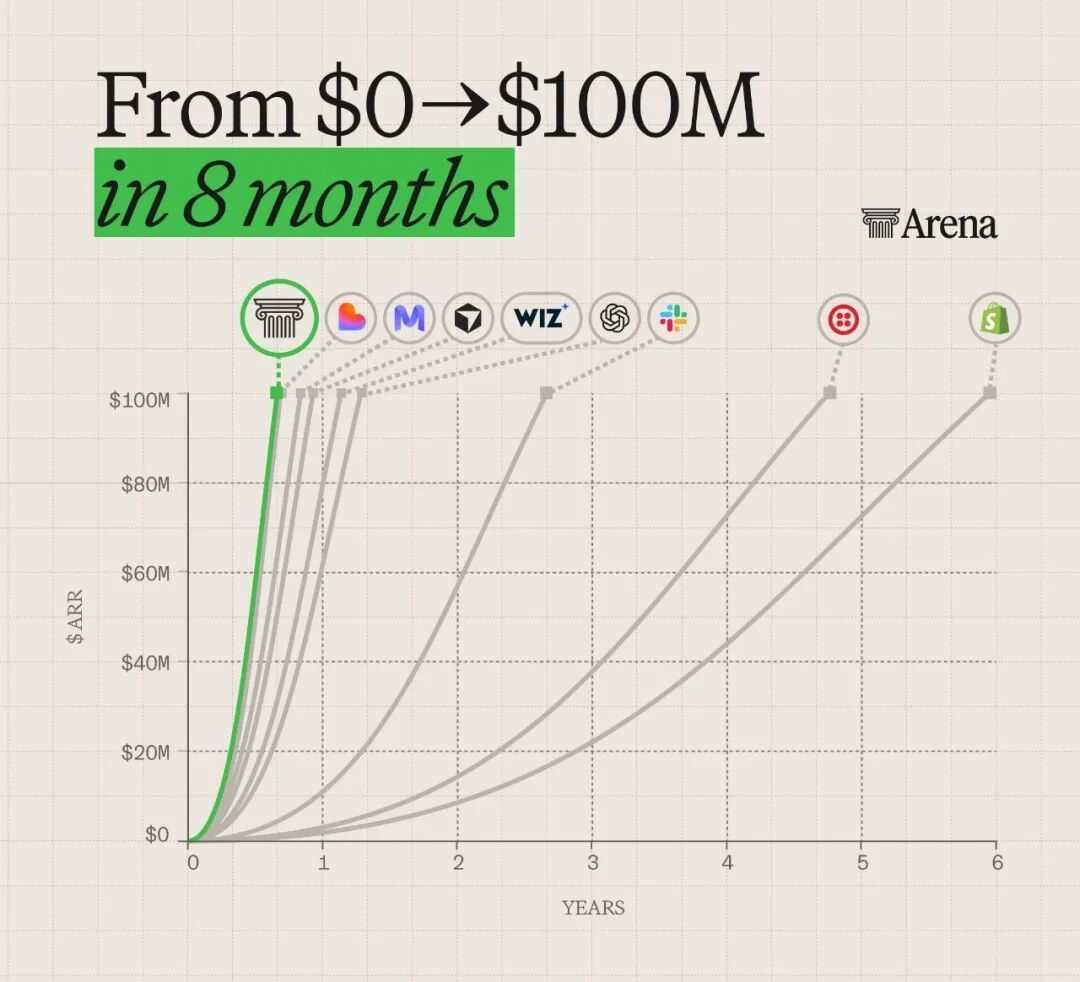

ChatGPT、Claude刷榜,大模型擂台
对很多人来说,Arena并不陌生。
它最为人津津乐道的,就是那个完全靠用户真实盲测堆出来的大模型排行榜。
玩法简单到极致,却又充满竞技感——
输入一段提示词,系统盲测派出两个匿名模型同时作答;然后选出哪个更好。
系统把千万张这样的选票,汇成一张Elo式的排行榜。
就这么个「打擂台」的机制,让它成了全球AI爱好者和开发者的圣地。
到今天,平台已经攒下超过1000万次用户评测,7亿次对话,8200万张投票,每月1000万+访客,来自全球150多个国家。
更关键的是,每天约80%的用户提问都是全新的,没有任何模型能提前「背题」。
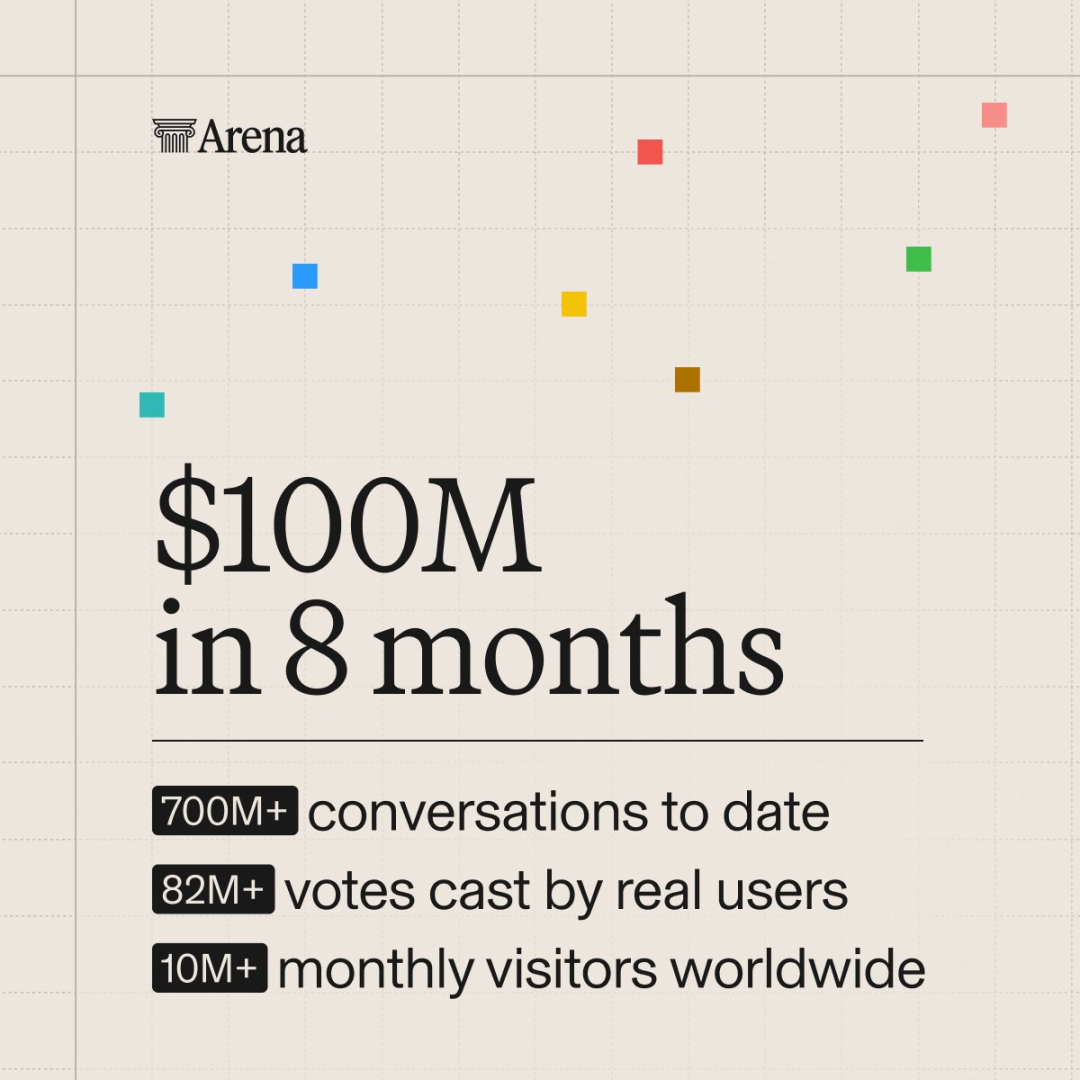
含金量有多高?
OpenAI、谷歌、Anthropic、Meta,这些平时打得头破血流的顶级大厂,全都把自家旗舰模型送上Arena接受社区拷打。
OpenAI甚至在GPT-5正式发布前,用代号「summit」偷偷上榜测试。
换句话说,全硅谷最强的那批模型,都在等一个伯克利学生的项目给它们盖戳。
1亿美金营收,怎么跑出来?
那么问题来了——一个免费排行榜,怎么就成了1亿美元的吸金兽?
去年9月,Arena上线了一款AI Evaluations的商业服务:
模型厂商和大企业可以付费,让Arena调动它那个数千万人的社区,对自家模型做深度评测,拿到光靠跑分根本得不到的「真实世界」性能分析。
这是一套「面向真实世界的CI/CD系统」。
模型一旦准备公开发布,Arena会免费替社区把它评测一遍;
而企业想知道自家模型在真实用户手里到底强在哪、弱在哪、哪里在胡说八道,那就得掏钱。
这是一种典型的「卖水人」生意——淘金热里,挖金子的不一定赚钱,但卖水、卖铲子的稳赚不赔。
大模型厂商越是疯狂内卷、越是拼命想榨出最后一点性能,对这种「上线后调优」服务的胃口就越大。
而Arena恰好卡在了所有人都必须经过的那个位置上。
三个伯克利人
做出最赚钱的生意
Arena的前身,叫Chatbot Arena。
再往前,它属于伯克利那个赫赫有名的LMSYS研究小组。
两个伯克利的室友,只想做一件朴素的事——给大语言模型搭一个中立的擂台,让大家公平地比一比。
谁也没想到,这个学生项目会一路狂奔成独角兽。
时间线快得让人喘不过气:2025年春天,项目从大学剥离、正式成立公司,几周内就拿下1亿美元种子轮,估值6亿美元;
几个月后商业产品上线,仅四个月,年化营收就冲到3000万美元。
紧接着,今年1月,由Felicis和UC Investments领投的1.5亿美元A轮落地,投后估值定格在17亿美元。

掌舵的三个人,也都不是无名之辈。
CEO Anastasios Angelopoulos,骨子里是个搞数学的。
他在斯坦福读电子工程本科时,师从凸优化领域的传奇人物Stephen Boyd。
到了伯克利读博,导师直接是两位教父级大牛——机器学习宗师Michael I. Jordan、计算机视觉宗师Jitendra Malik。
他这些年钻研的方向,主要是怎么对一个黑箱模型,做出数学上严格站得住脚的判断。

CTO Wei-Lin Chiang,是开源圈的熟脸——那个红遍全网的开源聊天机器人Vicuna,就出自他手。
他在伯克利读博,师从Ion Stoica,专攻分布式系统,此前在谷歌、亚马逊、微软都干过。
2022年底ChatGPT公测那一刻,他把手头之前的研究全停了,一头扎进Arena。

他对这个项目的痴迷,被搭档Angelopoulos形容成「a labor of love」(一份用爱发的电)。
为了这个项目,两人工作时间长到干脆搬到一起住。两个室友,搭出了一个17亿美元的公司。
而第三位联合创始人,是大名鼎鼎的伯克利教授、Databricks联合创始人Ion Stoica。他在项目2025年4月公司化之前一直担任顾问。

当裁判,比当选手更重要
Arena最新的动作,是推出了Agent Mode(智能体模式)。
它评测的早已不只是「谁聊天聊得更好」,而是数百万用户正在用智能体干的真活:写代码、调bug、做研究、分析文档——那些动辄上百次工具调用、多轮往返的长任务。
它开始用任务完成率、幻觉率这些客观指标来打分,远远超出了最初「人类偏好投票」的范畴。

AI正从「聊天机器人」进化成能独立扛活的「智能体」,任务越来越长、赌注越来越高。
评测,是人类伸进AI内部的最后一根探针。
Arena这门生意能值1亿美元、能值17亿美元,本质上赌的就是这件事会越来越重要、越来越贵。
但所有人最终都得回答同一个问题——当机器开始自己出题,谁还有资格阅卷?
