

自从美国开始对 AI芯片禁用,国内高度关注自主AI芯片发展,尤其是大芯片上。事实证明,我们的脖子是卡不住的。目前,国内AI芯片赛道分为两派:GPU派和非GPU派。
最近几个月,两个派别的AI芯片发展速度非常惊人,爆发已经势不可挡。
GPU派:上市潮起
最近的国产GPU好生热闹。继续12月11日的北京摩尔线程登录科创板,上海沐曦在12月17日正式登录科创板,成为国产GPU第二股。摩尔线程上市首日录得425.46%的涨幅,而沐曦实现692.95%单日涨幅,市场热情达到了沸点。上海GPU公司壁仞也在近期传出聆讯,港股IPO通过备案,即将成为“港股国产GPU第一股”。
目前,国内GPU分为四个派别,根据创始团队的背景,人们也亲切地把他们称呼为“中国英伟达”“中国AMD”:
NVIDIA系:代表企业有摩尔线程、天数智芯,这些企业创始人和核心人员都有NVIDIA基因,打法是优先兼容CUDA生态切入市场,再通过自研架构不断发展;
AMD系:代表企业有壁仞、沐曦,创始人和核心人员都有AMD基因,AMD作为英伟达挑战者,一直以差异化为竞争核心,这些流派玩家打法和AMD类似;
国家队:比如景嘉微创始人及核心团队均来自国防科技大学,通过军用图形显控起步稳扎稳打进入信创市场,并不断拓展至AI计算领域,再比如海光、龙芯、兆芯研究集成GPU与CPU配合;
拆分系:商汤作为AI公司,2024年底也拆分独立了曦望Sunrise公司,此前公司刚完成近10亿元融资,主要围绕自己AI产品进行开发产品。
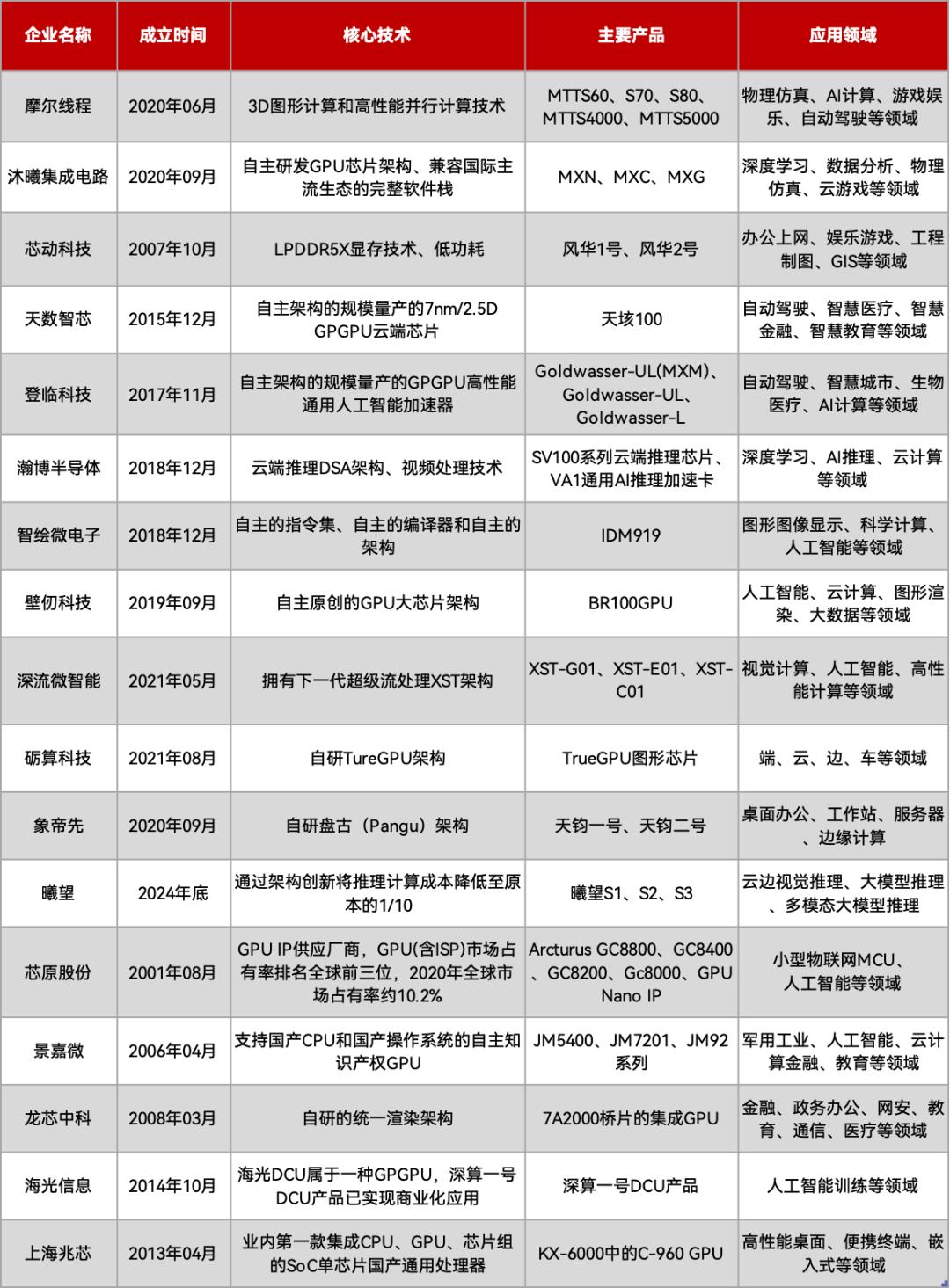
国产GPU不完全盘点,制表丨EEWorld
资本市场关注的是这些企业的估值有没有“泡沫”,而芯片人则更加关注这些企业投入究竟够不够。GPU很难,没有投入真的很难突破。
摩尔线程堪称“英伟达系”代表。其创始人张建中曾担任英伟达全球副总裁兼中国区总经理,联合创始人团队中也包含多位英伟达前高管。技术路线上,摩尔线程选择了较为激进的“全功能GPU”方向,基于其自主的MUSA统一架构,致力于在一张显卡上同时实现AI训练与推理、图形渲染、视频处理等多场景能力。然而,快速发展也伴随着持续的投入与亏损。2022年至2024年间,公司净亏损分别为18.4亿元、16.73亿元和14.92亿元;扣除非经常性损益后的净亏损分别为14.12亿元、16.9亿元和15亿元。同期,研发投入保持高位,分别为11.16亿元、13.34亿元和13.59亿元,三年累计研发费用约38亿元。
沐曦科技,则带有鲜明的“AMD基因”。其创始人陈维良曾任AMD全球GPGPU设计总负责人,两位联合创始人兼首席技术官也曾是AMD的首席科学家。沐曦以自主研发的GPU IP为核心,构建了MXMACA软件栈,其架构高度兼容英伟达的CUDA生态,旨在降低用户的迁移成本。财务方面,沐曦在2022年至2024年间的净亏损分别为7.77亿元、8.71亿元和14亿元;扣非后净亏损分别为7.84亿元、8.9亿元和10.44亿元。研发投入同样持续增长,分别为6.478亿元、6.99亿元和9亿元,累计达到约22亿元。
壁仞科技由前商汤科技总裁张文于2019年创立,在国产GPU企业中,是最早Chiplet技术实现商用落地的公司之一。公司采取渐进式发展路径,首先聚焦于云端通用智能计算领域,逐步在人工智能训练与推理等关键场景中赶超既有解决方案,最终实现了国产高端通用智能计算芯片的突破。在研发成果方面,截至2025年9月30日,壁仞科技已在全球累计公开专利1200余项,位居中国通用GPU公司首位;同时,获得授权的专利也达到550余项,稳居国内行业前列。
GPU的路途道阻且长。除了芯片、架构本身问题,GPU公司不光要面对CUDA垄断难题,还要围绕Chiplet、HBM、IP、兼容、Scale-Up/Scale-Out/Scale-Inside等问题,构建自己生态帝国。而从国产GPU公司中,我们看到他们的解法,先兼容再赶超。
非GPU派:势头迅猛
非GPU AI芯片领域也热闹非凡,每个企业都有着自己的理解和不同的路线。
华为在AI芯片领域的深耕想必不必多说。今年9月18日,华为罕见公布昇腾三年发展路线图。根据规划,2026年至2028年期间,华为将分阶段推出四款昇腾系列芯片,具体包括:2026Q1推出昇腾950PR,采用华为自研HBM;2026Q4推出昇腾950DT;2027Q4推出昇腾960芯片;2028Q4推出昇腾970。
2019年开始,华为已发布910B、910C多款产品,其中,昇腾910C算力高达800TFLOPS。以昇腾910为基础,华为在今年5月推出了昇腾384超节点,即将384张昇腾NPU与192张鲲鹏CPU连接在一起。2026年即将发布的昇腾950PR/DT微架构将升级为SIMD/SIMT,算力达到1PFLOPS(FP8)/ 2PFLOPS(FP4),英伟达最新Blackwell B300在同等标准下的算力约为3840TFLOPS。
一家北京的AI芯片公司正在成为市场的新秀,并且也在筹备IPO。12月2日,清微智能宣布近日完成超20亿元C轮融资。该公司的目标是打造国内“非GPU”新型架构芯片领域首个上市标杆企业。据了解,该公司核心团队来自于清华大学以及海思、英伟达、苹果、AMD等知名企业,2025年算力卡订单累计超2万张,可重构芯片总出货量超3000万颗,已然形成从技术到市场的强力闭环。
清微智能采用的是可重构计算(CGRA)路线,目前这一路线上,还包括国外的SambaNova、Groq。可重构芯片被誉为芯片界“变形金刚”的可重构计算架构,能够根据瞬息万变的AI计算任务,动态、实时地重组硬件资源,在芯片内部构建出直达目标的“最优计算通路”。该架构的独特优势,使其在GPU的通用性与ASIC的极致高效之间找到了完美平衡,以“通用型TPU”的姿态,为中国应对复杂多元的智能计算需求提供了独创解决方案,整体成本降低50%,能效比提升3倍。
12月15日,据腾讯科技独家消息,昆仑芯即将完成股份制改造,并加快推动上市进程。在此次股改前,昆仑芯在与多家券商沟通后已决定转战港股市场。而作为其大股东,百度随后发布公告称,目前正在就建议中的分拆及上市事宜进行评估。百度同时指出,若推进分拆与上市,须履行相关监管审批程序,且公司不保证相关计划最终必定落实。
今年11月的百度世界大会上,昆仑芯多款新品亮相,其中包括计划于2026年上市的M100 芯片、计划于2027年上市的M300芯片。腾讯科技报道还提到,昆仑芯2025年营收远超 2024年的20亿元,一位接近昆仑芯的知情人士透露“体量排在国产前三应该不是问题”。
燧原科技被人称之为“国产GPU四小龙”(其他三只龙为摩尔线程、沐曦、壁仞),不过燧原的AI加速卡本身比较复杂,单纯称为GPU其实不够确切。今年11月,燧原科技已再次向上海证监局办理辅导备案登记,辅导机构变更为中信证券。这一举动标志着燧原科技继续坚定推进其在科创板的上市进程。
今年的世界人工智能大会上,燧原发布最新一代训推一体产品“燧原L600”及云燧OGX系列产品。这款历时两年半研发的燧原L600,面向训练及推理场景,国内首创原生FP8低精度算力,拥有144GB存储容量、3.6TB/s存储带宽、800GB/s互联带宽,性能卓越。
TPU也是国产AI芯片的一条路。TPU全称Tensor Processing Unit,是一种专为处理张量运算而设计的ASIC芯片,由谷歌自研在2016年推出首款产品。在深度学习的世界里,张量(多维数组)是无处不在的。TPU就是为了高效处理这些张量运算而诞生的。TPU内置大量矩阵运算单元,使得其能够并行处理大量的矩阵运算,大大提高计算效率。不过相比GPU或者说GPGPU,TPU太专用了,但是应付AI训练还是绰绰有余。简单粗暴对比起来就是:TPU与同期的CPU和GPU相比,可以提供15~30倍的性能提升,以及30~80倍的效率(性能/瓦特)提升。
中昊芯英是国内唯一全自研、已量产TPU芯片的公司。其产品性能极高,以中昊芯英历时近五年全自研的国内首枚已量产 TPU AI 芯片“刹那”为例,在处理大规模 AI 模型运算时与海外知名 GPU 芯片相比,计算性能可以超越其近 1.5 倍,在完成相同计算任务量时的能耗降低 30%,将价格、算力和能耗综合测算,“刹那”的单位算力成本仅为其 42%。
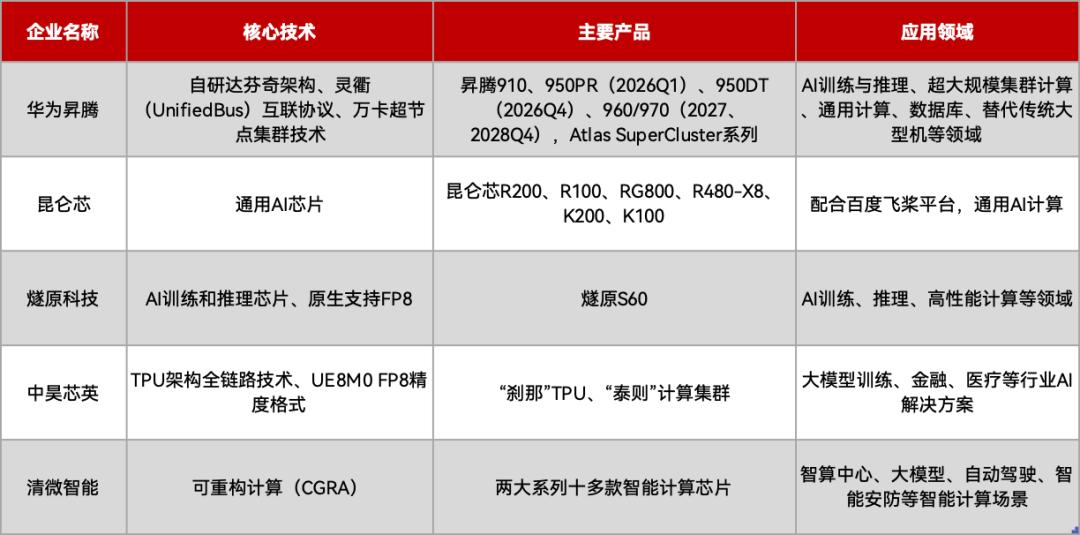
国产非GPU AI芯片不完全盘点,制表丨EEWorld
国产AI芯片:大爆发的时间来了
目前,国产AI芯片正在走着两条不同的路线:一条是直面挑战,在GPU的战场上与巨头竞逐,从兼容到创新,逐步构建自主的硬件体系与软件生态;另一条则是开拓“创新之路”,另辟蹊径,在可重构计算、TPU、ASIC、专用加速器等新兴架构上大胆探索,以差异化优势开辟全新赛道。
可以说,国内已经在各种形态的AI芯片上都有所布局,而国产的芯片算力也越来越强大。另一方面,国内也在加强制造能力建设。
现在的英伟达四面楚歌,谁都想取代。虽然特供版的GPU可以重新供应了,但国内市场似乎再也不买账了,也许这正是国产AI芯片快速崛起的契机。
