

手机的网络,专挑细处断!
眼看着要迟到了,你从地铁里挤出来冲锋,过闸机的时候却死活刷不出来二维码;
盯着倒计时抢专家号,点进去就转圈,等页面终于加载好,号早就没了;
看演唱会想抓紧时间发个热乎朋友圈,最终等到散场才发送出去。

图丨giphy
好消息是,不是你的手机老了坏了。
坏消息是,你正站在一个被几百人同时挤爆的无线小区里。
“无线小区”,你可以把它想象成酒店里划分的不同房间,每个房间由基站负责接待。平时没啥问题,几百号人涌进同一个房间,那谁都别想顺畅上网。
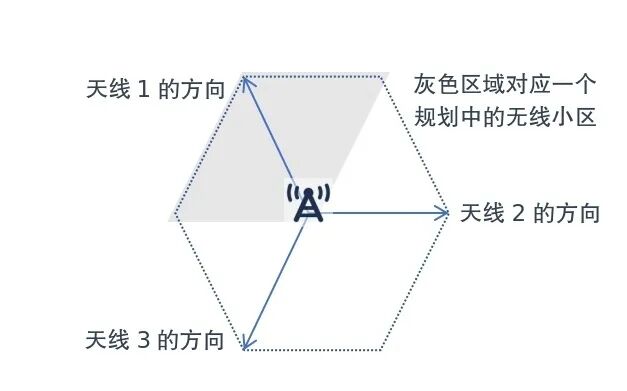
无线小区的简单示意图,中心为基站。明白“蜂窝网络”这个说法怎么来的了吧?丨作者供图
说回开头那些抓狂瞬间——闸机刷不开,专家号抢不到,朋友圈发不出去,这些能忍。但如果遇到突发大事件呢?网络还能自己抢救一下吗?
要想网不卡,先多修基站
最直接的思路:多建基站,把人群分散到更多无线小区里。
基站越多,容量越大、覆盖越广——酒店房间多了,每个房间分到的客人就少了。
而且电磁波天生会衰减,离天线越远信号越弱,再碰上墙壁树木,衰减更快。想让更多角落有信号,只能靠铺更多基站来补。
我国已建成数百万个4G 和5G 基站。可基站铺满了,新麻烦也来了。
基站越多,麻烦也越多
电磁波空间是共享的。你的手机、邻居的手机、路边汽车里的设备,可能挤在同一片频率上。基站之间也一样——数量一多,互相干扰就成了绕不开的问题。
为了让成千上万台设备不撞车,网络得在频率和时间上精打细算,就像十字路口的车流——分道行驶、分时放行。从业者给每个小区分配编号,帮助手机分清信号来路,挑信号最好的接入。
不过,手机不知道哪个无线小区最好——信号最强的无线小区,可能已经被各种终端挤爆了,接进去就卡。

使人梦回拨号上网丨giphy
那基站能不能主动引导?能!
咱们可以通过人工操作、或依照历史记录、或依照预先设定,让基站给空闲小区“加分”。加分不是真把信号调强了——即使发射功率不变,被加分的小区在手机眼里“看起来”信号更好,手机等终端就会被温柔地引导到空闲小区。
问题解决了吗?没有啊!
让网络自己学会变聪明
更根本的问题是,网络建好后,用户的实际分布往往跟规划预期差很远。
比如美食广场的基站平时很闲,每到饭点就被挤爆。靠人工操作、预先设定、历史记录,都很难及时把用户从拥挤的美食广场基站挪到旁边空闲的停车场基站。
怎么解决这个问题呢?从业者盯上了“强化学习”。
强化学习靠“试错”和“奖励”学会做事,不用人写规则。我们成长里也有它的影子:上课睡觉→考试不及格→决定认真听讲→拿到好成绩。
人无再少年,AI 有一万次试错的机会,来看看AI在无线网络里如何强化学习。
AI先是观察每个小区的负载率、用户数量、信号质量(状态);
然后调整天线功率、朝向和协议参数引导终端(动作);
目标是让最挤的小区尽量闲下来,负载率越低、它得到的奖励越高(奖励)。
AI在仿真环境里不断试错,观察奖励涨跌以更新策略。成千上万轮后,它摸索出了经验:本小区负载超80%且隔壁低于60%?把人迁移过去!两个小区都忙?按兵不动!

心理学家斯金纳表示用类似的方法训练过老鼠取食丨miepvonsydow.wordpress.com
这个方法在实验中取得了不错的用户体验。
慕尼黑工业大学的研究团队用强化学习给用户分配小区:4个小区、15名用户不停移动的仿真中,传统策略让一个小区平均接入超11人,强化学习压在6人以内[1]——你从和10个人抢网速变成最多5个,体验翻倍。
甚至在节能省电上也表现优秀。
无线小区太闲的时候可以暂时关停。定时关停(比如到了夜里12点关停部分无线小区)可以节省7.91%的能耗,基于固定值关停(比如负载低于某个值关停部分无线小区)可以节省13.48%的能耗。使用强化学习的方法决定是否关停,节省能耗则达到了15.26%[2]!
值得一提的是,采用这种方法,还能保证在97.40%的时段内,有95%以上的用户能用到不低于5Mbps的下载速率,比定时关停和基于固定值关停都要高——省得更多,弊端更小。
目前强化学习管理基站还都在仿真环境中进行,到了复杂的真实世界会不会掉链子,还说不好。
比如这套系统学会了跟着仿真数据走,去符合早晚高峰地铁上的使用需求,结果到了周末或者节假日大家都窝在家里,还跟着老规矩办事的系统就可能让用户上网卡顿。
更多样的仿真数据能堵漏洞,也期待它在现实中不断学习完善,给我们更丝滑的体验。
不只是无线网络的故事
除了管理基站,强化学习这东西还能干嘛?
其实你可能已经用过了。ChatGPT 和 DeepSeek 的训练用到 的RLHF(“从人类反馈中强化学习”),原理也是一样的:AI 给出回答(动作),人或 AI 打分(奖励),AI 根据分数调整。训练聊天 AI 和训练管基站的 AI,底层都是“试错→打分→进步”。
让系统变聪明,也不止强化学习这一种方法。
第一类,强化学习。本事是面对不断变化的环境,自己摸出最优策略。网络负载均衡天生就是这种问题——用户一会儿涌这儿、一会儿涌那儿,没有固定规律。
第二类,传统机器学习。你给我历史数据,我从中找规律。比如拿几万人身高体重和体检结果,学会“什么范围的人大概率偏胖”。但网络数据瞬息万变,光靠历史不够。
第三类,规则系统。把专家经验写成“如果……就……”塞进程序,比如“小区 A 负载超80%,把10%用户挪到小区 B”。优点是可靠、不用训练,缺点是规则没写到的场景就抓瞎。

图丨giphy
三种方法各有舒适区。网络负载恰好落在强化学习最擅长的那块地盘——动态、没有固定答案。以前运维靠工程师写死规则,现在网络自己试、自己学、自己调。
未来,规则系统管常规场景,传统机器学习从历史数据找规律,强化学习应对“规则写不到、规律找不到”的动态变化,三者配合。我们也期待更厉害的 AI 加入进来。
参考文献
[1] A. Prado, F. Stöckeler, F. Mehmeti, P. Krämer and W. Kellerer, "Enabling Proportionally-Fair Mobility Management With Reinforcement Learning in 5G Networks," in IEEE Journal on Selected Areas in Communications, vol. 41, no. 6, pp. 1845-1858, June 2023, doi : 10.1109/JSAC.2023.3273705
[2] A.-K. Dang, H. Khalifé, M. Sintorn, S. Rovedakis and S. Secci, "Data-driven Energy Optimization in Mobile Networks with User Experience Guarantees," IEEE INFOCOM 2025 - IEEE Conference on Computer Communications, 2025, doi : 10.1109/INFOCOM55648.2025.11044545
