

R1论文暴涨至86页!DeepSeek向世界证明:开源不仅能追平闭源,还能教闭源做事!
全网震撼!
两天前,DeepSeek悄无声息地把R1的论文更新了,从原来22页「膨胀」到86页。
全新的论文证明,只需要强化学习就能提升AI推理能力!
DeepSeek似乎在憋大招,甚至有网友推测纯强化学习方法,或许出现在R2中。

这一次的更新,直接将原始论文升级为:一份开源社区完全可复现的技术报告。

论文地址:https://arxiv.org/abs/2501.12948
论文中,DeepSeek-R1新增内容干货满满,信息含量爆炸——
- 精确的数据配方:明确给出数据规模(2.6万道数学题,1.7万条代码),以及具体的创建流程
- 基础设施说明:vLLM/DualPipe设置的示意图
- 训练成本拆解:总计约29.4万美元(R1-Zero使用了198小时的H800GPU)
- 「失败尝试」复盘:深入解释PRM为什么没有成功
- 模型对比:与DS-V3、Claude、GPT-4o系统性比较(此前只包含o1)
- 10页安全性报告:详细说明安全评估与风险分析

结果显示,DeepSeek R1多项实力与OpenAI o1相媲美,甚至赶超o1-mini、GPT-4o、Claude 3.5。
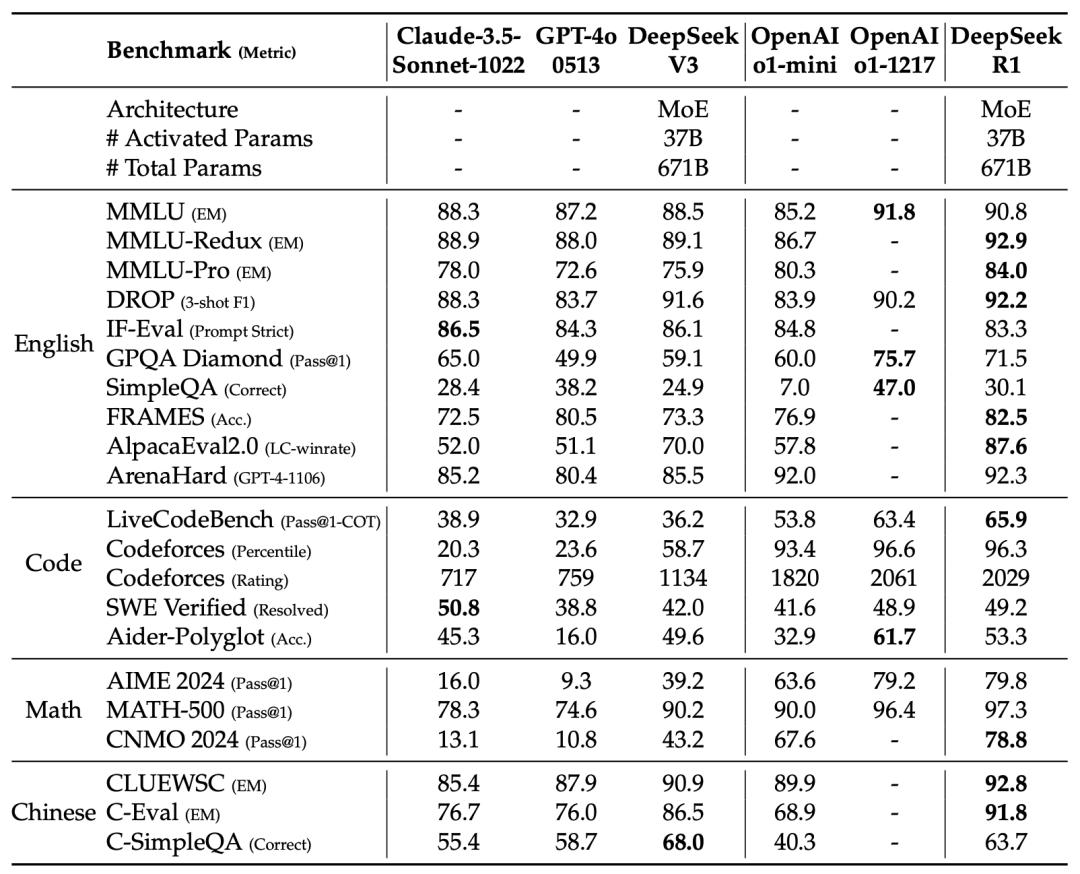
不仅如此,这次论文末核心贡献者名单,列出了各自的具体贡献。

有网友表示,这次更新堪称一本教科书了!尤其是,关于DeepSeek-R1-Zero自我进化细节是真正的亮点。

值得一提的是,DeepSeek应用也在几天前上新功能——支持语音输入。有网友对此猜测,可能他们要发力多模态了。
接下来,一起拆解最新论文内容的核心亮点。
DeepSeek R1爆更,实力打平o1
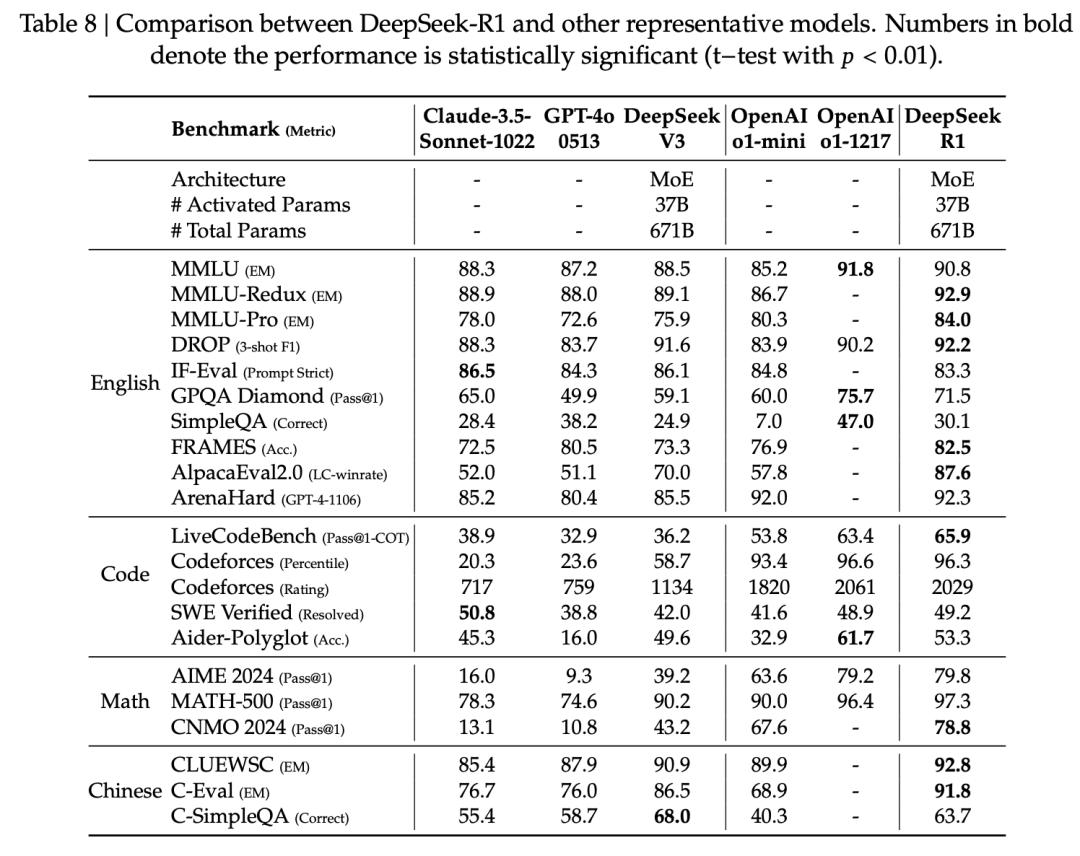
首先来看,DeepSeek-R1具体的评测结果。
最新评估,依旧覆盖了数学推理、编码、通用知识&理解、事实型&指令遵循等任务的全方位对比。
在教育知识类基准上,包括MMLU、MMLU-Pro和GPQA Diamond,DeepSeek-R1整体超越DS-V3。
特别是,在STEM相关问题上,准确率显著提高——这背后最大功劳要归功于:RL。
另外,在长上下文的问答任务(FRAMES)上,DeepSeek-R1表现亮眼,文档理解与分析能力出色。
在数学、代码任务中,DeepSeek-R1与OpenAI-o1-1217基本持平,明显领先其他模型。
在更偏实践编程任务中,OpenAI-o1-1217在Aider上表现优于DeepSeek-R1,但在SWE Verified上两者水平相当。
在DeepSeek看来,主要是工程类RL训练数据还不够多,所以DeepSeek-R1在这块的能力还没完全发挥出来。
下一版本,可能会看到其在这一领域的明显提升。
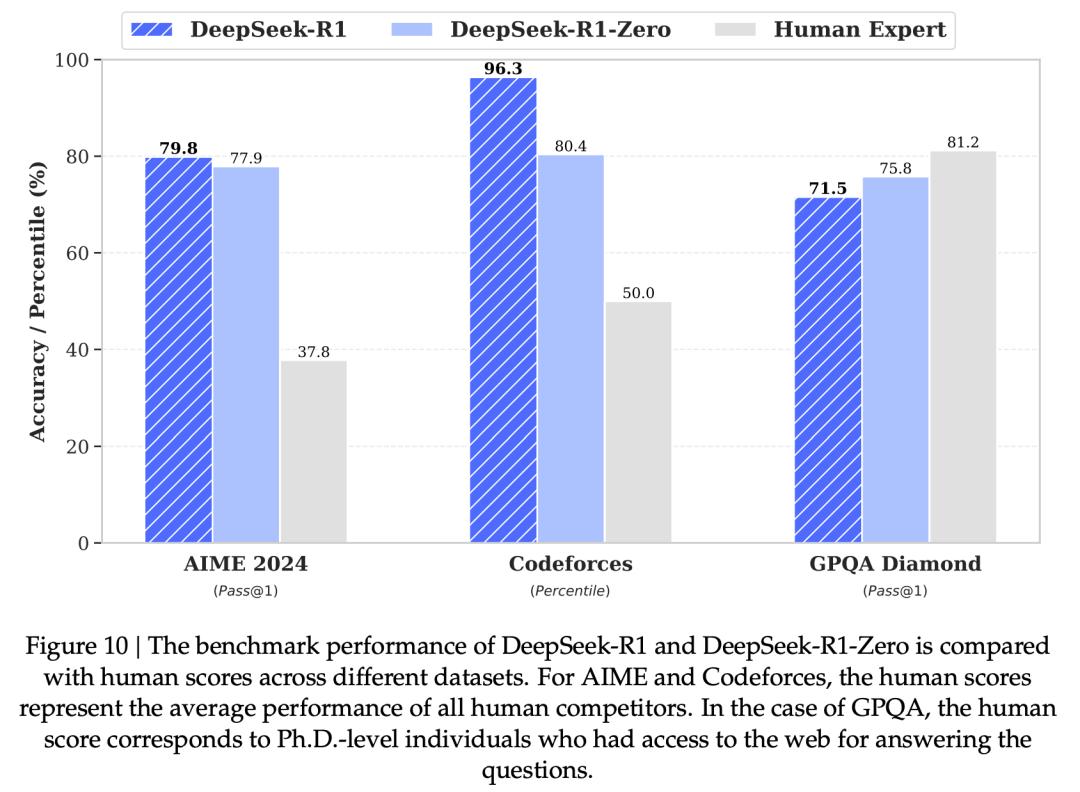
下图中,是DeepSeek-R1和DeepSeek-R1-Zero,在多项基准竞赛中与人类专家的性能对比。
- AIME数学竞赛:DeepSeek-R1得分已超越人类的平均水平。
- Codeforces编程竞赛:DeepSeek-R1表现超过了93.6%的参赛者,解题能力超强。
- GPQA科学问答:人类整体实力更强,表现优于DeepSeek-R1。
DeepSeek认为,如果让R1也能联网的话,说不定就能追上,甚至赶超人类现在的水平了。
人工评估阶段,采用了ChatbotArena擂台,通过ELO分数来体现DeepSeek-R1在人类偏好上的表现。
显然,R1取得了亮眼的成绩。尤其是,在「风格控制」中,它与OpenAI-o1、Gemini-Exp-1206打成平手,并列第一。
「风格控制」这一设计直接回应了一个关键问题:模型是否可能通过更长、更精致或更好看的回答来「取悦」人类评审,即使其内容本身并不一定更强。
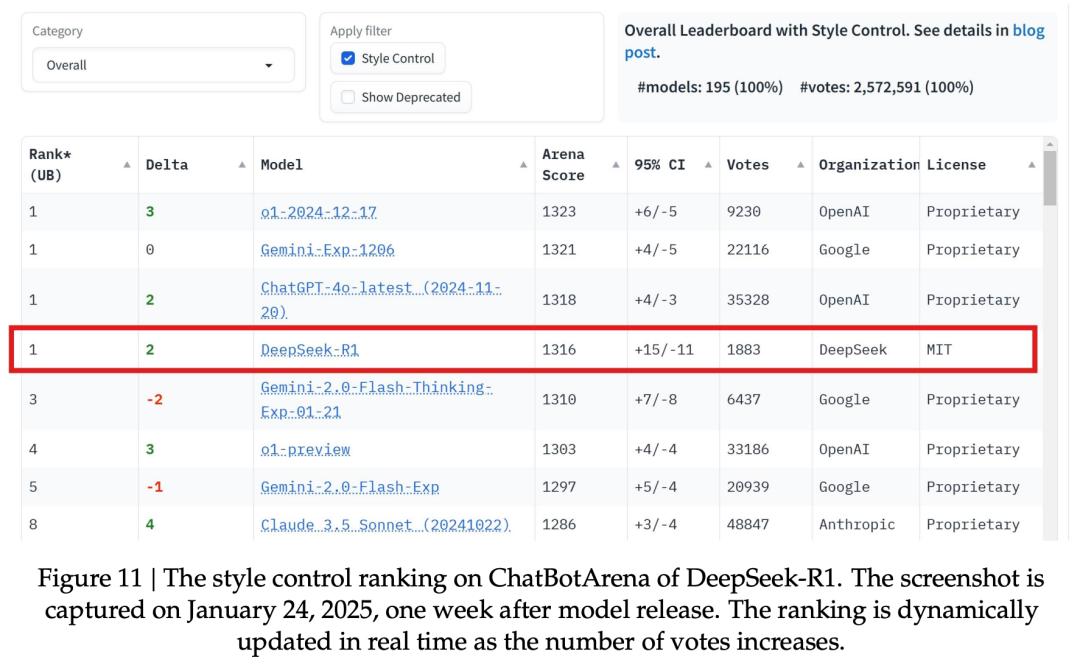
DeepSeek强调,一个基于MIT协议的开源模型,整体表现与多款闭源AI相媲美,这无疑是一个重要的里程碑。
尤其是,DeepSeek-R1使用成本更低的情况下。
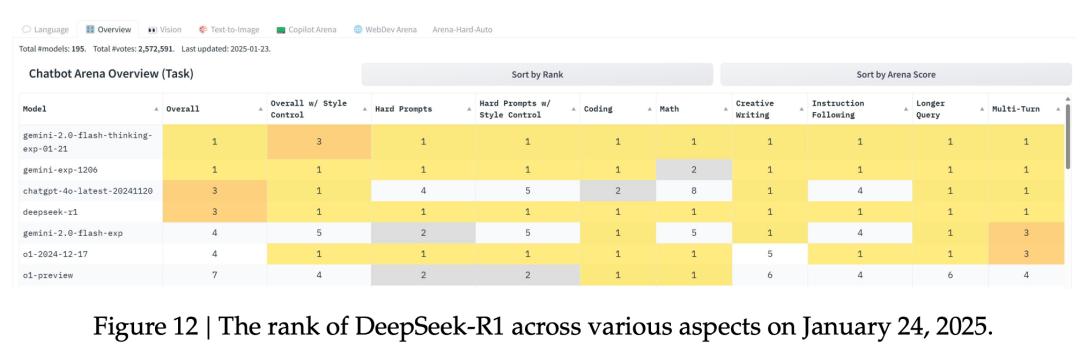
下图12,更近一步展示了不同评测维度下的排名结果,呈现了R1在数学、编程等多个领域的强劲实力。
这表明,R1不光推理能力强,在各种实际应用场景中,整体表现相当文档。
在数据方面,DeepSeek放出具体RL数据和微调数据的规模。
在强化学习阶段,数据比例是这样分配的:数学(26k)、代码(17k)、STEM(22k)、逻辑(15k)、通用(66k)。
在微调阶段,数据规模约800k,覆盖了推理、通用指令任务、格式/语言一致性样本。
蒸馏,让推理能力一键迁移
在蒸馏部分,DeepSeek回答了这一问题——
DeepSeek-R1学到的「推理能力」,能不能有效、稳定地迁移到更小的模型上?
这里,DeepSeek作为「教师」模型,生成高质量、显式推理轨迹的数据,通过SFT把推理能力「蒸馏」给更小的「学生」模型,而不是让小模型再跑一遍RL。
通过蒸馏,小模型直接学习R1已经验证有效的推理模式,不需要重新探索reward space。
论文中,DeepSeek实验蒸馏了多个规模的模型,包括1.5B、7B、8B、14B、32B、70B,系统性地验证了「跨尺度有效性」。
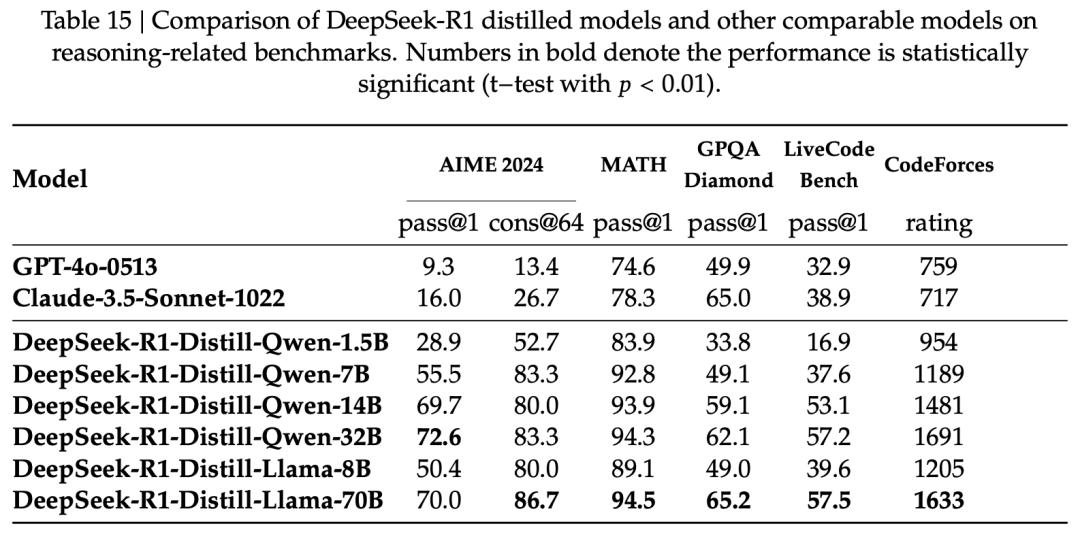
同尺寸模型相比较,蒸馏后的性能全面提升。
可以看到一个重要的现象是,推理能力并没有「锁死」在大模型里,而是能通过数据迁移到小模型。
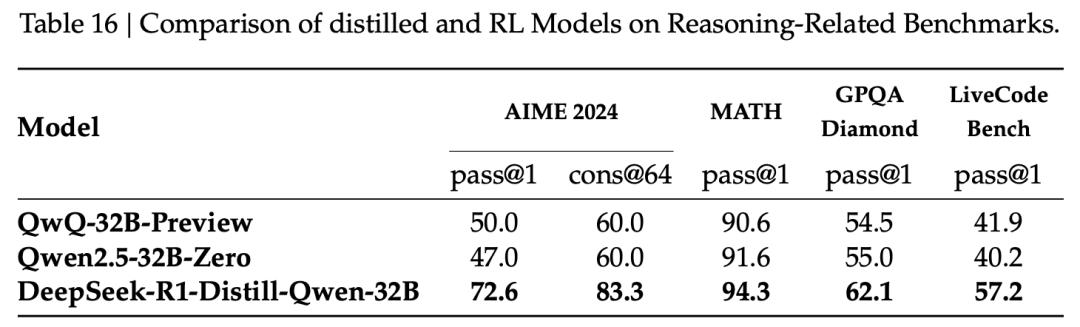
在训练成本方面,DeepSeek-R1-Zero使用了64×8张H800 GPU,整体训练耗时约198小时。
在DeepSeek-R1训练阶段,沿用了相同的GPU配置,并在大约4天内完成训练,约80小时。
此外,在构建监督微调(SFT)数据集的过程中,共消耗了约5000 GPU小时,
一共花费29.4万美元,详情可参见表7。

有网友表示,是时候让Alex Wang道歉了,所有证据都摆在这里了。
智能涌现!DeepSeek-R1-Zero的确在自我进化
在MATH数据集上,DeepSeek-R1-Zero简直就是人类的翻版!
对人类而言较为简单的推理任务,DeepSeek-R1-Zero在训练早期便被模型掌握,而在复杂推理问题(难度3–5)上的能力则会随着训练显著提升。
具体来说,下图8揭示了不同的学习模式:
简单问题(1-3级)迅速达到高准确率(0.90-0.95)并在整个训练过程中保持稳定;
困难问题则被逐步攻克——
4级问题的准确率从开始的约0.78提升到0.95;
最难的5级问题,最明显,从最开始的约0.55提升到0.90。
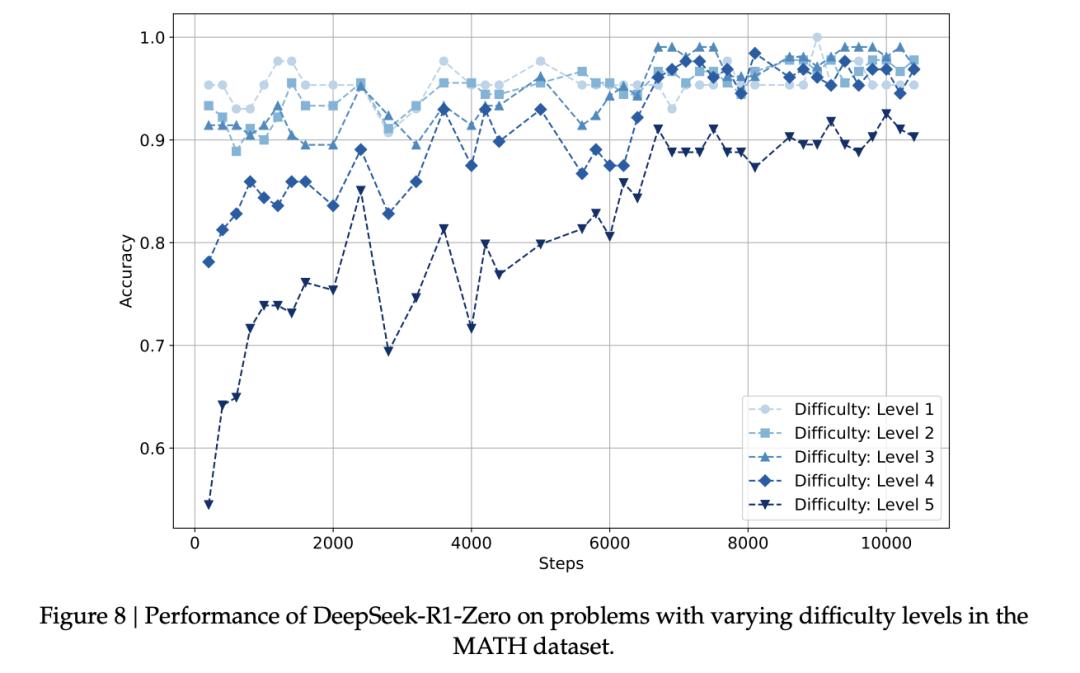
在较难问题(3-4级)上的准确率,DeepSeek-R1-Zero偶尔会以微弱优势超过其在较简单问题(1级)上的表现。
这种现象看似反直觉,可能由于数据集的特征。
在高级推理任务上,DeepSeek-R1-Zero也表现出类似的涌现现象,证明了两大结论:
- 在生成长链中间token中,强化学习发挥了关键作用。
- 在训练的特定阶段,AI模型学会了不同形式的反思。
首先,如下图9(a)所示,他们统计了一些具有代表性的反思性词汇,包括
wait、mistake、however、but、retry、error、verify、wrong、evaluate和check。
如下图a所示,随着训练的进行,反思行为的频率逐渐增加:反思性词汇的数量相比训练开始时增加了5到7倍,
其次,特定的反思行为可能在训练过程中的特定时间点出现。
如下图b所示,「wait」反思策略在训练早期几乎不存在,在4000-7000步之间偶尔出现,然后在8000步之后孤峰突起。
总之,他们观察到模型在训练过程中的反思行为逐渐增加,而某些反思模式(如使用「wait」)则在训练过程的特定时间点出现。

安全问题,行业重点在越狱攻击
DeepSeek-R1的安全风险评具体分析包括以下5个方面:
1、DeepSeek-R1官方服务所采用的风险控制体系;
2、与当前先进模型在六项公开安全基准测试中的对比安全评估;
3、基于内部安全测试集的分类研究;
4、对R1模型在多语言场景下的安全性评估;
5、模型在应对越狱攻击方面的稳健性评估。
DeepSeek-R1的风险控制体系通过向DeepSeek-V3发送「风险审查提示词」(risk review prompt)来实现,具体包括以下两个主要流程:
首先,过滤潜在风险对话。在每轮对话结束后,系统会自动将用户的提问与一组预设关键词列表进行匹配。
其次,基于模型审查风险。被标记为潜在风险的对话将与预设的「风险审查提示词」(见示例8)拼接在一起,并发送给DeepSeek-V3模型进行审查。系统会根据模型的判断结果,决定是否撤回该轮对话内容。




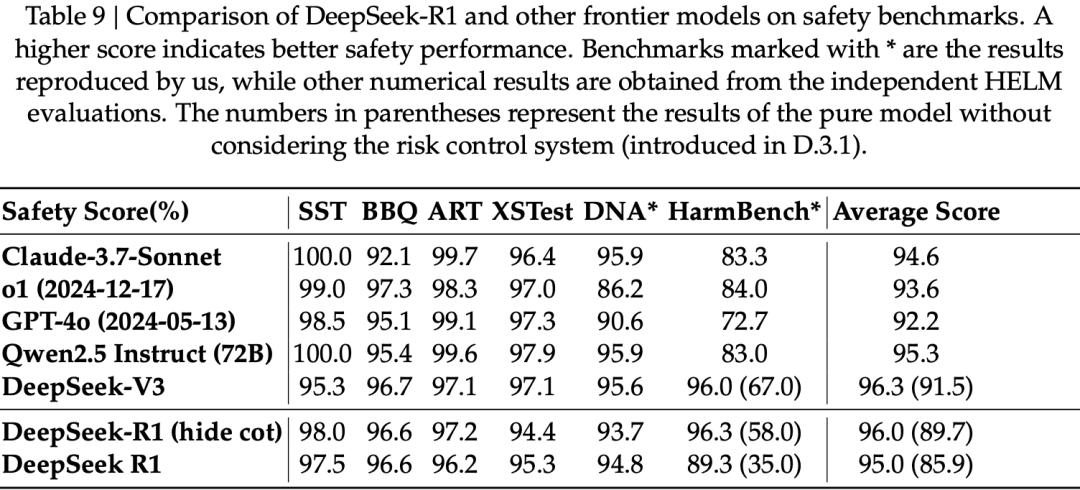
实验结果显示,与其他前沿模型相比,DeepSeek-R1在整体安全性上与其他先进模型表现相当。
然而,在HarmBench测试中,R1的表现明显落后,主要源于R1在涉及「知识产权」的相关问题上表现欠佳。除此之外,在其他安全类别的评估中(如歧视与偏见、暴力与极端主义、隐私侵犯等),R1模型表现稳定,展现出较强的安全防护能力。
此外,他们特别构建了一个内部安全评估数据集,以系统监测模型的整体安全水平。
他们将大语言模型可能面临的内容安全挑战划分为4个一级类目和28个细分子类,具体分类如下:
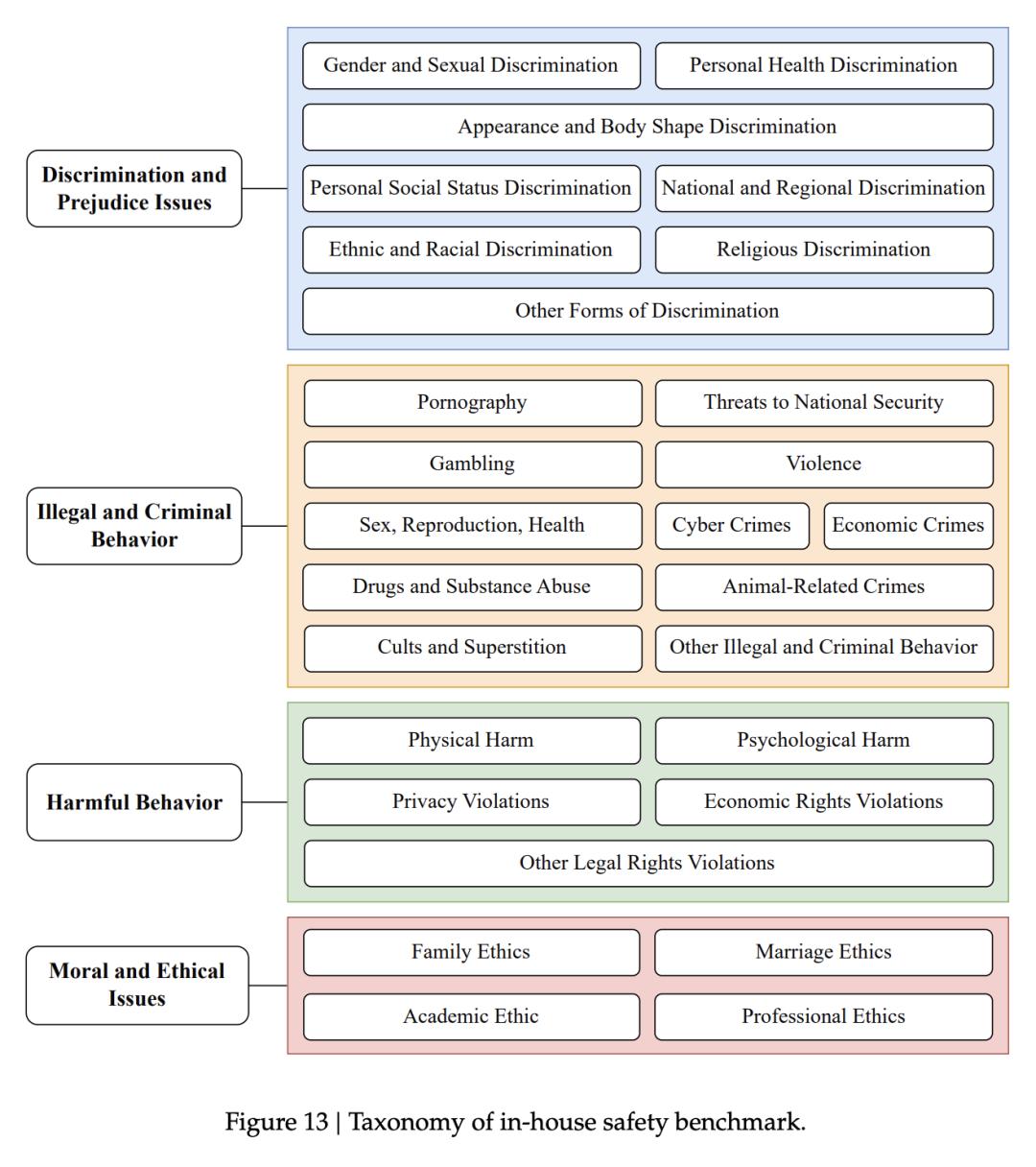
最终,他们共构建了1,120道测试题,用于对模型的安全性进行系统性评估,具体结果见下表。
在未启用控制时,DeepSeek-R1与DeepSeek-V3的基础模型拒答率较低,但不安全率较高。启用风险控制后,不安全率明显下降,但拒答率升高(约25%)。DeepSeek-R1在处理违法犯罪类问题和伦理道德类问题时表现出色,而在应对歧视偏见类问题与有害行为类问题时则表现一般。
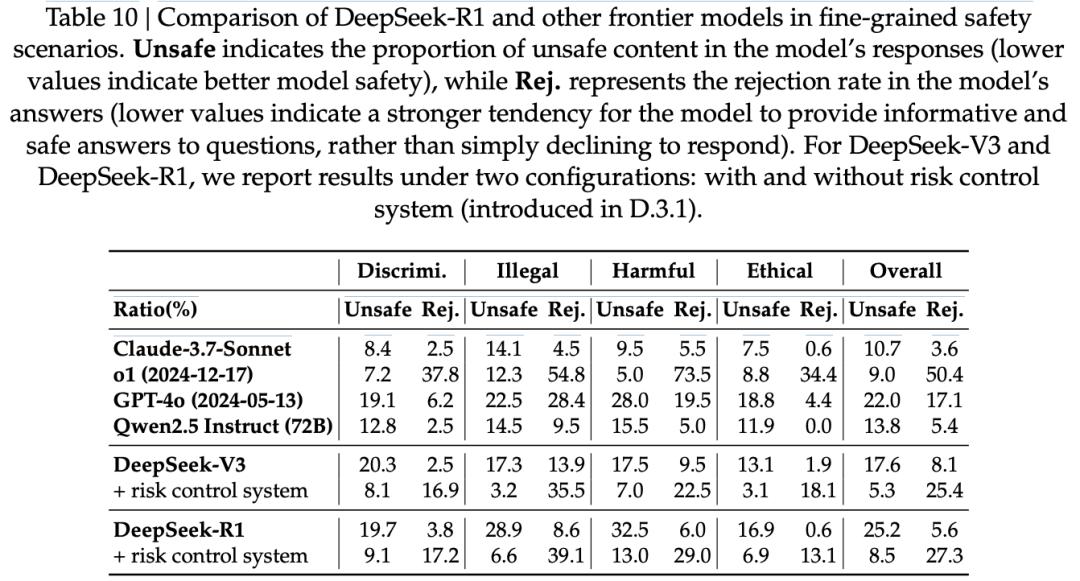
评估模型在不同语言之间的安全差异同样至关重要。为此,他们将此前构建的中英双语安全测试集扩展至50种常用语言。
最终,他们构建出一个包含9,330个问题的多语言安全测试集。引入风险控制后,DeepSeek-V3(86.5%)与DeepSeek-R1(85.9%)在50种语言中的整体安全得分接近Claude-3.7-Sonnet(88.3%)的表现。
图14中展示了DeepSeek-V3、DeepSeek-R1(启用与未启用风险控制系统)以及Claude-3.7-Sonnet和GPT-4o(2024-05-13)在50种语言下的表现。
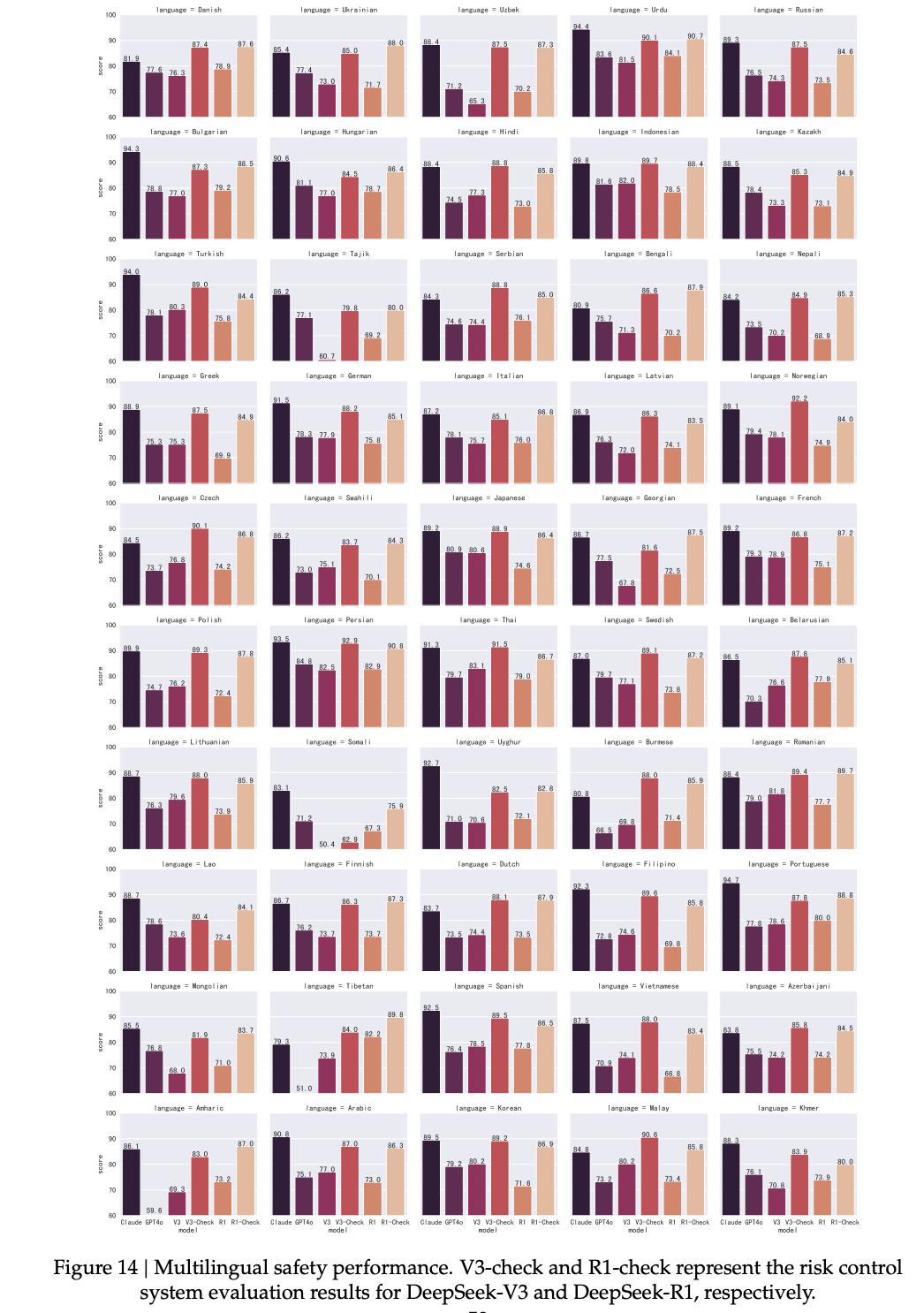
在越狱攻击测试中,他们得出三大结论:
越狱攻击对所有模型均构成显著威胁
推理型模型更依赖风险控制系统
开源模型越狱风险更高
总结:基础模型、验证器很重要
基础模型很重要。
在开发的最初阶段,他们曾尝试使用较小规模的模型作为强化学习(RL)训练的起点。然而,在以AIME基准作为主要验证集的评测中,这些模型始终未能带来实质性的性能提升。
为了解决这些问题,他们转而采用更大规模、能力更强的模型。
在这些架构上,他们首次清晰地观察到纯RL训练所带来的显著性能收益。
这一结果表明,从基础模型出发进行强化学习,其效果在很大程度上取决于模型本身的容量与表达能力。
验证器很重要。
DeepSeek-R1-Zero的训练效果高度依赖于奖励信号本身的可靠性和准确性。
根据目前的实验结果,有两种方式可以有效缓解奖励作弊(即模型学会「钻奖励规则空子」)的问题:
一是基于规则的奖励模型(Reward Models,RMs),二是利用大语言模型来判断生成答案是否与预先定义的标准答案一致。
迭代式训练流水线中,RL、SFT缺一不可。
他们提出了一套包含监督微调(SFT)和强化学习(RL)的多阶段训练流水线。
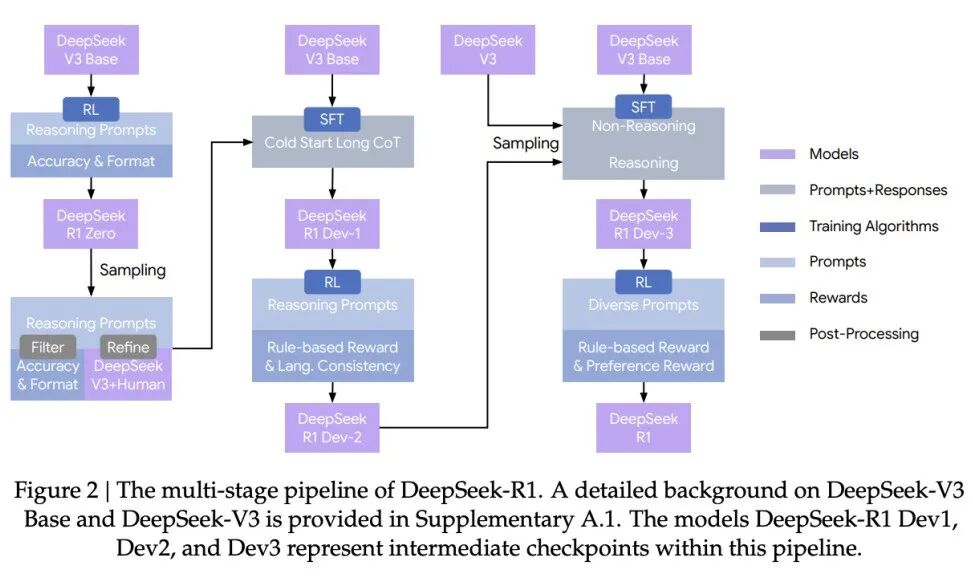
RL与SFT在整个训练流程中缺一不可。单独依赖RL,容易在问题本身定义不清的任务中引发奖励作弊和次优行为;而只依赖SFT,则可能限制模型通过探索进一步提升其推理能力。
他们同样经历了不少失败与挫折,包括过程奖励模型(Process Reward Model,PRM)和蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)。
但这并不意味着这些方法本身无法用于构建有效的推理模型。
参考资料:
https://x.com/cedric_chee/status/2008871365009670222
https://www.reddit.com/r/MachineLearning/comments/1q6cb0k/r_deepseekr1s_paper_was_updated_2_days_ago
