

想知道硅谷的程序员怎么使用AI编程,被2000家公司使用的AI代码审查智能体Greptile基于每月用AI审核的的十亿行代码,发布了AI编程年度报告,揭示了使用AI编程后带来的生产率提升,但对此程序员们却无法感同身受。
这份报告最让人震撼的一点,是指出了在AI编程的帮助下,工程师的代码生产量飞涨。
每位开发人员,每月提交的代码行数从4450增长到7839,增长幅度达到76%,对于6-15人的中型开发团队,每位开发者提交的代码量更是接近翻倍(提升89%),这意味着AI编程工具正成为一种效率倍增器。
更值得注意的是,程序员单次提交代码时,每文件中变更的代码行数的中位数上升20%(从18变为22行),意味着代码迭代不仅「更快」,且「变化更多」,这可能反映了AI编程工具能够修改的代码及应对的需求正变的复杂。
不过对于报告提到的效率提升,ycombinator论坛上对该报告的讨论,却大多是怀疑的声音。有人说需要花大量时间修复AI生成的代码中的问题。
这些细微差别从未被这类指标所捕捉。更多的人讨论提交的代码数量增加,是不是等同于程序员真实的工作效率提升。
菜鸟程序员完成一个功能需要几十行代码,而资深程序员则只需要几行就能实现。此外,由于引入了AI编程,代码被删除和重写的频率如何?这可能不容易统计,但这却很能反映AI编程带来的工作效率提升。
另一个更对于代码提交数量增加与工作效率提升的观点是,假设员工之间具备同等的专业能力,那么生产力就取决于代码行数的产出。但事实上,有的任务很难,但不需要太多行代码,只有资深程序员才能完成;而有些任务很简单,却需要很多行代码。只看代码提交量,是将所有任务都看成是中等难度的任务。
此外,不同程序员提交的代码质量不同,这一点在该报告中也没有体现。从这个角度去看,每一行代码都应该被视为一种负担,而不是资产。开发团队需要领域专家来判断到底需要多少行代码存在。
就像你可能会通过每小时搬运的物品数量来衡量仓库员工的生产力。但如果有人只是把东西随意扔到仓库里,或者搬运本不需要移动的东西,他们就会最大化这个指标。
AI辅助下每个程序员能生成更多的代码了,但这些代码真的是完成对应任务所必须的吗?这不是业务方应对考虑的问题,仅仅衡量提交的代码数,可能会鼓励不必要的重复劳动。
从这个角度来看,或许「编辑行数」是更合适的评估程序员工作效率的指标。这样一来,通过重构来减少代码库规模的方式仍然可以被视为有生产力。每删除一行代码得1分,每添加一行代码也得1分。
OpenAI依旧领先,但差距在变小
效率跃升的背后,是支撑性技术栈的激烈重构。报告以不同大模型提供商的SDK下载量为考察变量,发现在AI记忆模块中,mem0以59%市占率一骑绝尘;而对比向量数据库「六强混战」(Weaviate 25%领先,Chroma/Pinecone/Qdrant等紧咬)。
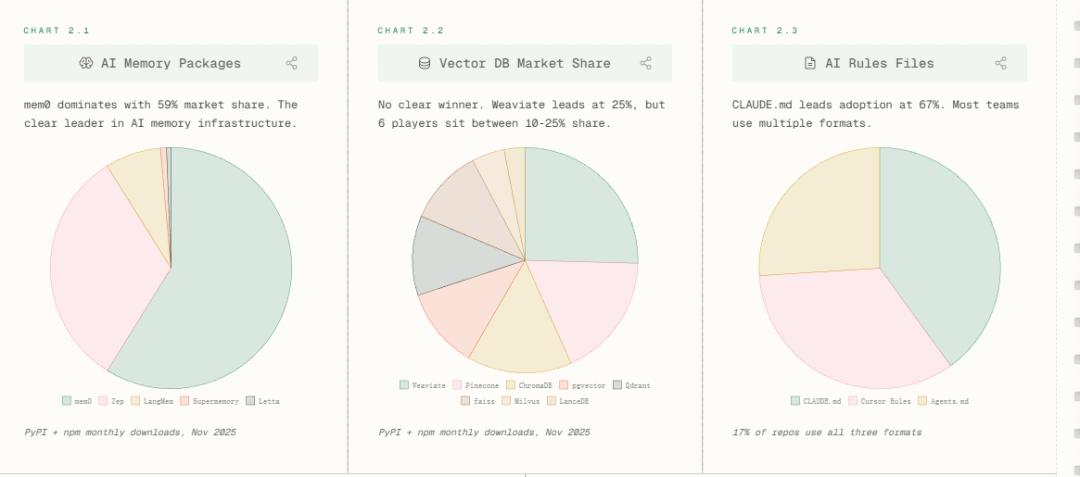
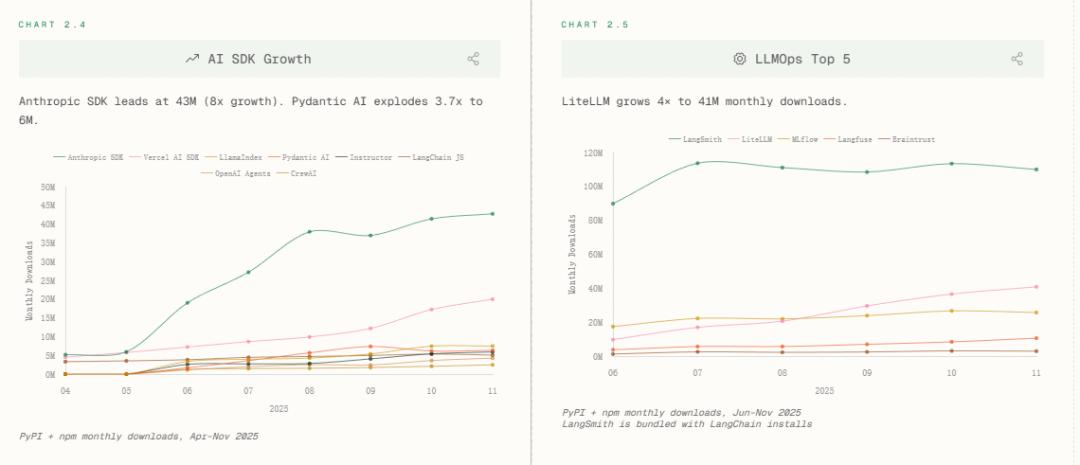
LLMOps层,LiteLLM增长4倍至4100万下载,LangSmith借LangChain生态捆绑上位。这印证一个趋势,即模型调度、监控、降级已从「可选项」变为「基建标配」。
当编程调用的智能体数量越来越多,运维复杂度指数上升,LLMOps正在承接当年K8s之于微服务的角色。
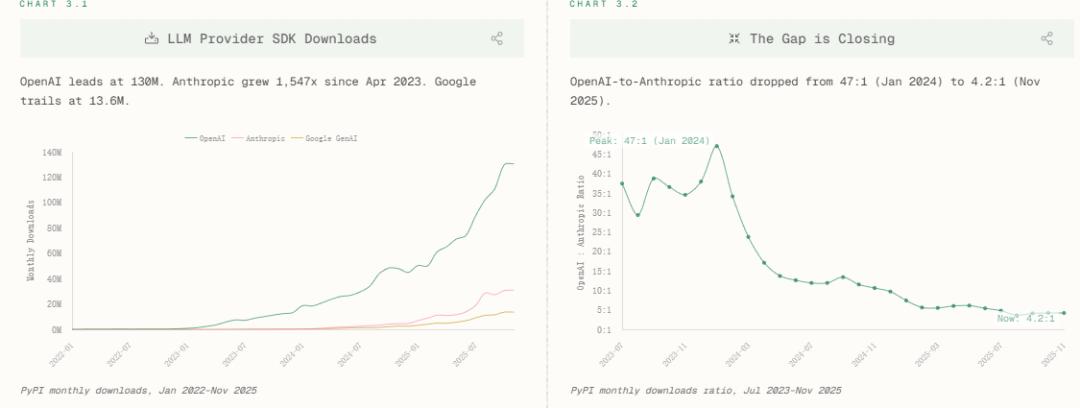
对于模型间的军备竞赛,该报告考察模型提供商从2022年1月到2025年11月的SDK下载量,主要玩家是OpenAI、Anthropic和Google GenAI。OpenAI以一条陡峭上升的绿色曲线主导市场。其下载量从2022年初的几乎为零,一路飙升至2025年11月的1.3亿次,确立了绝对的市场领导者地位。
Anthropic(红色折线)的增长轨迹堪称「火箭式」。
虽然起步较晚且基数较小,但自2023年下半年开始,其下载量呈指数级爆发,到2025年11月已达到4300万次,实现了自2023年4月以来1547倍的惊人增长,Open AI和Anthropic的比值已从47:1缩至4.2:1——开发者正在用脚投票,向更开放、更可控、更可编程的接口迁移。
而黄色曲线代表谷歌,其增长相对平缓,在2025年11月的下载量约为1360万次,与前两者相比存在显著差距。
不同模型的参数决定模型的适配场景
这份报告还揭示了五大主流模型作为编码智能体后端的实测基准(考察指标包括第一个token出现需要等待的时间、吞吐量、成本等),见下表。
通过该表,可看出Claude Sonnet 4.5与Opus 4.5只需要等待不到2.5秒,就会返回第一个token,显著优于GPT-5系(>5秒)。而在交互式编程中,2秒是「心流」与「分心」的临界阈值。
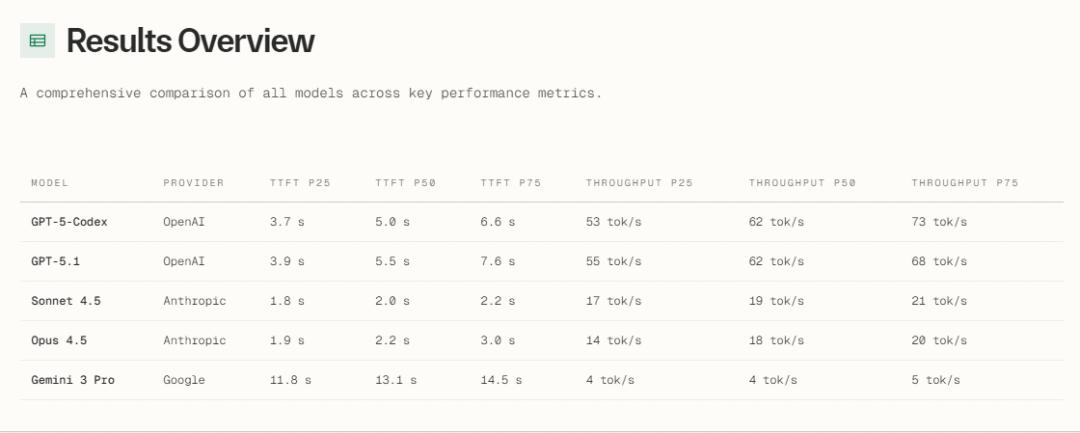
而对于批量生成场景,GPT-5-Codex与GPT-5.1的吞吐量断崖领先,适合后台CI/CD流水线中的大规模代码生成/测试用例填充。
Gemini 3 Pro则在响应速度时显著较慢,需要等10多秒才会返回第一个token,每秒输出的token数也太少,不适合交互式编程的使用场景。
该报告的最后部分,还给出了2025年基础模型及大模型编程应用领域的关键论文,这些研究预示下一波突破方向,例如Self-MoA颠覆传统多模型集成,证明单模型多次采样+聚合可超越异构模型混合,这意味着「模型多样性」或让位于「推理路径多样性」,而Search-R1用强化学习训练模型「自主决定何时搜索」,将搜索引擎变为可学习的环境动作,而非静态的工具调用。RetroLM更是在直接在KV层面检索,绕过原始文本,改变大模型组织记忆的方式。
无论用了多少AI辅助编程,提交代码前仍需人工审查。追踪AI编程工具的使用数据,无法包含人工审核的部分,这将难以真实反映产品实际的使用体验和效果。不过如果你能证明AI编程工具有助于更快地发布功能,而不是仅仅允许更多的代码行数通过审查,那么你开发的AI编程工具将具有更强的可证明价值。
参考资料:
https://www.greptile.com/state-of-ai-coding-2025
https://news.ycombinator.com/item?id=46301886
