

近来,一匹来路不明的「欢乐马」杀到了 Artificial Analysis 排行榜的榜首。
AI 圈顿时猜测声四起,直到阿里跳出来认领。
没想到短短几天,阿里「Happy」家族又来了个新成员 —— HappyOyster(快乐生蚝)。
二者「师出同门」,均来自阿里今年 3 月刚成立的 Alibaba Token Hub(ATH)创新事业群。
不过,与欢乐马「写 prompt、等渲染、收成片」的一次性流程不同,HappyOyster 是一款可实时构建和交互的开放式世界模型产品。
它基于原生多模态架构,背后是支持多模态输入与音视频联合生成的流式生成世界模型,在生成过程中能够持续接收用户指令,画面实时响应、持续演绎。
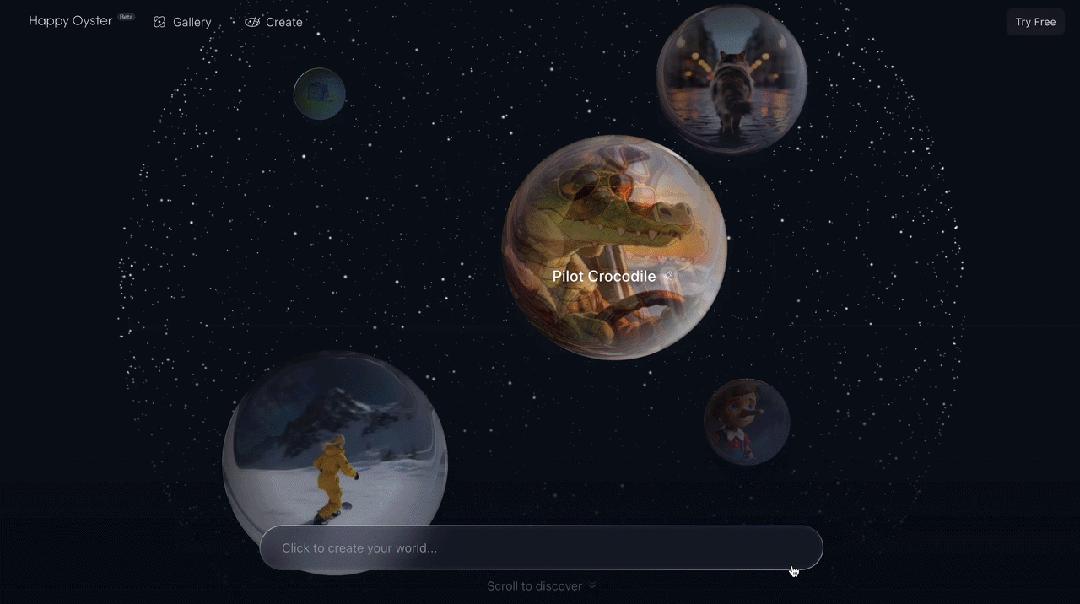
HappyOyster 主打漫游(Wander)和导演(Direct)两大核心功能。
其中漫游功能是首个支持任意风格、无限互动的通用世界模型,只需输入文本或图像,即可生成无边探索的世界场景,支持 1 分钟以上的实时位移控制和镜头控制。
导演功能则是基于世界模型的实时 AI 视频导演引擎,可连续生成长达 3 分钟的 720p 实时视频,我们可以通过文字指令实时操控镜头、调度角色、改变剧情走向。
说起这个名字,还有些讲究,它借用莎翁那句经典名言「The world is your oyster.」(世界是你的牡蛎,等你亲手打开)。
目前,HappyOyster 已上线,我们也在第一时间拿到邀请码,接下来就上手实测一番。
体验链接:https://www.happyoyster.cn/
一手实测:
阿里这个世界模型有点意思
先来试试主打的漫游(Wander)功能。
该功能支持文字或图片生成世界。
我们既可以直接输入提示词,也可以分开设定「角色(Character)」和「场景(Scene)」做精细化控制,还能在第一人称和第三人称之间切换视角。
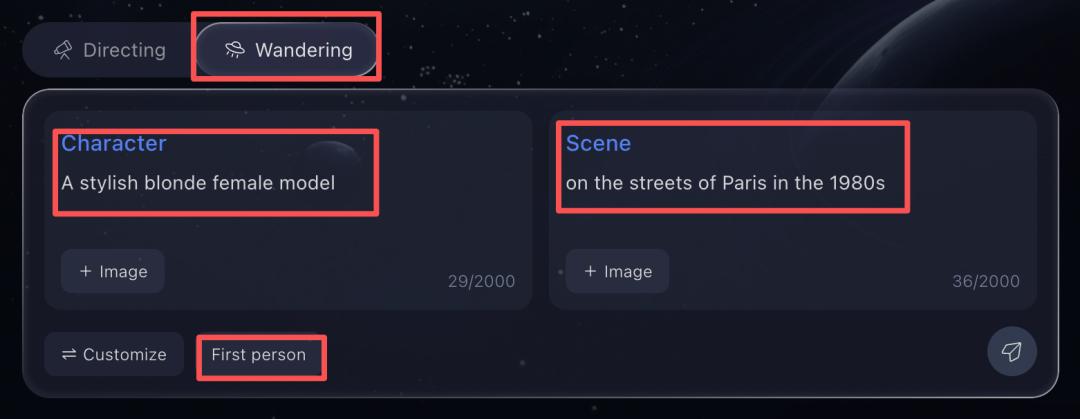
比如,我们使用「定制模式」分开输入:角色设定为「A stylish blonde female model」,场景设定为「On the streets of Paris in the 1980s」。(一个穿着时髦的金发女模特,在 80 年代的巴黎街头。)
HappyOyster 并没有直接输出一段固定视频,而是用短短十几秒,构建出一个完整的夜晚雨后巴黎街头,路面积水倒映着昏黄路灯,马路上汽车疾驰而过,两边店铺林立,细节都符合物理规律。
接下来,我们可以用 WASD 键控制角色前进方向,或者用上下左右方向键推动镜头移动,角色就在这个空间里自由游走,最终生成视频。
整个画面实时响应,全程流畅无卡顿。
系统还自动配上了契合场景氛围的 BGM,音画同步自然。
我们又上传了一张动漫风格第一视角骑行图片,HappyOyster 基于这张静态画面,生成一个具有空间结构和运动逻辑的完整场景。
视角向前推进时,道路延展、花海分布以及远处景物的层次变化是连贯的,没有明显的拼接感或跳变。
吉卜力风格的视觉语言和樱花飘落的氛围,在整个运动过程中也保持一致。
漫游功能可以对各种风格适配,我们甚至直接走进了梵高的画作。
再来试试导演功能(Direct),它最大的亮点是可以在视频的任意节点实时改变内容。
我们丢给它一张吉卜力风格的图片,HappyOyster 立马造出了一个宫崎骏式的动漫世界:一位小女孩撑着红色雨伞,走在雨后坑坑洼洼的乡间小路上。
此时输入提示词「一只可爱的吉卜力风格的小猫突然跑到女孩身边」,模型没有重新渲染,直接在当前画面里生成了一只小猫跑来,与小女孩并排同行。
我们继续追加指令:「女孩蹲下抚摸小猫。」画面再次即时响应,小女孩蹲身、伸手,动作自然流畅。
总之,模型能够根据我们输入的提示词精确地调整场景和人物动作,画面流畅且自然,每个变化都与故事情节无缝衔接。
技术解读:
世界模型和文生视频,差在哪里?
看完实测,我们可能会有一个直觉上的感受,就是这东西和 Sora、可灵这些文生视频模型好像不太一样。确实不一样,而且是从底层逻辑上就走了一条不同的路。
Sora 也好、可灵也好,文生视频模型本质上是个一次性系统。给定文本或图像条件后,模型在一个预先限定好的时间窗口内组织内容、运动和节奏,然后交付结果。用户给一次输入,得到一段输出,流程就此结束。这个过程是封闭的、一次性的,中间没有任何插手的空间。
这种模式对于生成一段精美的短片很够用,但如果想在画面中途介入,改变任何已经发生的事情,它就无能为力了。
世界模型的思路则完全不同。它学习的是世界接下来会如何演化,当前的状态是什么,施加一个动作之后会发生什么,再下一步又会怎样。它没有预设的终点,当我们没有新输入时,模型基于已有状态自主延续世界的发展;若我们中途注入新指令,模型就会结合当前状态重新推断后续走向,它可以随时被打断、被干预、被重写。
也正因如此,世界模型的训练难度远高于文生视频。
最直接的挑战是速度。世界模型需要在用户给出指令的瞬间就做出响应,任何明显的延迟都会打破沉浸感。HappyOyster 为此采用流式生成框架,将高维视频与多模态信息压缩为紧凑的动态 latent state,大幅降低单步生成的计算开销,使生成得以低延迟持续推进。文本、图像和漫游指令等控制信号被设计为可在线注入的条件变量,模型无需重置生成过程就能在任意节点即时响应外部交互。
更棘手的问题在于,如何让这个世界在长时间演化中保持一致性。生成时间越长,场景越容易出现内容漂移和结构退化,物理规律和空间结构慢慢失去约束,世界逐渐变得不像它原来的样子。为了对抗这种「失忆」,HappyOyster 引入持续状态复用机制,通过历史注意力状态的连续传递,让模型高效继承已生成信息并渐进更新,在更长的时间跨度上维持稳定的场景结构与动态连贯性。
在音画协同方面,不同于将音频作为视频的后期附加物单独建模,HappyOyster 采用统一的音视频生成框架,在同一世界状态下同步生成视觉与听觉信号。音频作为世界动态的一部分参与联合生成,自然建立跨模态的时间对齐关系。
目前世界模型领域已有几个代表性方向。Google 的 Genie 专注于实时交互式世界建模,但在多模态输入的统一表达和音视频联合生成上尚有局限;李飞飞团队的 World Labs 走的是 3D 空间结构化重建路线,侧重几何一致性而非像素空间的长时序动态生成。

HappyOyster 选择的是在像素空间内进行长时序、实时可交互的动态世界模拟,并在此基础上加入了音视频联合生成能力,这是一条此前鲜有人走通的路径,没有太多现成的答案可以参考。
结语
AIGC 走到今天,内容生成工具已经相当成熟。写文章、生图、做视频,这些需求都有了不错的解决方案。但这条赛道正在悄悄逼近一个新的拐点,即从「生成内容」到「构建世界」。
HappyOyster 的出现,让我们看到了这个方向的轮廓。它给每人一个可以随时走进去、随时修改、实时反馈的「自定义数字世界」。我们可以在里面漫游,可以在里面导演,可以把它分享给别人,让别人在我们构建的世界里继续演绎。
应用场景上,它的边界也远不止屏幕内的娱乐体验。文旅展陈、互动短剧、影视概念验证、品牌营销、直播共创…… 凡是需要实时感知、实时生成、实时反馈闭环的场景,它都天然适配。
更长远来看,一旦与摄像头、传感器、空间设备等硬件结合,HappyOyster 承载的就是一个可以被现实信号持续驱动的生成式环境系统。
但坦率地说,世界模型整体仍处于早期阶段。长时序下的物理一致性、复杂场景中的因果推理、对现实世界规律的深度理解,这些都是悬而未决的硬核挑战。HappyOyster 是这个方向上目前最接近「可用产品」形态的探索之一,但探索就意味着边界尚未确定。
这既是局限,也是想象力存在的理由。
