

“Alpamayo标志着汽车从‘单纯驾驶’迈入‘安全推理’时代。”
黄仁勋在英伟达GTC台北2026大会现场这样说道。
在近两个小时的演讲中,他不仅发布了专为智能体设计的Vera CPU、AI工厂实战指南DSX平台、RTX Spark超级芯片等产品,更在汽车行业最为关注的自动驾驶领域推出了开放推理模型——NVIDIA Alpamayo 2 Super。

这是一个320亿参数的开放视觉-语言-动作推理模型(Reasoning VLA),能够在完整驾驶堆栈中进行推理、规划与行动,从而为更安全、可规模化的 L4 级自动驾驶开发提供支持。
当然,这不是一次简单的模型升级,而是一场从“模仿驾驶”到“安全推理”的根本范式转移。
大会上,黄仁勋发布的产品从底层芯片到上层基础设施,从数据中心到个人PC,从云端智能到物理机器人,标志着英伟达正在经历从"GPU供应商"向"AI基础设施运营商"的根本性转变。
Alphamale 2:自动驾驶迈入推理新阶段
Alpamayo 2的核心突破在于"可解释性"。
传统端到端自动驾驶模型如同一个沉默的老司机,人们无法知道其决策过程。但Alpamayo 2则像一个"话痨司机",车辆可以用自然语言实时解释每一步决策,例如"由于前方静止车辆阻挡车道,向左微调"、"为左侧切入车辆让行"、"停车让行穿越交通"。这种"思维链"外化能力,显然更有利于获得人们的信任。

技术规格上,Alpamayo2实现了三项关键升级:360度全景感知(从前摄像头扩展至前、侧、后方),为变道、并线和交叉路口通行提供完整场景信息;新增"元动作(Meta-Action)"输出,包括让行、变道和停车等宏观决策,使模型能够为下游规划提供高级驾驶指令;以及具有2D定位的推理自动标注,将标注周期从数月压缩至数天,重塑辅助驾驶数据管线的成本结构。
更值得关注的是其"教师-学生"蒸馏架构。320亿参数的Alpamayo2 Super作为教师模型,可被蒸馏为紧凑型模型,运行在NVIDIA DRIVE AGX Thor车载计算平台上。这意味着车企无需从零构建大模型,就能通过英伟达的开放生态获得"即插即用"的推理能力。
自发布以来,Alphamayo系列下载量已接近40万次,并荣获COMPUTEX Best Choice Award车辆技术和智能座舱类别奖。
黄仁勋对大模型的评价是:"Alphamayo标志着汽车从'单纯驾驶'迈入'安全推理'。只有英伟达能够提供开放模型、仿真环境、现实世界数据以及智能体技能,支持全球无人驾驶出租车生态系统开发出理解边缘场景、解释自身决策、赢得公众信任,并安全地规模化部署到数百万台车上的L4级能力。"
"虚拟驾校":AlpaGym与OmniDreams
如果说Alphamale 2是"会思考的司机",那么英伟达同步推出的AlpaGym和OmniDreams就是它的"虚拟驾校"。
具体来看,AlpaGym是一个开源、高吞吐量的闭环强化学习框架。与传统开环训练"根据记录数据评估模型并生成单轮动作"不同,AlpaGym让模型在NVIDIA AlpaSim仿真环境中经历连续的决策-观察循环——每次刹车、转向和导航选择都会对环境产生真实影响,从而暴露出静态数据集所忽略的复合错误和边缘故障。这相当于让AI司机在"平行宇宙"中经历数百万次极端路况,把犯错成本降到零。

OmniDreams则是全新的生成式世界模型,能够生成逼真的闭环辅助驾驶场景,支持开发者大规模仿真罕见的长尾驾驶场景。结合NVIDIA Omniverse NuRec神经重建技术,开发者可以将真实车队数据重建为逼真的3D场景,并适配不同车辆传感器配置。英伟达甚至将因果链自动标注流水线以开源形式发布在GitHub上,能够从原始驾驶片段中自动生成基于决策的因果链标签,无需人工标注。
这套"仿真-训练-部署"闭环的意义在于:它让自动驾驶开发从"路测驱动"转向"仿真驱动"。车企不再需要投入数千台测试车在真实道路上积累十万公里数据,而是可以在数字孪生环境中完成90%以上的边缘案例验证,可以帮助车企降低研发成本、缩短上市周期。
“超级大脑":Vera Rubin与Vera CPU
大会上,黄仁勋还回顾了Vera Rubin。
黄仁勋表示,作为全球首款专为智能体AI设计的多机架Pod级超级计算系统,Vera Rubin已进入全面量产。
Vera Rubin将"推理"与"工具调用"的延迟压到了纳秒级敏感水平——这正是智能体决策所需的实时性基础,其中最具颠覆性的组件是专为智能体设计的Vera CPU。
黄仁勋这样介绍这款CPU:"AI智能体将成为计算资源的最大用户。Vera正是为这一未来量身打造的首款CPU——它具备卓越的性能、能效和可编程性,专为在超大规模下运行智能体AI而生。"
Vera CPU搭载了88颗Olympus核心,采用空间多线程技术,配备带宽高达1.2TB/s的LPDDR5X内存子系统。它的设计哲学与传统CPU截然不同:传统CPU为人类设计,人类对秒级延迟不敏感;智能体对延迟极度敏感,需要纳秒级响应,因此需要从头设计全新的CPU架构。

这款处理器的性能数据自然非常不错——Vera CPU在SQL查询速度上比顶级x86快3倍,在纽交所实时流处理性能上快6倍,在智能体沙箱性能上达到x86的1.8倍。它通过第二代NVLink-C2C互连技术,实现CPU与GPU之间高达1.8TB/s的相干带宽,并将英伟达机密计算扩展至整机架规模。
Vera BlueField-4 STX处理器更将Vera CPU与高性能网络、存储加速及芯片级安全融为一体,构建"设计即安全"的AI原生数据平台。
DSX:AI工厂制造蓝图
如何将这些硬件转化为客户的实际收益?英伟达的答案是DSX——一套建设AI工厂的参考设计蓝图。
DSX(Data Center Scale eXtended)平台是英伟达专为从零开始建设AI工厂而打造的完整实战指南。具体来看,DSX整合了开源模块化软件库、API、参考设计、英伟达加速计算平台及合作伙伴技术,打造出一个通用协同设计平台,专门用于AI工厂的设计、部署与运营。

其核心组件DSX MaxLPS(Lowest Power per Token System)直指自动驾驶产业的痛点:如何在既定电力预算内最大化每兆瓦Token产出。通过将45℃液冷技术与优化每瓦性能的机架级技术相结合,DSX MaxLPS让运营商能够在几乎不影响工作负载性能的前提下,将GPU运行在其最高能效点,从而额外部署高达40%的GPU。对于电力资源紧张、算力成本敏感的车企数据中心而言,这意味着同样的电费账单可以支撑更多的仿真训练里程。
DSX Sim则提供了面向AI工厂全生命周期的高保真仿真层,帮助英伟达、合作伙伴及客户对基础设施决策进行建模、验证和优化,贯穿从规划、设计到部署运营的每个环节。黄仁勋在演讲中强调:"借助DSX平台,你甚至可以在花出一元钱之前,就对整座工厂进行全面模拟,在一台机柜装上之前,就能验证其性能表现。"
DSX Flex是将AI工厂与电网服务连接,使其能够根据负载削减、需求响应和电价波动等电网信号动态调整工作负载。这与自动驾驶的"V2G(Vehicle-to-Grid)"愿景形成奇妙呼应:未来的自动驾驶数据中心不仅是算力消费者,更是电网的"柔性负载",在用电低谷时全力训练模型,在高峰时向电网反哺电力。
物理AI与机器人:Cosmos 3、Alphamale 2与Isaac GR0K
演讲的最后板块指向了智能体从数字世界走向物理世界的关键一跃。
黄仁勋提到,物理AI的核心难题是数据,互联网文本多为"第三人称视角",而机器人需要"第一人称视角"的物理世界数据。英伟达的解决方案是Cosmos 3——开放的物理世界基础模型,可作为视觉语言模型理解物理场景,生成物理准确的合成视频,作为模拟器完成策略训练闭环,更是Omniverse数字孪生平台的基础。它支持所有类型的机器人与物理系统开发,完全开放并允许用户二次定制。

在自动驾驶领域,英伟达推出Alphamale 2——全球首个可推理的自动驾驶开放模型,基于Hyperion平台(全球80%汽车制造商采用,97%出行服务对接),支持端到端推理规划。车辆可以用自然语言实时解释每一步决策逻辑,将"黑箱模型"转化为"可解释AI"。
值得一提的是Isaac GR0K人形机器人参考平台——25自由度双手,31自由度全身,身高6英尺/体重150磅,集成全套数据生成、仿真、训练、运行软件栈,面向高校和科研机构。原本需要数月的搭建准备工作,现在仅需数小时即可启动研究,旨在降低人形机器人研发门槛,推动整个领域发展。

黄仁勋为英伟达构建了一个完整的"智能体经济"基础设施版图:底层是Vera Rubin/Vera CPU的算力供给,中间层是DSX的AI工厂蓝图和企业级智能体工具包,上层是RTX Spark的个人智能体入口,以及Cosmos/Alphamale/GR0K构成的物理AI生态。
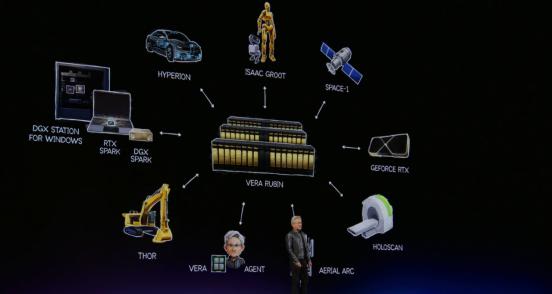
至此,英伟达的转型路径清晰可见:从卖GPU,到卖系统,再到帮客户建设"能赚钱的AI基础设施"。
