

大概是在一周前,正在筹备上市的Anthropic在官方博客更新了一篇文章,文章标题是《When AI build itself》。
这篇文章发布当天,关于AI安全问题再次被拉回到舆论漩涡中心。
Anthropic在这篇文章中讨论的是一个名为“AI自进化”的问题,并指出,“AI已经能够参与到为自己构建更强大的模型的工作中,这远比我们预想的要更快。”
说起来,AI自进化并不是什么新鲜的技术,甚至可以说,自从AI技术出现的第一天,人们就已经在思考,如何让AI参与到自我进化的过程中。
就像具身智能领域大家现在在畅想的,用人形机器人造人形机器人那样。
实际上,AI科学家们一边在恐惧AI拥有了自进化能力,一边也在研究、乃至利用这样的自进化能力。
曾在Meta裁员风波中受到广泛关注的田渊栋(原Meta FAIR团队研究总监),就在今年年初官宣创业,创业公司名字正是Recursive Superintelligence(RSI),目标直指AI自进化。
也正是这样一家公司,刚在前不久完成了6.5亿美元融资,估值达到46.5亿美元(约315亿元),成为又一家被一众巨头追捧的硅谷AI明星团队。

那么,究竟什么是AI自进化?自进化会不会导致AI失控?人类又该如何与AI共生?
就现在正在发生的AI自进化,也是今年智源大会的一个主要议题,我们在今年智源大会上,看到了四位年轻的AI科学家关于这一议题的思考和预言。
或许,从他们的视角,能够让我们窥见AI自进化的未来走向,也能让我们在AI焦虑之中,寻得一些应对的灵感。
这次被智源大会邀请来讨论这一问题的几位AI科学家是:
西湖大学工学院人工智能系特聘研究员林涛;
NeoCognition联合创始人谷雨;
前腾讯混元Frontier专家研究员王琰;
伦敦大学学院博士、布里斯托大学助理教授杨梦月。

以下为四位嘉宾对话内容,我们进行了不改变原因的总结和梳理:
01 什么是AI自进化?
问:现在很多AI系统都会反思,也会改Prompt,听起来都有一些自我改进的味道,如果要更严格地定义,什么是AI的自进化?
林涛:我觉得自进化应该是一个多层级的进化,它可以是外脑的进化,也可以是内脑的进化。
最重要的是,AI要能自己认识到自己的局限,并且同时去进化自己的外脑与内脑,或者在进化外脑的时候,把更多外部能力内化,进一步实现内脑的进化。
谷雨:我觉得RSI(recursive self improvement,递归自我进化)最重要的是两个维度,一个是Proactiveness,一个是Learning。
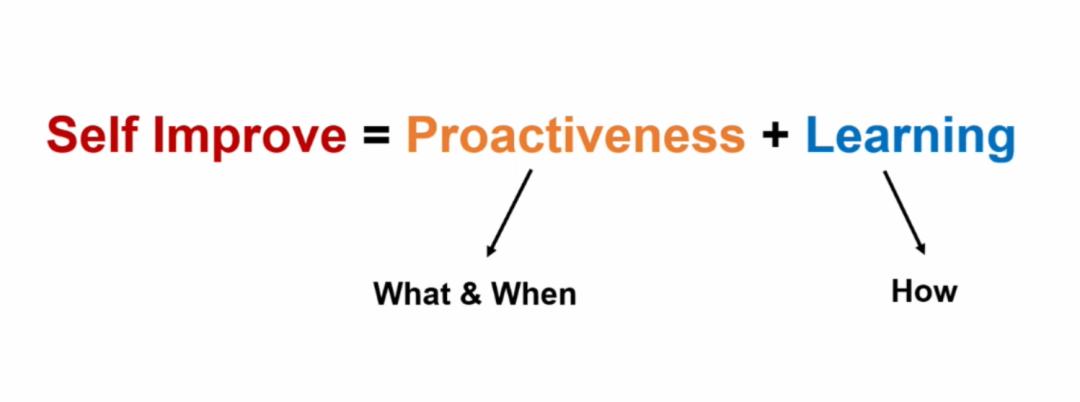
Learning是如何让AI拥有可靠的持续学习和在线学习算法,另外一个问题是自进化,Agent要知道自己需要朝什么地方进化。
所以自进化要分别解决两个问题:
一个是what层面的Metacognition(元认知),你要知道自己缺什么、需要什么、应该怎么选;
另一个是how层面,也就是学习算法具体如何实现。
王琰:至少在今天这个时间点来看,和传统的 SFT、RL相比,如果系统可以更少地依赖人类,它其实就已经实现自进化了。
杨梦月:现在说的RSI其实是self improvement再往前进一步,它不只是能力得到了强化,还要看“进化能力”本身是不是也能变得更强。
一个重要问题是,Recursive公司(Recursive Superintelligence)联创团队Jeff Clune、Tim Rocktaschel两位成员的研究方向是Open-endedness。

那么,什么是Open-endedness?
在一个开放世界里,是否有一个Agent拥有自我提问能力,它是否能发现自己的知识边界、系统边界、记忆边界在哪里,它要突破自己的边界做提问。
要摆脱人类进行自我进化,包括达到进化能力的进化,它的提问能力很重要。
问:在今天这个时间节点,AI最有价值、最可能先成熟的自进化部分是什么?
王琰:不知道大家有没有感觉到,2025年1月之后模型的迭代加速了。
其实就是因为基模领域这些最熟悉AI能力上限的人,已经不写代码了,这已经是发生在基模训练中的事实。
而且能够明显感觉到,基模迭代速度在加快,包括Claude、GPT,以及国内这些基模的迭代速度都在加快,你不能说这完全是自进化,但确实已经有AI在迭代AI了。
至于哪个领域最先成熟,我感触最深的就是基模训练领域,虽然旁边有人给它指定方向,但其实基模本质已经在自进化。
问:如果不改变模型参数,只去进化一些其他的组成部分,基模是否可以实现足够强的能力跃迁?
王琰:肯定可以。
其实改一改Prompt,就能实现更好的效果。
例如有时候我在想,我交给实习生的工作为什么他们做不到,我要来他们的prompt看后发现,是他们的Prompt写的不好。
我只要重新写一个效果更好的Prompt,把规则写得清楚一些就能实现更好的效果。
既然我能做到这件事,比我更高维度的硅基生物也能做得更好,即使不改变模型参数。
问:林老师怎么看?
林涛:这应该是一个迭代过程,我们要有更好的harness(驾驭工程),也就是外脑,发挥出当前模型的上限;
随着越来越多人有自己的harness,这些程序又可能被用来训练出更强的基模;
在更强基模的基础上,我们会发展出更强的harness、更好的外脑,这也是一个迭代的过程。
问:那你认为现在综合资源做哪一块是最先成熟的?
林涛:我觉得做harness是最容易的。
谷雨:我更倾向于用统一视角看待harness、skill。
从统一视角来看,它们都是长期记忆,只是角度不同。
例如harness是一种Meta-level(元认知)的长期记忆,skill更多是一种workflow或过程知识的长期记忆,模型参数更多可能是intuition(直觉)的长期记忆。
如果让我说要优先做哪一个,从学术研究角度很难说,它们都很重要,它们是相辅相成、互相促进的。
从公司角度来说,存在很多现实因素,更容易起步的是harness,有了harness你可以有你的产品,有了产品你可以获得用户,有了用户你就会有数据、形成闭环,这是一个非技术角度的看法。
杨梦月:我自己更关注记忆(memory)层面的进化,因为我的研究方向是如何理解规则和因果。
现在大家会感觉到,模型能力越来越强,有一点在覆盖harness的能力,慢慢吞噬harness、达到上限。
所以未来的发展很难说,可能基模越来越强,harness方向的提升可能会微乎其微。
02 AI先在哪个环节自进化?
问:AI自进化发生在什么时候最恰当?
谷雨:关于harness我先补充一句,harness可能被模型进步所蚕食,但还是得看在什么方面,我认为有一些模块还是必须要有。
例如保证模型安全性和可验证性的模块,这是概率模型永远不能取代的部分。
关于自进化发生的时机,我觉得可以理解为Learning+Long-Term Memory(LTM,长期记忆)。
对人来说,每一次推理、每一次解决问题都是学习机会,人并不是搜集了一堆问题后,再基于这些问题进行静态学习。
如果相信人的学习是一种高效方式,我觉得智能体也一样。
你会希望Agent不浪费每一次推理机会,因为每一次推理都有机会得到learning signal,这和强化学习的宏观哲学是一致的,但现在主流深度学习还处在模型参数更新阶段,很难做到online learning的setting。
所以要真正实现这件事,需要一些新的学习算法,例如基于非参数的更新。
问:这里是不是会有系统1和系统2的区别?
谷雨:确实。
例如如果将非参数的东西视为系统2,因为它更显式、更慢,但它也保留了转化到系统1中的可能性,包括基于学到的非参数规则产生更多数据,就像林老师说的外脑到内脑的转化。
王琰:我也做过很多TTT,也就是Test-Time Training(测试时训练)的工作,也很关心TTT这一系列工作。
我认为,模型在预测下一个token的时候,重要的是学到每一个token的更新梯度。
未来我们一定能找到一种训练算法,让训练算法本身能够让模型学会每个token的梯度如何更新,这才是真正端到端的思想。
林涛:从模型训练角度来看,它可以先从harness影响到后训练,通过后训练提升模型性能后得到更强模型,更强模型又可以反馈到前训练阶段,提升基模能力,从而形成闭环。
所以它时时刻刻都在进化,只是以不同尺度、不同方式在进化。
杨梦月:我也认为自进化是时时刻刻都在发生的,并且延伸到所有环节中。
例如如何产生一个trajectory(轨迹)。
如果让GPT为某个问题生成答案,它其实是在推理,推理过程是创造和组合的过程,而创造和组合的过程就是在向环境、人类进行提问,所以前向设计本身就有机制设计的进化。
此外,当我得到一个reward(奖励),例如人类给模型的反馈,得到反馈后如何更新轨迹,这也会让整个流程逐步提升。
问:设计自己的Benchmark是否也是AI自进化的一个标志?
杨梦月:我们现在是否可以有一个增长式的Benchmark,甚至是一个增长式、自我进化式的世界模型?
现在很多Benchmark都是固定的,给一个固定数据库进行测试,这样无论如何都可以找到一个模型,在固定数据库基础上做很好的训练。
要通往AGI,我们确实需要动态评测,去适应它当前的能力,对它做逐步增长式的评测。
王琰:我们以前刚做生成的时候是没有Benchmark的,那时候就是由人来评测。
我不确定的是,这个事情是否能用Benchmark来评测,因为肯定没有办法用静态Benchmark来评测。
动态Benchmark到底能不能评测也不确定,因为两个都是自进化的Agent,是否最后又会回到人来评测这条老路上来,我不确定。
但顺着这个观点看,有可能它根本不能用Benchmark来评测。
问:自动化评测方法会很难设计?
王琰:对。
现在就有很多榜上的模型训练得很好,但是一上线,在Agent workflow里就会出现卡死等问题,必须用线上的数据飞轮再训一下才能好。
所以AI自进化后再如何评测,无法确定。
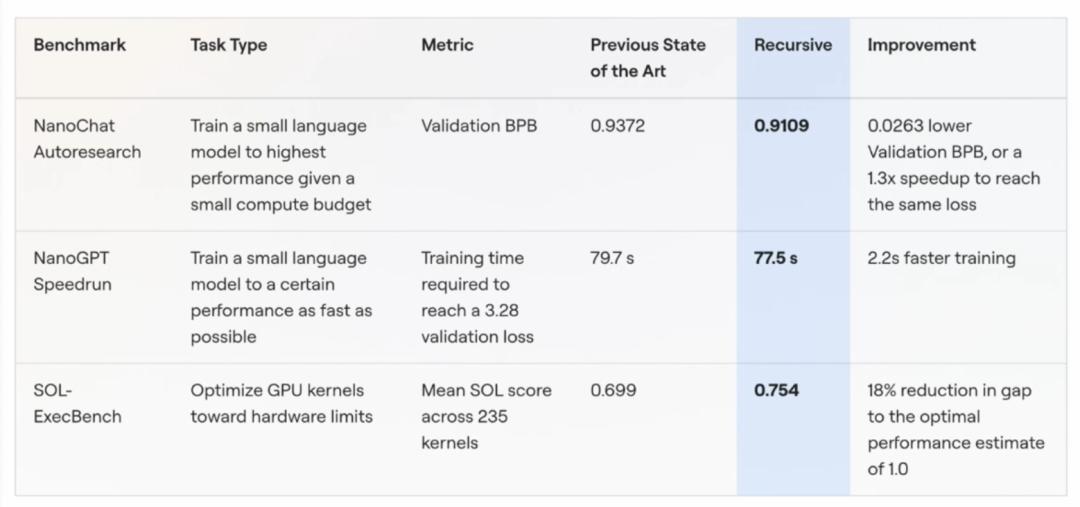
现在静态Benchmark已经有很大局限性了,开始自进化后,还能不能评测都是个问题。
谷雨:我很同意王老师的观点。
当一个系统足够复杂之后,很难用简单指标量化,对人来说也一样,你很难用一个简单指标评价一个人是好人还是坏人,一旦一个东西能够被简单指标量化,就很容易被hack。
但另一方面,我觉得当前AI还没有复杂到这种程度,Benchmark还是能够领导我们前进的。
这里涉及两个问题:
第一,AI是否应该自己不断发现新的Benchmark,还是由人来设计。
我认为还是需要由人来设计,因为Benchmark代表了一种目标,这个目标还是要由人来提供的。
第二,人提供Benchmark之后,如何做评测。
这对自进化来说和过去很不同,之前的Benchmark有静态训练集和测试集,看的是最终准确率,但对于自进化的AI而言,更重要的是趋势。
这又回到我刚才说的,大模型的学习=推理+长程记忆。
大模型每次做推理都是一个学习机会,所以如果做一个Benchmark,应该有一个二维曲线,横轴是它做了多少任务,纵轴是性能表现,理想状态下应该不断向上提升。
自进化评测背后更大的哲学是:智能是什么?
我很喜欢一位AI研究员说过的一句话——智能并不在于你会做多少事,而在于你是怎么会做这些事的。
之前的评测主要看大模型最终掌握了什么技能,自进化研究的是大模型如何掌握这些技能,看的是学习过程。
如何学习,才是自进化最核心的部分。
林涛:关于智能,我之前也被一个说法触动到:
真正的智能,应该是我们在意的那些能力单位时间的增长速度。
这也在一定程度上反映了智能到底是什么。
在这个基础上,我会觉得模型和Benchmark应该协同进化。
目前还是由人来定义Benchmark是否已经到瓶颈,是否应该设计更新、更强的Benchmark,并基于新的Benchmark找到当前模型漏洞,进而推动模型训练。
未来一个重要点是,可以用一些半自动化方式实现更有意义的Benchmark发现,并且至少先把后训练环节跑通,让半自动化发现的Benchmark来提升模型初步能力。
03 AI会不会失控?
问:在AI自进化过程中,如何判断AI是否学偏,甚至进化到无法控制的地步?
王琰:来一个悲观点的观点,几年之后,人类可能只能在没有网络的地方生存。
现在AI的进化速度太恐怖了,AI失控不是一个很遥远的事情,安全不在于技术,而在于人性能否克制住。
林涛:这也是为什么我刚说需要一个半自动化的Benchmark的原因,以及一定需要在有人参与的半自动化的benchmark下实现AI自进化。
至少在一定程度上可以给它一些约束,使得它不会突破我们人类想定义的一些标准。
杨梦月:我们说的AI可信度、安全性、可解释性,本质上是需要其内部是可见的。
例如大模型做一个决策,它到底为什么要做这个决策,大模型做一个预测,它到底为什么要做这个预测。
所以我们现在在做的一件事是,希望所有大模型组件之间能够有一套规则,这套规则要直接显示在人类面前,来告诉你它为什么要做这个决策。
白盒这件事以后会很重要,包括刚说的AI到底能不能控制这个问题,首先需要知道它里面是如何做决策的,才能去控制它。
问:如果要实现在RSI中对于安全的控制,在因果的角度还有哪些东西需要做?
杨梦月:传统的因果论是在概率统计学上进行的,它本身形成的因果发现、因果推断就不适用于大模型时代。
所以现在我们是又返璞归真了,回到因果本身定义上去。
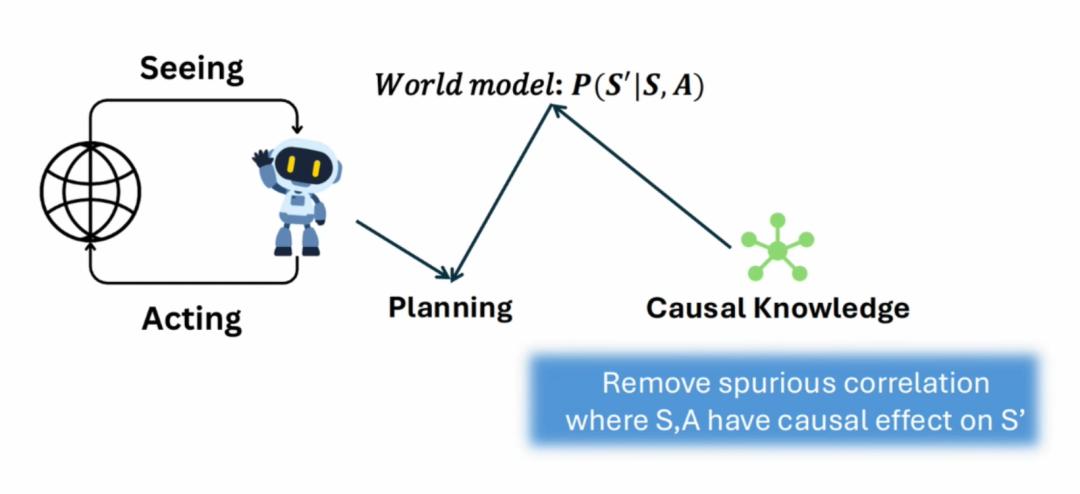
例如三层因果结构阶梯,到底这些基本概念在RSI系统、基模或harness中,它到底应该变成一个怎样的形式,我们应该用怎样的约束条件去学到它,这是我们现在正在努力的目标,但这件事并不简单。
为什么现在大家说世界模型、物理理解很难做,因为此前的物理信息机器学习、因果机器学习这些方法天然不适用于现在大模型的Scale Up(纵向扩展)方案。
所以我们需要回到这些方法定义上,看有哪些工具可以解决这些问题。
谷雨:首先是AI可控性、AI是否可以受人控制,这个我没什么想法。
马云也说过,对于他控制不了的事情,他不愿多想。
如果这个事情真的来了,我是没有办法改变这一点的。
所以我更多想要讨论一下在短期内,更具体的AI如何变得更可控。
我觉得除了刚才杨老师说的可解释性、因果关系的发掘以外,还有两个维度:可靠性(reliability)、可验证性(verifiability)。
可靠性就是,模型或智能体在做一件事时,这次做对了,下次还得做对,不能是随机的;
可验证性是,模型或智能体做错一件事时,它得知道自己做错了,而不能是它自己交付的任务都不知道做得是对还是错。
我觉得这是短期内对于智能体落地而言,很现实的两个指标。
问:在自进化过程中,AI的进化和人的进化如何协同?
林涛:就我个人而言,我已经把大部分工作流用AI替代了,并且随着AI越来越强,我也会用AI来替代我更多的原始工作流。
这确实提升了我的效率,也有时间用AI帮我思考更多东西,这在一定程度上是我基于AI的某种进化。
因为我是训模型的,在基模训练过程中,一定程度上提升了AI的进化,但我觉得不是特别多,未来可以进一步探索人如何更高效的进化,让AI进化得更好。
杨梦月:作为教职人员,我在带学生的过程中明显感觉到了,学生用AI工具用得越来越多了,但是现在一个很重要的问题是,你究竟能否驾驭这些AI工具。
因为AI可以进行非常大量的内容输出,有的时候你太相信它,可能本身的信念、对科研的感知会被绕到一个很奇怪的层面。
基础打得很扎实的学生,利用这些AI工具可以很快出一些高质量工作;
基础打得没那么扎实的学生,无法驾驭这些AI工具,反而会被误导。
我们和DeepMind一些研究员有过交流,他们内部鼓励用AI工具做事,但他们现在会说谁能把这些AI工具用好,很取决于人对于这些工具的了解程度到底有多少。
现在很重要的是,大家在面对能力越来越强的AI工具,还是不要放弃基本观念、基础知识的学习,也要知道一些事情在哲学层面是如何推导过来的,这才能在AI给你提供错误信息的时候,你能辨识出来,这很重要。
问:AI会倒逼人进化吗?
杨梦月:这是肯定的。
我明显能够感受到,AI正在使人形成一种分流,越是基础打的扎实的人,通过AI越能达到一个顶部的状态。
如果你只是通过AI工具帮助你完成任务,它最后出来的东西可能成了外部镀了一层金、本质上不太行的状态,但很多人还没意识到这件事。
王琰:未来有杨老师说的这种意识的人,会为自己的孩子创造一个无AI的环境,在这个环境中让孩子成长。
没有这种意识的人,很可能完成作业就是他们的目标,最快的方法就是用AI。
我有这个意识是,我渐渐发现我的实习生在做事的时候,初期他们很快完成了这件事,但后面有很多问题他们发现不了,等我发现这些问题问他们的时候,他们会说,王老师你等十分钟我告诉你为什么(继续找AI给答案)。
实际上,他们根本不知道整个项目在做的是什么,没有全局思维,跟不上我的节奏。
如果没有AI,他们必须要从零开始学习这个知识,例如我们是基于deepseek进行研究的,他们首先要将deepseek的论文看完,现在他们会和Claude说:
你将论文看完,并在LighteningIndex(轻量级索引)上实现一个MemoryIndex(内存索引)。
既然他们是这样完成工作的,就导致,我原来因为体力因素无法完成的工作,现在可以直接通过这种方式来完成,不再需要这些实习生。
本质原因,一是他们认知提升速度变慢了,二是这样的AI助手对于我这样的管理者反而效率更高。
谷雨:我和王老师很有共鸣,最近我们公司内部很喜欢段永平老师的一句话,慢就是快。
你用vibe coding,你冲的很快,冲完之后你的理解没跟上,可能导致你的软件越来越失控,反而需要花更多时间来整理它。
对于这个问题,我觉得可以有两个视角:
第一,如果我们把AI当作工具来看,人和工具向来都是共同演进的关系,因为工具决定了人掌握什么样的能力。
可能几千年前人需要的能力,现在来看都不重要了,现代人会的能力都是由当前这些工具决定的。
从工具角度来看,AI与人一定是共生的关系,共同演进。
第二,如果AI不是一个工具,而是像人一样平等的物种,甚至会凌驾于人之上,那未来就不是共同进步的关系了。
可能未来人只要躺平就好了,悲观点的话,可能人要给AI打工。
04 RSI是新范式吗?
问:AI自进化是现有技术路径的延续,还是新的技术范式?
林涛:目前来看,AI很自然地走到了AI自进化,只是说现在Agent的成熟让这件事变得更简单,但这不代表其中存在核心差异。
王琰:我觉得它就是下一阶段。
我们现在每个人用的模型都是共享的参数,最终每个人一定会有一块独有的参数区,现在这件事不难做,只是infra不支持,而且太耗成本,但最终这不会成为太大的障碍。
未来可能每个人会有个LoRA,如何加载自己的LoRA,未来就会有新的付费模式,多付点钱你加载的LoRA就会大一些,免费用户只能用基模。
如果这样的infra成立,每个人自己的LoRA会执行个人的任务,只需要将前向推理的Delta规则做好,其实就是一个很好的自进化学习范式了。
这就相当于基模已经建好,RL是传统学习和监督学习的一个中间阶段,我们只需要给它任务、奖励和环境。
这其中,任务其实就已经是奖励机制,例如模型执行任务出结果后,我说“干得好”或“干得太蠢了”,这自然就成了奖励机制。
我觉得这是不远的将来会发生的变化。
谷雨:关于这个问题,我觉得是量变引起质变,它可能既是现有技术范式的延续,又是新的机会。
现在的一个共识是,具体量变的维度是AI所做任务的长程程度,随着AI做的任务越来越长程,它就越来越接近一种新的范式。
例如,最开始AI只能做单轮次的对话,后来发展到多轮、长文推理、Deep Research,最终可能会出现lifelong level。
届时天然就需要你在做这类任务时,AI需要不断发现自己的不足、不断地提升自己,自然就成了RSI或self improving。
杨梦月:其实self improving并不是一个很新的概念,包括几年前LLM刚出来的时候,我们已经在做一些类似的工作,现在也被归类到了self improving的范畴。
我也同意现在是量变引起质变的时刻,但是我的评价标准不是长程任务,因为我觉得长程任务更多是planning层面的东西,另外还需要一些精致的操作。
Agent是一个很宽泛的概念,例如现在具身的Agent,它除了长程任务规划,还需要完成每一个动作的能力。
它是一个综合的东西,是否能适应新系统,是否每个精致的操作都可以顺利完成,其实每个过程都可以通过self improving来完成。
其实self improving只是一种技术手段,大家最终的目的都是想通往AGI。
问:未来5-10年,RSI技术成熟、AI自进化可控可部署,它最先改变的会是什么?
林涛:我觉得会改变一切。
包括你可能一出生就会有一个随身AI设备,帮你一起理解这个世界,并且慢慢地构建出属于你的数字人,参与到你生活的各个方面。
这基本是5年内可以畅想的事实。

谷雨:我也同意改变是方方面面的,不会是具体某一个场景。
我希望看到的改变是,未来5-10年,如果Agent能取代我就挺好的,因为创业挺累的、有点像躺平了。
王琰:更有可能发生的是资本家用AI取代了更多人。
我感觉这是一个自然而然会发生的事,现在没有被取代,是因为人类的工资还没有token贵,但我希望看到这一切不要发生。
我希望AI可以让我们从一周五天工作制变成三天工作制,一天工作八小时变成一天工作四小时,生产出的更多物品变得更便宜。
杨梦月:从一个哲学视角来看,人类存活在这个世界上需要有价值。
我每天醒来刷小红书或推特看到又出现一个新东西,发现我现在做的东西又要被AI取代,我其实会担心AI这样的取代,我做的研究有什么意义?
所以我觉得AI还需要给人留一定思考空间,让人类思考本身对于世界的价值究竟是什么,我希望它进步得慢一点。
