

OpenAI 刚刚把第一颗自研推理芯片推到台前,Anthropic 也被曝开始接触三星,探索围绕自研 AI 芯片展开合作。
两个最受关注的大模型公司,几乎在同一时间把手伸向了芯片。
只是 Anthropic 的动作还处在早期阶段。
Anthropic 被爆也要自研芯片,还找了三星代工
美国当地时间 7 月 2 日,TechCrunch 援引 The Information 报道称,Anthropic 已与三星接洽,探讨围绕拟议芯片展开合作,但公司尚未确定这颗芯片具体用于什么场景、如何部署进服务器,以及最终算力水平。
Anthropic 对外回应时也没有确认与三星的具体合作,只表示包含谷歌、Amazon 和英伟达芯片在内的多元化硬件架构,仍将是其计算战略的关键支柱。
这句话反而是理解 Anthropic 芯片计划的关键。它不是从多供应商路线突然转向“完全自研”,更不是马上要摆脱英伟达,而是在原本的多硬件架构之上,尝试增加一层更深的自定义能力。
换句话说,AI 公司过去是“买算力”,现在开始尝试“定义算力”。
事实上,Anthropic 早在今年 4 月就已传出自研芯片信号。
Reuters 当时报道称,Anthropic 正在探索设计自有 AI 芯片,主要是为了应对支撑更先进 AI 系统所需芯片的短缺。但报道同时强调,这一计划仍处于早期阶段,公司可能最终只采购 AI 芯片而不自研,当时它也尚未确定具体设计。
但在自研芯片传闻之外,Anthropic 的招聘页面显现出了一些端倪。
今年 2 月份,它启动了“Accelerator Platform”团队负责人的招聘。

当时,他们在招聘说明中表示,他们正在搭建一支横跨硬件、分布式系统和 ML 基础设施的加速器平台团队。这个团队的任务不是单纯“买卡”,而是把不同代际、不同供应商的芯片接入 Anthropic 的第一方推理集群,并把底层硬件差异抽象成稳定的平台能力。
岗位说明称,每次用户通过 API、Claude.ai 或云合作伙伴调用 Claude,请求都会落到 AI accelerator 上,而且不是一种芯片,而是 TPUs、Trainium chips、GPUs。说明中还称,需要有人把“raw silicon”变成 Anthropic 内部可以无感使用的平台。这个团队负责 Anthropic 第一方推理集群中新硬件平台的 bring-up 和 normalization,介于底层系统团队与生产推理服务之间。

另一个招聘网站上显示,Anthropic 在招聘 GPU 效能工程师。
岗位描述称,该角色要负责最大化 GPU 利用率和性能,提升推理效率;工作横跨自定义内核开发、分布式系统架构,从底层张量核心优化到数千张 GPU 的同步调度。
与传统意义上的“芯片设计团队”不同,Anthropic 当前公开招聘中更清晰的一条线,是围绕 GPU/TPU/Trainium 的软件栈和性能工程。它需要的人才不是只会跑模型,而是能理解内核、编译器、低精度、互连、内存带宽和分布式调度的人。
这类人才虽然不等同于 ASIC 物理设计工程师,但正是模型公司进入自定义芯片前必须补齐的能力层。

为什么是现在?
为什么是现在?答案首先来自需求。Anthropic 今年以来持续扩张算力。
4 月,它与谷歌和博通签署协议,获得从 2027 年起上线的多吉瓦级下一代 TPU 容量。
Anthropic 在同一份公告中表示,Claude 运行在 AWS Trainium、Google TPU 和 Nvidia GPU 等多种 AI 硬件上,可以把不同工作负载匹配到更合适的芯片,从而提升性能和韧性。
同月,Anthropic 还与 Amazon 扩大合作,锁定最多 5GW 用于训练和部署 Claude 的新容量,并称目前已使用超过 100 万颗 Trainium 2 芯片训练和服务 Claude。
这些数字背后,是大模型商业化进入规模化阶段后的新压力。
Claude 不再只是一个模型接口,而正在变成面向企业、开发者、编码、知识工作和 Agent 场景的基础能力。
Anthropic 在与 Amazon 合作的公告中提到,企业和开发者对 Claude 的需求在 2026 年加速增长,消费者免费、Pro、Max 等层级使用量也大幅增加,这给基础设施可靠性和性能带来了压力。 当产品越成功,推理请求越多,模型公司就越容易被算力成本和供应确定性反向约束。
过去 AI 公司拼的是谁能拿到更多 GPU,现在拼的是谁能把模型、芯片、内存、网络、数据中心一起调优。

Anthropic 自研芯片的举动被外界视为对 OpenAI Jalapeño 项目的回应。
6 月 24 日,OpenAI 与博通发布了 Jalapeño,称其为 OpenAI 首款“Intelligence Processor”,也是双方多代计算平台的第一颗 AI 加速器。

OpenAI 表示,这颗芯片从一开始就围绕大语言模型推理设计,而不是把通用 AI 加速器改造来跑大模型。
它的设计参考了 OpenAI 的模型路线图、内核、服务系统和产品需求,并由博通、Celestica 等合作方参与芯片实现、板卡、机架系统、高性能网络和规模化生产。
这说明,头部模型公司自研芯片首先瞄准的并不一定是训练,而是推理。
训练决定模型能力上限,但推理决定商业化成本下限。
ChatGPT、Claude、Codex、Claude Code、Claude Cowork 以及未来更多 Agent 产品,本质上都在持续消耗 token。
每一次用户提问、每一次代码生成、每一次工具调用、每一次长上下文规划,都会变成真实的算力账单。随着 AI 产品从“偶尔使用”走向“持续运行”,推理成本会越来越像云计算时代的带宽和存储成本,决定产品毛利、响应速度和用户体验。
OpenAI 对 Jalapeño 的描述也很值得注意。
它强调这颗芯片要减少数据移动,在计算、内存和网络之间取得平衡,让实际利用率更接近理论峰值。OpenAI 还称,早期测试显示其性能 / 瓦表现将显著优于当前最先进水平,并计划以吉瓦级规模部署到数据中心伙伴体系中。
Reuters 则报道称,Jalapeño 主要用于推理,也就是回答 ChatGPT 这类产品的用户请求。
OpenAI 计划在今年年底部署,服务器系统由 Celestica 构建,芯片交由台积电制造,样片已在实验室运行 OpenAI 的 GPT-5.3-Codex-Spark 模型。
这才是自研芯片最有价值的地方:模型公司可以把自己对模型架构、推理模式、服务系统、内存访问、网络通信和产品交互的理解,直接写进硬件设计。
AI 公司为什么都绕不开自研芯片
通用 GPU 要服务整个市场,而模型公司自定义芯片只需要服务自己的核心工作负载。
它未必能在所有任务上击败英伟达,但只要能在高频、稳定、可预测的推理场景里,把单位 token 成本打下来,就足以改变 AI 产品的经济模型。
OpenAI 的 Jalapeño 已经把这个趋势推到台前。这说明,自研芯片真正瞄准的并不只是“算力更多”,而是“算力更适配”。
对 ChatGPT、Claude、Codex、Claude Code、Claude Cowork 这类产品而言,训练决定模型能力上限,但推理决定商业化成本下限。每一次用户请求、每一次代码生成、每一次长上下文处理、每一次 Agent 工具调用,最终都会转化为真实的推理成本。
OpenAI 在介绍 Jalapeño 时也写得很直白:推理是 AI 触达用户的地方,成本、速度和可靠性的改善,最终会表现为更快的 ChatGPT 响应、更低的 API 构建成本,以及需求高峰期更稳定的访问体验。
但这并不意味着 AI 公司正在全面“去英伟达”。恰恰相反,OpenAI 和 Anthropic 的动作更像是多供应商策略的升级。
OpenAI 在 Jalapeño 之外,仍然与英伟达达成了至少 10GW 的 AI 数据中心系统合作。Anthropic 的路线也类似。
所以,这些 AI 巨头们自研芯片的意义不是要替代英伟达,而是增加主动权。更实际的意义,主要有以下四个方面:
第一,它可以在供应紧张时增加额外产能入口。
第二,它可以把部分推理工作负载迁移到更符合自身模型和产品需求的硬件上。
第三,它可以让 AI 公司在与云厂商、芯片厂商、代工厂、内存供应商谈判时,拥有更多选择。
第四,它可以让模型路线图和硬件路线图形成长期协同,而不是被动等待外部芯片厂商适配自己的模型需求。
这也是为什么三星这条线值得重点看。如果 Anthropic 最终与三星合作,这不会只是一笔普通代工订单。
Anthropic 在 H 轮融资公告中把美光、三星和 SK 海力士列为“战略基础设施伙伴”,并称这些公司的技术在全球内存、存储和逻辑芯片供应中扮演关键角色。
随着 Claude 需求增长,这些合作关系将帮助 Anthropic 更可靠地扩展算力。韩国媒体《Pulse》也指出,三星和 SK 海力士作为战略基础设施伙伴参与 Anthropic 融资后,外界开始关注三星是否会在内存之外,通过芯片代工业务参与 Anthropic 未来的 AI 芯片制造。
报道特别提到,在美光、三星、SK 海力士三家内存伙伴中,只有三星拥有芯片代工业务。
这里的关键不只是“谁来代工”,而是高带宽内存、逻辑芯片、先进封装和资本关系正在被重新打包。
AI 芯片并不是一颗裸芯片就能解决问题,它需要与高带宽内存、互连、网络、机架、电力、散热和软件栈一起工作。亚马逊云科技对第二代训练芯片 Trainium2 的技术介绍就能说明这一点:单颗 Trainium2 芯片内置 96GiB 高带宽内存,支持 2.9TB/s 的高带宽内存带宽;一台 Trn2 实例集成 16 颗 Trainium2,总计 1.5TiB 高带宽内存和 46TB/s 高带宽内存带宽;Trn2 UltraServer 则通过 64 颗 Trainium2 和 NeuronLink 互连扩展到更大系统。
高带宽内存之所以重要,是因为它已经成为 AI 基础设施里最稀缺的环节之一。
路透社报道称,AI 热潮正在引发全球内存芯片供应危机,短缺范围从传统内存扩展到数据中心 AI 芯片所需的高带宽内存,部分内存价格自 2025 年 2 月以来已翻倍,SK 海力士曾告诉分析师,内存短缺可能持续到 2027 年末。
同一篇路透社报道还提到,OpenAI 曾与三星和 SK 海力士签署初步协议,为“星际之门”项目供应芯片。到 2029 年,该项目可能每月需要多达 90 万片晶圆,约为当前全球每月高带宽内存产量的两倍。
从这个角度看,Anthropic 接触三星,真正值得关注的不是“Anthropic 也要造一颗芯片”,而是它可能在提前绑定韩国半导体供应链:资金、内存、逻辑芯片代工、先进封装和长期产能。
对 Anthropic 来说,这是算力供应安全,对三星来说,这是其芯片代工业务争取 AI 客户的机会。
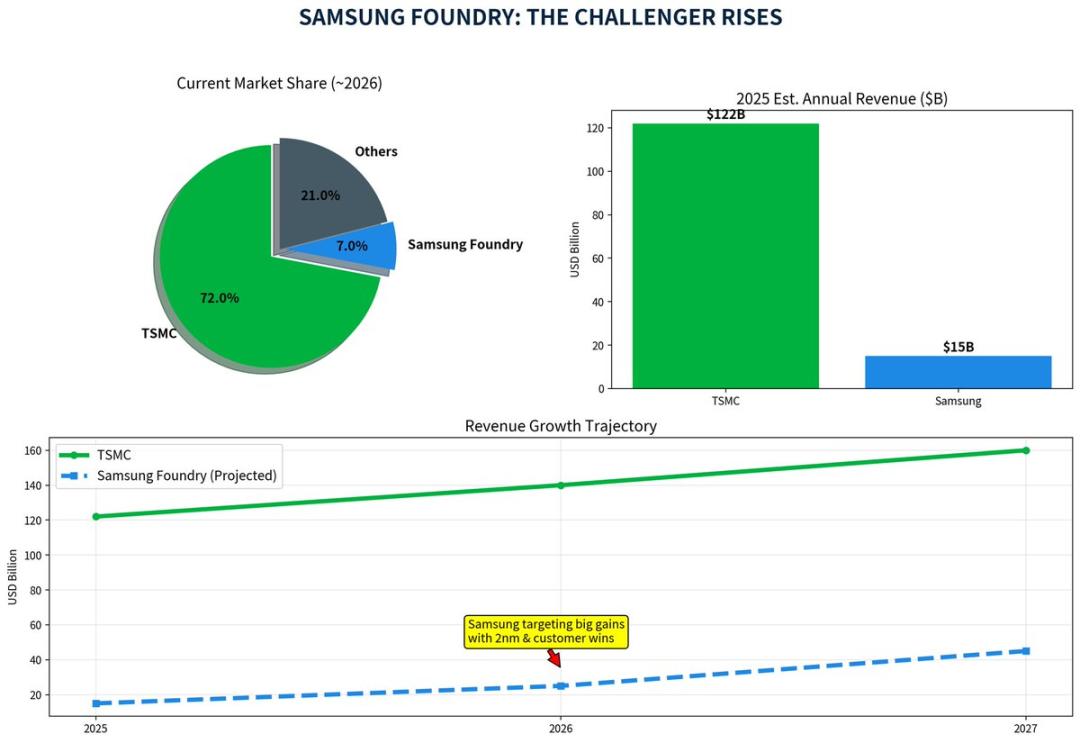
《星报》援引《韩国先驱报》的报道称,三星目前在全球芯片代工市场排名第二,份额为 7 %,但与台积电 72 % 的份额仍有明显差距,如果能承接 Anthropic 未来 AI 芯片制造订单,将有助于提升其芯片代工业务的想象空间。
不过,自研芯片也不是捷径。
Reuters 在 4 月关于 Anthropic 探索自研芯片的报道中提到,设计一颗先进 AI 芯片可能需要约 5 亿美元成本,因为公司需要雇佣熟练工程师,并投入资金确保制造过程没有缺陷。OpenAI 的案例同样说明,芯片设计只是第一步,真正落地还要依赖 Broadcom 的硅实现和网络能力、Celestica 的板卡与机架系统能力,以及后续规模化生产和数据中心部署。
更大的挑战在于,AI 模型本身变化太快。今天适合某一代模型推理模式的芯片,到了下一代模型、下一种 Agent 工作流、下一种上下文长度或多模态架构,未必仍然最优。自研 ASIC 的优势是专用,风险也正是专用。一旦模型路线变化快过硬件迭代速度,定制芯片就可能从优势变成包袱。
因此,未来几年 AI 巨头的芯片路线大概率不会是单一答案,而会是一个组合:英伟达 GPU 继续承担最通用、生态最成熟、训练与推理都可覆盖的核心角色;Google TPU、AWS Trainium、AMD GPU 等成为大规模替代与补充;OpenAI、Anthropic 等模型公司则会在推理等高频场景中推进自定义芯片,把最稳定、最可预测、最烧钱的工作负载拿回来优化。
这场竞争的终局,是所有 AI 公司都不得不搞懂芯片这回事儿。因为当 AI 进入真正规模化交付阶段,算力不再只是后台成本,而是产品能力本身。谁能以更低成本、更稳定供应、更高能效持续生产 token,谁就能在模型价格、响应速度、企业交付和毛利率上获得长期优势。
Anthropic 与三星的接洽还没有落成实质订单,但它释放的信号已经足够清晰:大模型战争正在打到供应链深处,且会越走越深。
参考链接:
https://techcrunch.com/2026/07/02/anthropic-is-discussing-a-new-custom-chip-with-samsung/
https://www.reuters.com/business/anthropic-weighs-building-it-own-ai-chips-sources-say-2026-04-09/
https://x.com/StockSavvyShay/status/2072680938140823655
https://jobs.menlovc.com/companies/anthropic/jobs/67996699-engineering-manager-accelerator-platform
https://pulse.mk.co.kr/news/english/12060958
https://www.thestar.com.my/business/business-news/2026/06/01/samsung-sk-hynix-acquire-stakes-in-anthropic
