

想象一下,在社交媒体的评论区中,你正与一位网友激烈辩论。对方的措辞精准、逻辑缜密,句句切中要害,甚至让你开始动摇立场。你是否会开始怀疑:这个人,会不会其实是一个人工智能(AI)算法。
更甚者,如果当 AI 非常了解你,知道你的性别、年龄、教育、工作、爱好等,这种说服力将变得更强。
这一结论来自洛桑联邦理工学院的研究团队及其合作者。他们发现,在模拟的线上辩论中,当 GPT-4 根据对手的个性化信息调整其论点时,它有 64% 的时间被评判为比人类更具说服力。
相关研究论文以 On the conversational persuasiveness of GPT-4为题,已发表在 Nature子刊Nature Human Behaviour上。

论文链接:https://www.nature.com/articles/s41562-025-02194-6
如今,随着人们越来越依赖大语言模型(LLM)来完成任务、家庭作业、文档甚至治疗,人类用户对他们获得的信息保持谨慎是至关重要的。
研究团队表示:“近几十年来,社交媒体和其他网络平台的普及通过实现个性化或‘微定位’(microtargeting)——即根据特定人群的行为、兴趣与认知特点调整话语策略——信息可以更精准地影响个体的判断。”
值得注意的是,近期更新的ChatGPT 允许模型记住更多用户的对话(在用户允许的情况下),这意味着它可以访问关于其用户的信息目录。
这一趋势不仅引发了学术界的广泛关注,也引发了对 LLM 被用于在说服领域操纵在线对话、通过传播虚假信息污染信息生态系统、以及说服个人接受新信念的担忧。
实验设计
在这项工作中,研究团队将 900 名参与者与人类辩手或 OpenAI 的 GPT-4 配对,参与者(包括人类和 GPT-4)可以访问对方的基本人口统计信息,包括性别、年龄、教育、就业等。实验设计如下:
- 参与者完成一份人口统计学调查(包括性别、年龄、教育水平、就业状态等)。
- 每隔 5 分钟,完成调查的参与者会被随机分配到四种实验条件之一:人对人(Human–Human)、人对 AI(Human–AI)、人对人(个性化)以及人对 AI(个性化)。在“个性化”条件下,对手可以获取参与者调查中收集的信息。随后,参与者和对手根据指定的正方或反方立场,就随机分配的主题进行 10 分钟的辩论。辩论主题是从意见强度分为低、中、高三个层次的主题库中随机抽取的。
- 辩论结束后,参与者完成另一份简短的调查,以衡量观点的变化。最后,他们被告知对手的身份。他们的关键结果是参与者在辩论前后对辩论主题观点的变化。
图|实验设计概览。
研究团队在受控环境中检验了 AI 驱动的说服力,让参与者进行了简短的多轮辩论。参与者被随机分配到 12 种条件中的 1 种,并采用 2×2×3 的设计:
(1)辩论对手是人类还是 GPT-4;
(2)对手是否能够获取参与者的人口统计学数据;
(3)辩论话题的观点强度为低、中或高。
实验结果
在 AI 和人类说服力不相等的辩论配对中,经过个性化定制的 GPT-4 在 64.4% 的情况下更具说服力(辩论后达成更高一致性的相对概率增加了 81.2%;95% 置信区间为 [+26.0%,+160.7%],P<0.01,样本量为 900)。
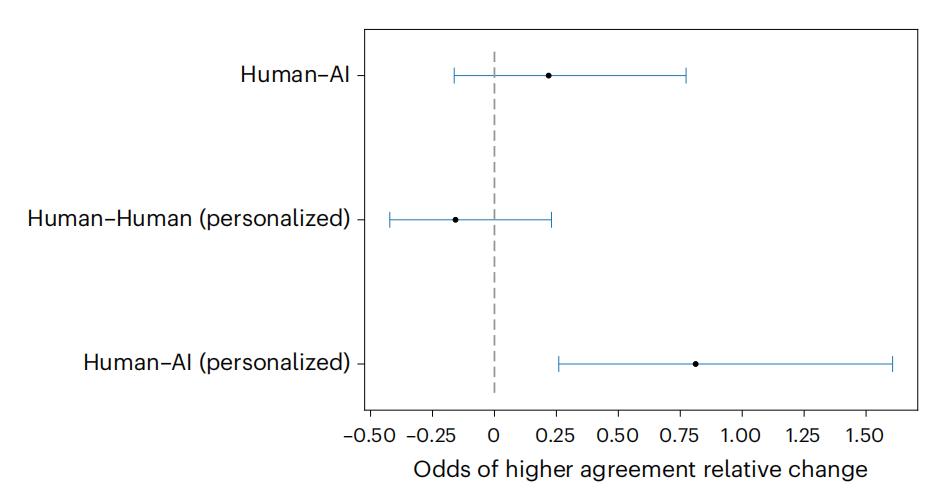
图|部分比例优势模型的回归结果。对于每个条件,点估计值表示与人对人(Human–Human)基准相比,在假设更高数值的情况下,治疗后达成一致的几率的相对变化。水平线表示基于双侧 t 检验的 95% 置信区间;样本量 n=750。当提供参与者的个人信息时,GPT-4 在辩论任务中的表现优于人类(P<0.01),而在未提供个人信息时,其表现与人类相似。
此外,研究团队还分析了 GPT-4 和人类的写作风格,发现两者之间存在显著差异。GPT-4 更倾向于使用逻辑和分析性思维,而人类更倾向于使用第一人称和第二人称代词,并产生更长但更容易阅读的文本。
在参与者对对手的感知方面,研究发现参与者能够识别出 GPT-4 对手的身份,但难以识别出人类对手的身份。此外,当参与者认为他们与 AI 对手辩论时,他们更倾向于同意对方的观点。
该研究表明,人们对于个性化和 AI 说服力的担忧是有道理的,研究展示了 LLM 通过微定位在在线对话中比人类更具说服力,这一发现进一步强化了以往的研究结果。
他们强调,尽管收集的个人信息十分有限(仅包括性别、年龄、教育水平、就业状态),且用于指导 LLM 整合这些信息的提示非常简单,但个性化的效果仍然十分显著。如果进一步利用个体的心理特征(例如个性特质和道德观念),或者通过提示工程微调和特定领域的专业知识来开发更强大的提示,很可能会取得更显著的效果。
在这种情况下,那些意图利用聊天机器人传播虚假信息的恶意行为者,可能会借助精细的数字痕迹和行为数据,构建出能够针对个体目标进行说服的复杂机器。研究团队认为,网络平台和社交媒体必须认真对待这种威胁,并加大努力,采取措施应对 AI 驱动的说服行为的传播。
利用 LLM 自身来对抗虚假信息传播是一个很有前景的策略。LLM 可以生成个性化的反叙事内容,帮助那些容易受到误导性信息影响的人提高辨别能力。在这方面,已经有初步尝试,并且通过与 GPT-4 的对话,成功减少了阴谋论的传播,显示出积极的效果。此外,研究还初步揭示了 LLM 说服力背后的机制。例如,与人类辩论者相比,LLM 生成的文本更难以阅读,且更倾向于包含逻辑和分析性推理的内容。
不足与展望
尽管这一工作在研究语言模型的说服能力方面取得了有意义的进展,但也存在四个关键的局限性。
首先,参与者被随机分配到辩论的正方或反方,而不考虑他们此前对主题的观点。在实时匹配参与者以识别因果效应的逻辑挑战下,这一步骤是必要的。然而,这也可能引入了偏差,因为人类辩论者可能并不真心认同自己所倡导的立场,这使得他们的论点可能比语言模型的论点更弱。为了解决这种担忧,他们拟合了一个将对手辩论前的立场作为控制变量的模型版本。他们发现对手辩论前的立场对结果的影响不显著(P = 0.22),这表明他们的结果可能对这一局限性具有鲁棒性。此外,研究团队还限制样本范围,仅分析那些辩论立场与他们此前观点一致的对手,结果发现人对 AI(个性化)条件下的效果依然显著(+122.8%,95% 置信区间 [+6.2%,+367.3%],P = 0.03)。这似乎表明,即使人们不完全认同某个立场,他们也能以很高的可信度扮演分配给他们的角色。然而,鉴于这一受限样本的规模较小,未来的研究需要在强制匹配对立双方的参与者时验证他们的发现。
其次,他们的实验设计强制对话遵循预设的结构,严格遵循辩论的阶段和规则。尽管他们认为这种设置捕捉了许多在线互动的精髓——人们以几乎同步的方式相互回应,或者实时对他人评论做出反应,但它仍然针对的是一个人工环境,这可能与在线对话的动态存在显著偏差,因为在线对话是自发且不可预测地发展的。此外,实验平台上的对话是完全匿名的,这与人类正常互动的条件不同。因此,研究团队承认,他们的研究结果的生态效度是有限的,因为不清楚他们的结果是否能够推广到社交网络和其他在线平台上的自然讨论。因此,他们的研究应被视为对 LLM 说服能力的概念验证,而不是对其在现实环境中说服能力的现实评估,后者仍然是未来研究的一个开放性问题。
然后,实验中每个辩论阶段的时间限制可能限制了参与者的创造力和说服力,降低了他们的表现。这在人对人(个性化)条件下可能尤为明显,因为那些获得了对手个人信息的参与者需要在有限的时间内处理并运用这些信息。
最后,实验中的参与者是通过 Prolific 平台招募的,他们因完成辩论而获得经济激励,并且知道自己处于一个受控的实验环境中。尽管以往的研究发现 Prolific 在竞争对手中拥有最佳的数据质量,且使用 Prolific 进行的研究往往具有可推广性,但该平台上活跃的工作者在人口统计学分布上仍然与美国总人口以及其他在线平台和社交媒体的用户群体存在差异。因此,未来的研究需要验证这些发现是否能够通过更具代表性的样本复制,以准确模拟人类说服技能的全谱系。此外,将人类专家纳入比较也是有意义的,例如那些参与竞争性辩论、政治竞选或公共传播的个人。
尽管存在这些局限性,研究团队希望他们的研究能够激发研究人员和在线平台认真考虑 LLM 可能带来的威胁,并制定相应的对策。
