

奥特曼使用大模型的方法,竟然是错的?
来自沃顿商学院等机构的最新研究发现,备受奥特曼喜爱的“直接回答”提示,竟然会显著降低模型准确率。
不过另一方面,这项研究也发现,在提示词中加入思维链(CoT)命令同样不好用——
CoT提示对于推理模型非但没有效果提升,反而会增加时间和计算成本。
而一些前沿的非推理模型,CoT提示可以带来效果提升,但答案的不稳定性也随之增加了。
研究团队使用GPQA Diamond数据集,针对现在主流的推理和非推理模型,分别在启用和不启用CoT的情况下进行了测试。
结果就是对于推理模型,CoT的作用十分有限,比如对于o3-mini,CoT带来的准确率提升只有4.1%,但时间却增加了80%。
非推理模型的结果则要复杂一些,但总之要不要用CoT,也需要对收益和投入进行仔细权衡。
所以CoT到底该不该用呢?
实际上,这项研究针对的是用户提示词中的CoT命令,并不包括系统提示词设定,更不是CoT本身。
CoT提示词作用有限,甚至还有反效果
这项研究使用GPQA Diamond数据集作为基准测试工具,该数据集包含了研究生水平的专家推理问题。
实验过程中,研究团队测试了这些模型:
- 推理模型:o4-mini、o3-mini、Gemini 2.5 Flash
- 非推理模型:Claude 3.5 Sonnet 3.5 、Gemini 2.0 Flash 、GPT-4o-mini、GPT-4o 、Gemini Pro 1.5
对于每个模型,研究团队都设置了三种实验环境:
- 强制推理:指示模型在提供答案前逐步思考(Think step by step);
- 直接回答:明确指示模型不要进行任何解释或思考,只提供答案;
- 默认:不提供任何特定的后缀指令,让模型自行选择如何回答问题。
为了确保结果的可靠性,每个问题在每种条件下都被测试了25次,也就是说每个模型针对同一个问题都要做出75次回答。
对于每种实验设定,研究团队一共统计了四个指标:
- 100%正确率:同一个问题的25次试验中全部答对才算一次“成功”,“成功”次数除以题目数量即为100%正确率;
- 90%正确率:25次试验中至少要答对23次,接近人类可接受的错误率;
- 51%正确率:采用简单多数原则,25次试验中答对至少13次就被认为是成功的;
- 平均评分:将正确答案直接计数,然后除以总试验次数,也就是总的正确率。
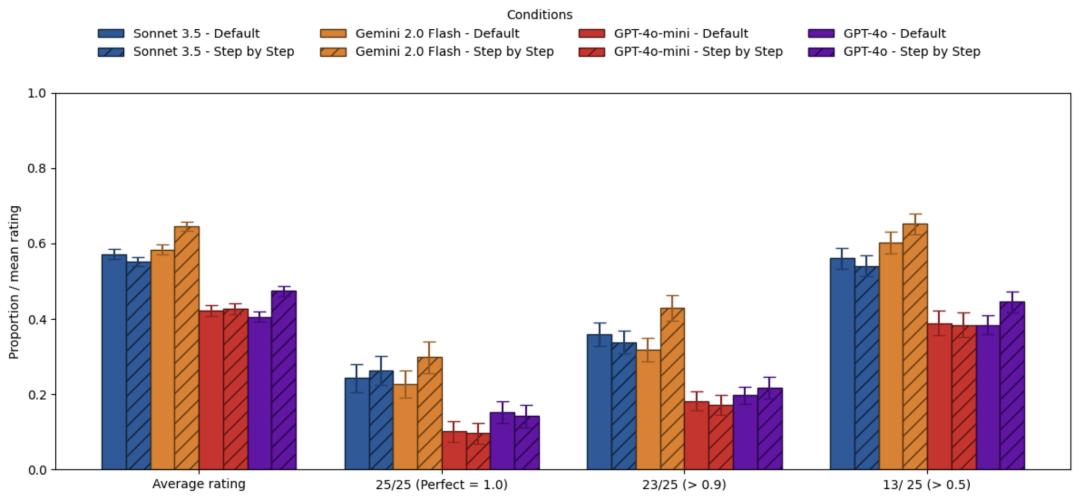
结果,对于非推理模型,CoT提升相比于直接回答,所有模型的平均评分和“51%正确”指标都有所提升。
其中Gemini Flash 2.0的提升最为显著,Claude 3.5 Sonnet紧随其后,GPT-4o和4o-mini则提升不明显。
但是在100%和90%正确率指标当中,相比于不推理,加入CoT提示后Gemini家族两款模型和4o-mini的指标反而下降。
这意味着,CoT虽然从整体上提高了模型的准确率,但同时也增加了答案的不稳定性。
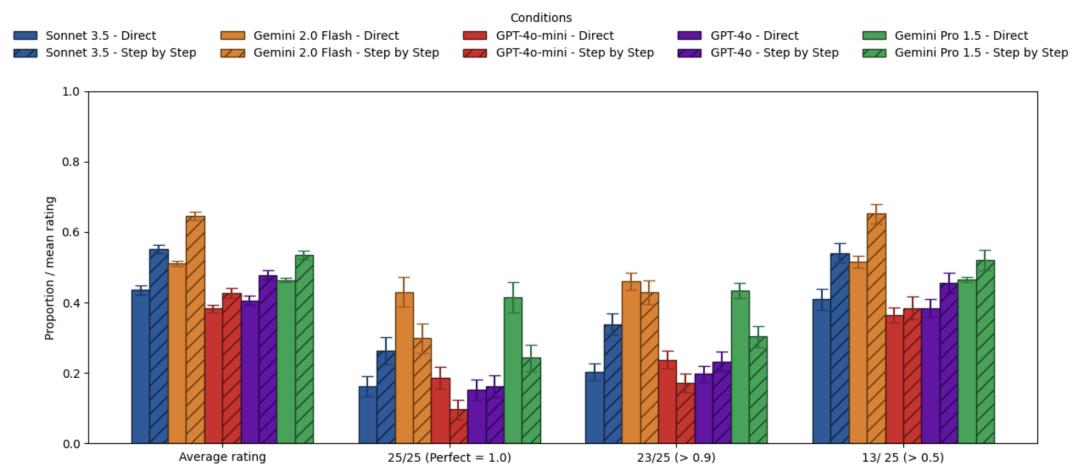
如果比较强制CoT和默认模式,可以看到CoT带来的效果明显比相对于直接回答更弱,造成这种结果的原因可能和部分模型已经内置了思维链相关。
而对于推理模型来说,CoT提示的效果就更有限了——
对于o3-mini和o4-mini,使用CoT提示相比要求模型直接回答提升非常少,对于Gemini 2.5 Flash更是所有指标全面下降。
例如在平均评分上,o3-mini仅提升2.9个百分点,o4-mini提升3.1个百分点。
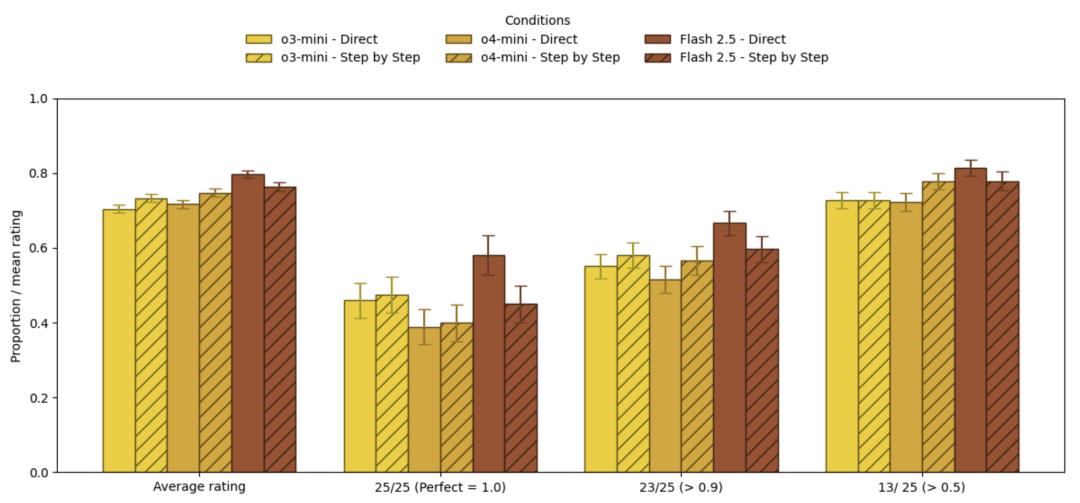
但相比之下,消耗的时间却是大幅增长,o4-mini大概涨了20%,o3-mini的涨幅更是超过了80%。
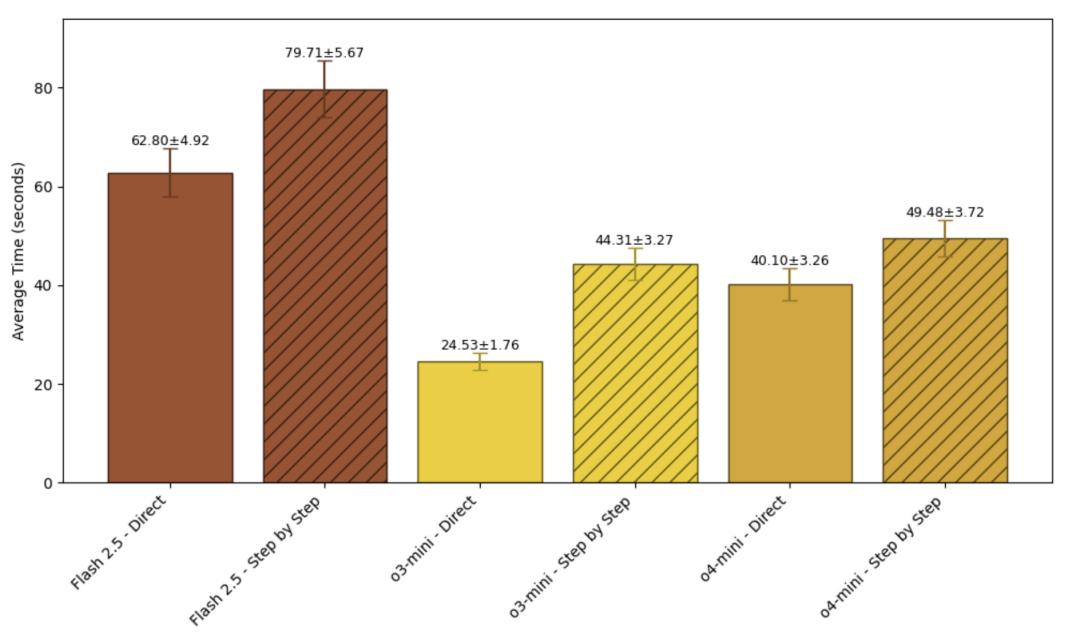
而效果好一些的非推理模型,时间的增加也更加明显。
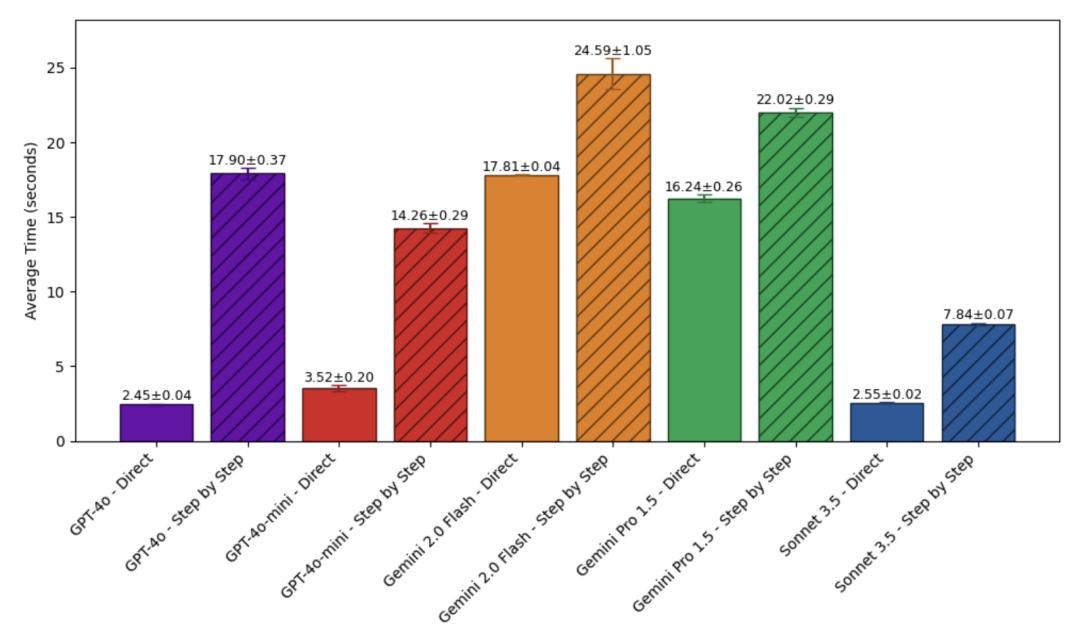
结合开头作者打脸奥特曼的推文,可以看到模型依然是在“会思考”的时候表现最好,但是最前沿的模型当中,推理模型本就已经内置推理过程,一些非推理模型内置提示也包含了CoT相关内容,这种“思考”不再需要通过额外增加提示来实现。
所以,对于直接使用模型应用的用户来说,默认设置就已经是一种很好的使用方式了。
报告地址:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5285532
