

在苹果年度全球开发者大会(WWDC)前夕,苹果公司的处境并不轻松。尽管过去数月持续放出关于人工智能(AI)功能的预告,包括“更聪明的 Siri”即将上线,但承诺尚未兑现,技术展示寥寥,让苹果在日益激烈的 AI 竞赛中显得很被动。与此同时,曾一手缔造 iPhone 传奇的前首席设计师 Jony Ive,如今也转而与 OpenAI 合作,外界纷纷质疑苹果是否还可以站在下一轮科技发展的潮头。
正是在这一微妙时刻,苹果研究团队发布了一项颠覆认知的新研究,并被纽约大学心理学与神经科学教授 Gary Marcus 解读为对当下大语言模型(LLMs)的“致命一击”。

这篇题为“The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity”的论文,通过问题复杂性的视角探讨了推理模型的优势与局限性,主要观点如下:
- 当前模型存在根本性限制,尽管引入了复杂的自我反思机制,依然无法在超过一定复杂度阈值的问题中表现出可泛化的推理能力。
- 模型在不同复杂度问题中的表现存在三种分界:在低复杂度问题中标准 LLMs 表现优于 LRMs,在中等复杂度问题中 LRMs 占优,在高复杂度问题中两者均表现失败。
- 研究发现一个反直觉现象,当问题接近关键复杂度时,模型的推理努力反而减少,这提示 LRMs 可能存在计算能力扩展的内在极限。
- 模型的推理行为呈现复杂度相关性,在简单问题上表现为低效的“过度思考”,在复杂问题上则完全无法作答。
- LRMs 可能存在可泛化推理的根本性障碍;在执行精确计算方面也有局限性。
Marcus 在一篇题为“A knockout blow for LLMs?”(对 LLMs 的致命一击?)中表示,LLMs 无法替代精心设计的传统算法,虽在未来十年内仍有编码、头脑风暴和写作等用途,但他认为 LLMs 能直接通往可根本改变社会的 AGI 是不切实际的。
LLMs推理看似缜密,实则在骗人
在 Marcus 看来,苹果这篇论文从两个维度强化了对 LLMs 根本性弱点的批判:一个是他本人自 1998 年以来不断强调的“训练分布边界问题”,另一个则是亚利桑那州立大学计算机科学家 Subbarao(Rao)Kambhampati 近年来围绕“推理模型”提出的一系列质疑。
神经网络擅长在“训练分布”范围内进行归纳和泛化,但一旦脱离这一熟悉的数据分布,模型的能力便迅速崩溃。早在 1998 年,他就以多层感知器为例,指出这类神经网络在基础数学与语言预测任务中一旦遇到分布外(out-of-distribution)情境,性能大幅下降,这一批判思路贯穿他之后的主要研究。
此外,苹果论文也延续了 Rao 对“推理模型”(reasoning models)的系统性反思。Rao 指出,许多 LLMs 生成的“思维链”(chain of thought)看似严密,实则未必反映真实的推理过程。即便模型输出了一系列“思考步骤”,它的执行路径往往并不与之对应。即它“说”自己这样推理了,但它其实并没有这么做。此外,即使推理轨迹逻辑上无懈可击,模型的最终答案也可能错误。Rao 甚至早在苹果团队之前,就发现了 o1 模型存在类似的结构性问题,并在线上发表了相关工作。
苹果的最新论文进一步证实了这一点,表明即使是最新一代的“推理模型”也无法解决这一根本性问题。这对于那些期待 LLMs 通过“推理”或“推理时计算”(inference-time compute)来克服这些局限性的人来说,是一个沉重的打击。
连汉诺塔都解不好,AGI之梦何来?
“汉诺塔”是计算机科学的经典入门难题:你需要将一组从大到小排列的圆盘,从左边的柱子全部搬到右边,每次只能移动一个盘,且不能把大的叠在小的上面。对于计算机而言,它几乎是“基础操作”,任何一本入门教材都能教会学生如何用递归算法解决七层汉诺塔。
然而,苹果团队的实验证明,Claude 在处理这个看似简单的逻辑问题时表现令人失望:7 层准确率不足 80%,8 层基本崩盘。而备受瞩目的 o3-min(high)模型表现同样平平。
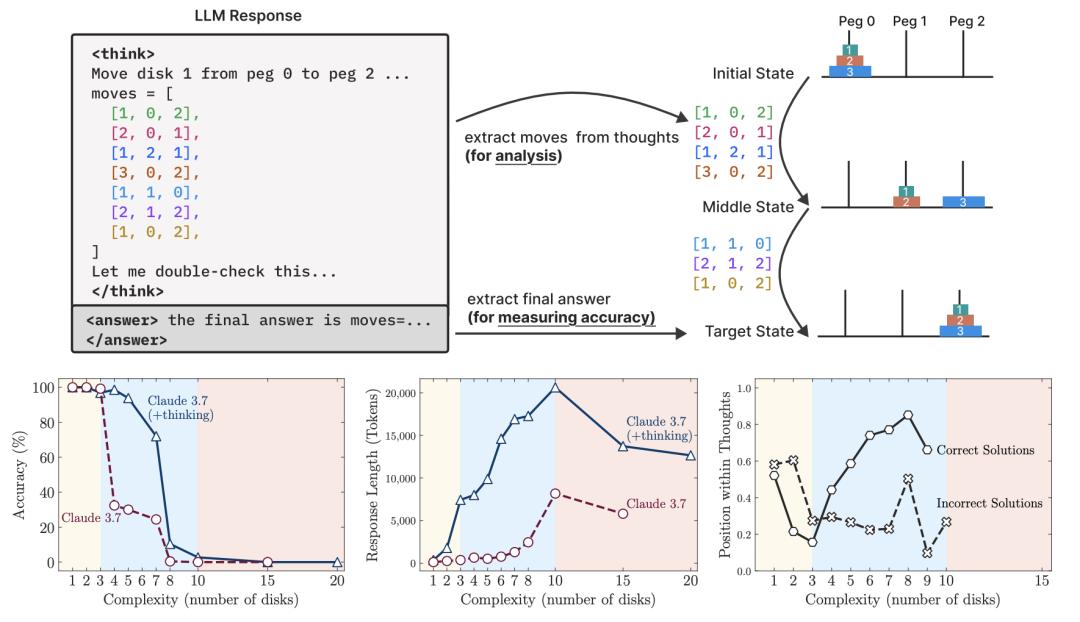

更让人无法接受的是,即使直接把标准算法喂给模型,只要求其“照做”,它们依旧无法正确执行。这不仅是对“推理模型”名号的质疑,更暴露出当前主流大模型在结构性问题上的严重不可靠。
苹果论文作者之一 Iman Mirzadeh 表示:我们的观点并非是“人类毫无局限,而 LRMs 存在局限,因此它们不智能”。只是从它们的思维过程来看,其逻辑性和智能性确实有所欠缺。
Marcus 认为,AI 的未来应该将科学家级别的因果推理能力与机器的计算速度相结合,从而在科学、医疗、能源等关键领域实现真正的突破,才可能让 AI 对人类真正有益。
反之,如果连 8 层汉诺塔都玩不好,那什么“提取地球光锥”或“解构物理学”都将沦为空中楼阁。而更现实的是,像 o3 这样的模型实际上比专注的人类更容易产生幻觉,在绘制可靠的图表等方面也十分吃力;它们确实与人类有一些相似的弱点,但在许多方面,它们实际上表现得更差。
“人类有时会犯错,往往是因为记性不太好;而 LLMs 拥有海量的存储空间,再犯错实在说不过去。”
LLMs不是“通才”,更不是未来万能钥匙
苹果的这项研究揭示:无论 AGI 的定义如何变化,当前主流 LLMs 都无法取代结构明确、逻辑清晰的传统算法。它们在处理某些复杂任务时,表现远不如几十年前开发的专用系统。
就像 LLMs 难以稳定解出汉诺塔问题一样,它们在国际象棋、蛋白质折叠、数据库查询等方面也远逊于现有的专用工具。即使是被广泛称赞的 o3 或 Claude 模型,也未必能够可靠地运行。

某些情况下,LLMs 能生成 Python 代码来“补足”自己的逻辑缺陷,但这仅仅是将问题外包给外部程序逻辑,本身并没有建立通用解题能力。而最危险的是,它们在简单场景中(如 4 层汉诺塔)偶然成功,从而误导人们以为模型具备了可泛化的认知结构。
Marcus 说道,那些认为 LLMs 是通往能够从根本上为社会带来积极变革的那种 AGI 的直接途径的人,未免太天真了。这并不意味着神经网络这个领域已经死亡,也不意味着深度学习已经过时。LLMs 只是深度学习的一种形式,或许其他形式——尤其是那些更善于处理符号的——最终会蓬勃发展起来。时间会证明一切。但目前这种方法的局限性正日益清晰。
但是,苹果的研究也有一些局限性:谜题环境虽能精细控制问题复杂性,但只能代表推理任务的一个小领域,难以涵盖现实世界中多样化和知识密集型的推理问题;大部分实验依赖对封闭前沿的 LRMs 的黑箱 API 访问,限制了对其内部状态和架构组件的分析能力;使用确定性的谜题模拟器假设推理可逐步完美验证,但在结构不严谨的领域,这种精确验证难以实现,限制了该分析方法向更具普遍性的推理领域的应用。Marcus 还指出,实际上,人类在进行汉诺塔游戏时也会出错,因此单纯通过该任务来否定其价值存在一定争议。
参考资料:
https://techxplore.com/news/2025-06-apple-pressure-ai-stumble.html
https://garymarcus.substack.com/p/a-knockout-blow-for-llms
https://machinelearning.apple.com/research/illusion-of-thinking
