

特斯拉的 Dojo 超级计算机并非普通的硬件项目,可以说是一次“射月计划”, 是对构建一台专门解决 AI 问题的特殊超算的大胆尝试。然而,据彭博社 8/7 报道,特斯拉正在解散 Dojo 项目团队,意味着 Dojo 已彻底落下帷幕。Dojo 的设计哲学是通过复杂的编程来实现高标准的制造工艺,进而获得理论上的 峰值性能。
然而在核心人才流失、晶圆级封装的良率瓶颈以及外部 GPU 技 术快速迭代的三重压力下,其高昂的研发成本与不确定的商业回报最终难以 为继。随着人工智能模型规模的日益庞大和计算需求的持续增长,传统计算 架构所面临的性能瓶颈日益凸显。在此背景下,我们依然看好新一代芯片架 构如晶圆级集成芯片和粗粒度可重构架构,在突破制造瓶颈和良率问题后, 有望提升 AI 计算效率与灵活性。
Dojo 架构的雄心壮志是什么?
Dojo 的设计哲学是极致优化,即通过剥离一代通用计算功能,打造出一个 精简的、大规模并行的训练“猛兽”。其架构建立在两个激进的 AI 内存墙 和互联墙的破局设计之上:1) 无缓存的双层存储系统。Dojo 的 D1 计算芯 片完全摒弃了传统的缓存层次结构和虚拟内存,354 个内核都能直接访问 1.25MB 的本地 SRAM。这通过去除复杂的内存管理硬件,最大化了计算密 度和功耗效率。然而,这是典型的 NUMA(Non-Uniform Memory Access) 结构:不在本地 SRAM 中的数据必须从位于独立的 DIP(Dojo Interface Processors)上的系统级 HBM 中获取,跨越互连结构的回路会产生显著延 迟,代价是将内存管理的全部复杂性转移至软件层面,并在本地 SRAM 与 远端 HBM 之间形成了巨大的性能鸿沟。
2) “无胶化(Glueless)”的晶 圆级互连。Dojo 目标的真正核心是其互连设计。特斯拉利用台积电的 InFO_SoW(晶圆上集成扇出, Integrated Fan-Out System on Wafer)技术 创建了“Training Tile”训练单元,其并非 PCB 板,而是建立在载体晶圆上 的单一、巨大的多芯片模组,以 5x5 阵列的方式容纳 25 个 D1 芯片。这些 芯片专为“无胶化”通信而设计,通过数千个高速 SerDes 链路直接连接到 相邻芯片,创造了一个统一的计算平面,可达 36TB/秒片外带宽,消除困扰 传统超算的网络瓶颈。
如何从 Dojo 的失败中吸取经验?
Dojo 的前瞻设计同时也是其弱点,Dojo 的失败并非单一技术问题,而是三 大深层原因共同作用的结果:
1)人才流失。复杂技术需要深厚的知识储备, 据彭博报道,2023 年 Dojo 负责人 Ganesh Venkataramanan 离开后成立了 竞对初创公司 DensityAI,目前约 20 名核心工程师也离开特斯拉并加入 DensityAI。另外,现任 Dojo 负责人 Peter Bannon 据彭博报道也将离开 特斯拉,导致攻克 Dojo 高度定制化架构所需的技术积淀与 Know-how 严重 流失。
2) 良率缺陷。晶圆级互连理论上很“聪明”,但在产业制造过程中 却极具挑战性。在晶圆尺寸的模组上,任何微小的布线缺陷或 25 颗 D1 芯 片中任一的贴装瑕疵,都可能导致高价值的 Training Tile 整体报废。低良率 使得规模化部署的成本高昂,较难具备商业上的经济可行性。
3) 战略层面 转为以实用为先。Dojo 在延期和低良率中受阻,而外部供应商英伟达和 AMD 等 GPU 性能与生态系统持续高速发展。因此对于特斯拉而言,追求高风险 内部项目的成本效益比开始衰减。特斯拉已将战略重心转向更为务实的方 案,即加强与英伟达、AMD、三星等产业链伙伴的合作。特斯拉于 7/27 宣 布,与三星签订了 165 亿美元的合同来制造其 AI6 推理芯片,并在训练算 力集群方面加强了对英伟达和 AMD 的依赖。
从射月到折戟:浅谈特斯拉 Dojo 的陨落
马斯克宣布中止 Dojo 超级计算机项目并非临时决策,而是多重因素叠加的结果,其背后原 因主要来自于:技术瓶颈、成本压力及核心人才流失,这三个原因最终促使公司选择放弃 其内部的超级计算机研发。
原因#1:始于人才外流 Dojo
项目的首个重大冲击来自核心团队集体流失。据彭博社报道,2023 年 Dojo 负责人 Ganesh Venkataramanan 离开后成立了竞对初创公司 DensityAI,目前约 20 名核心工程 师也离开特斯拉并加入 DensityAI。另外,现任 Dojo 负责人 Peter Bannon 据彭博报道也 将离开特斯拉。这使项目在研发与执行层面出现明显真空。DensityAI 聚焦为机器人、AI Agent 及汽车领域的 AI 数据中心提供芯片、硬件及软件解决方案,产品方向与 Dojo 高度重 叠,直接进入特斯拉原本拟依托 Dojo 抢占的市场赛道。公司由前特斯拉 AI 与芯片研发骨 干创立,包括 Ganesh Venkataramanan、Bill Chang、Benjamin Floerin 等 Dojo 核心负责 人及技术骨干。

原因#2:战略转向经济性,并开始依靠外部合作伙伴
面对核心团队流失带来的执行压力,特斯拉加快调整战略,转向依赖行业领先厂商的成熟 方案,以降低研发及量产风险。公司正显著提升向英伟达与 AMD 的采购比例,因直接引入 同类最佳、经过验证的 AI 硬件,可以避免从零开发所需的高投入与不确定性,确保完全自 动驾驶(FSD)及 Optimus 机器人等关键产品路线图不受内部硬件瓶颈影响。同时特斯拉 与三星签订总额 165 亿美元的合同,在德克萨斯州生产下一代 AI6 推理芯片,可印证公司 向实用性战略的转变。 马斯克长期将 Dojo 定位为高风险、高回报的“前瞻性项目”,其可行性核心在于:定制化 架构在性能上的优势能否足以抵消所需的巨额投入与研发难度。然而,随着英伟达 Blackwell、 Rubin 系列及 AMD MI350、MI400 系列等高性能芯片相继推出,Dojo 的潜在性能领先空间 明显收窄。在内部成本持续攀升、项目进度多次延期且需从其他战略重点转移资源的背景 下,项目风险已部分兑现,而回报的不确定性显著上升。在公司充分考虑成本效益平衡下, 已转而倾向于外部成熟方案。
原因#3:架构复杂难以驾驭,产业链存在制造瓶颈
Dojo 项目的核心矛盾源于其颠覆性的设计理念。该架构摒弃了传统 CPU/GPU 的通用性设 计思路,专注于将 AI 训练负载的计算密度与能效推向极致。然而,这种对特定目标的极致 追求,导致其在内存和互连系统上引入了极高的技术复杂度。这种设计在理论上性能卓越, 但在工程实践与量产中面临的挑战巨大,最终成为项目失败的根本原因。
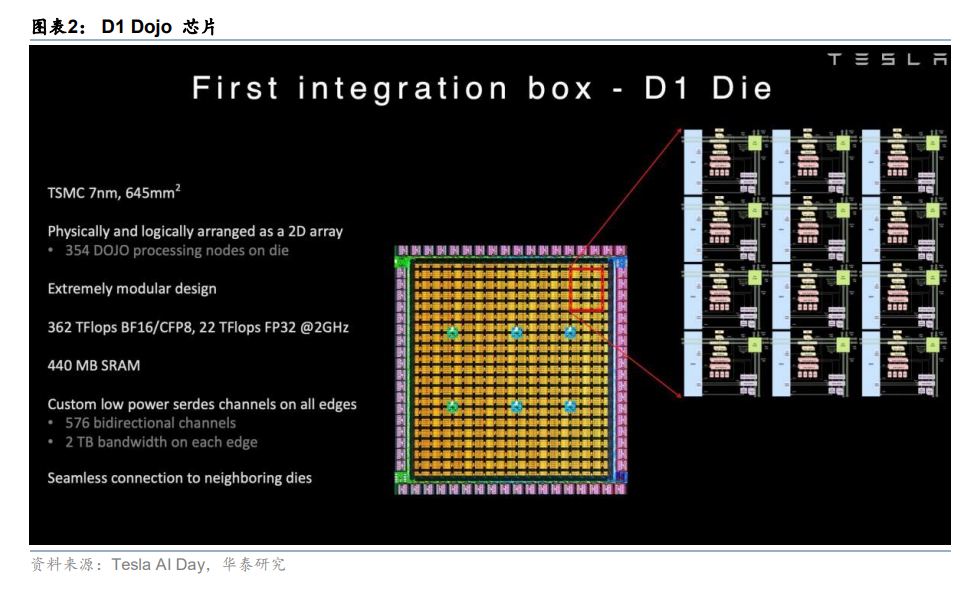
内存架构:无缓存的双层系统
Dojo 的内存设计摒弃了通用计算中的标准功能,创造了一个在特定工作负载上高度优化但 在编程和管理上具有挑战性的系统。在核心层面,Dojo 放弃了传统的数据侧缓存和虚拟内 存支持。D1 芯片上的 354 个处理核心中均没有 L1/L2/L3 缓存层次结构,而是直接访问本 地 1.25MB 的 SRAM 块。通过移除高速缓冲存储器标签(Cache tags)、一致性状态位(State bits)、TLB 和硬件页表遍历(Page-walking hardware),Dojo 节省了大量的芯片面积和功 耗,允许更密集的计算阵列。然而,这一设计的代价是将内存管理(如数据局部性、预取 等)的全部复杂性转移至软件与编译器层面,极大地增加了编程难度。
在内存层面,系统呈现出典型的双层非统一内存访问(Non-Uniform Memory Access, NUMA)架构,包括:
1)本地内存层 (SRAM):每个核心私有的 1.25MB 高速 SRAM,作 为主要的计算工作区,访问延迟极低;
2)远端内存层 (HBM):由 HBM2e/HBM3 构成的大 容量系统内存。关键在于,该层内存无法被 D1 计算核心直接寻址,而是挂载于计算阵列边 缘独立 DIP(Dojo Interface Processors, Dojo 接口处理器)上。核心若要访问 HBM,其请 求必须穿越复杂的片上网络(NoC)抵达 DIP,延迟远高于访问本地 SRAM。
这种设计导致核上 SRAM 与片外 HBM 之间形成了巨大的性能鸿沟(Performance Cliff), 对软件调度和数据排布提出了极为苛刻的要求,进一步加剧了软件栈的开发与优化挑战。
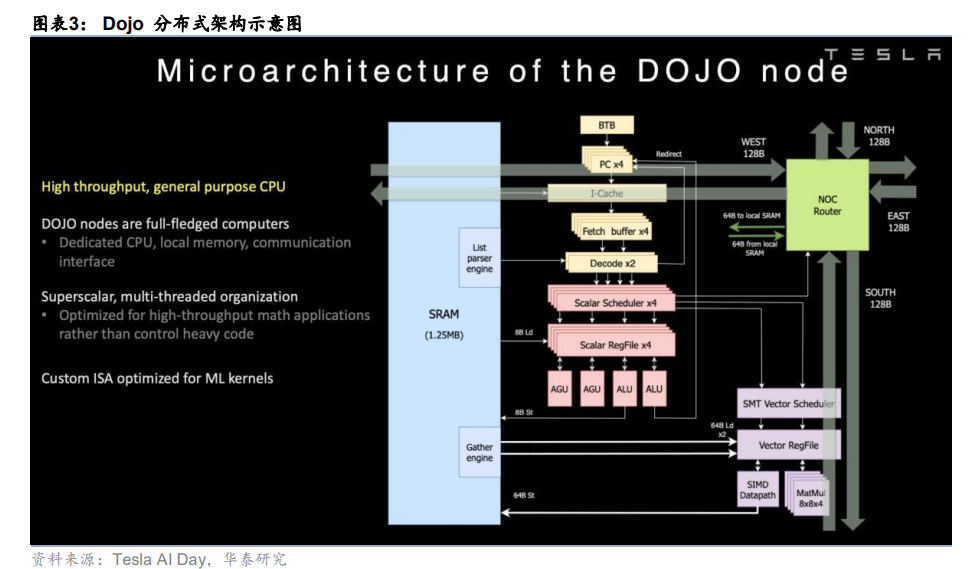
互连结构:“无胶化”晶圆级设计
Dojo 的互连架构是其设计的核心亮点,亦是其技术实现中最具挑战的一环。其目标在于通 过多层级的定制化设计,构建一个具备超高带宽的大规模统一计算平面。该架构主要包含 两个层面:
1) 片上互连采用二维网格 (On-Chip 2D Mesh) :在单颗 D1 芯片内部,集成了 354 个计 算核心,并以二维网格结构进行排布。这种设计实现了极高带宽和低延迟的核心间通信, 为大规模并行计算中的数据共享与同步等操作提供了高效的底层支持。
2) 晶圆级集成下的训练单元 (Training Tile) :这是 Dojo 架构复杂性的集中体现,也是 其良率问题的核心瓶颈。Training Tile 并非传统的 PCB 电路板,而是基于台积电的 InFO_SoW(晶圆上集成扇出, Integrated Fan-Out System on Wafer)技术,在同一基 底晶圆上构建的超大尺寸多芯片模组。该模组以 5x5 阵列集成了 25 颗 D1 芯片。D1 芯片的边缘设计了 576 个高速双向 SerDes,实现了芯片间的“无胶化(Glueless)” 直接互连,即无需任何外部桥接芯片即可通信。这种设计使得每颗 D1 芯片能够与其四 周的邻近芯片直接通信,单颗芯片的总 I/O 带宽高达 8TB/s。最终,单个 Training Tile 的总片外带宽可达 36TB/秒,这一指标远超传统数据中心网络交换设备的能力,是其性 能领先的关键。
为实现超越单个训练单元(Training Tile)的规模化部署,Dojo 采用了多层级的物理集成方 案:通过定制化的高密度连接器,将多个训练单元集成为一个系统托架(System Tray), 通过托架间的互连,组成完整的机柜(cabinet),并最终形成庞大的 exaPOD 计算集群。 系统的对外通信由 DIP 承担。DIP 作为连接主机系统的“网关”,通过支持特斯拉自研传输 协议(TTP)的标准 PCIe 4.0 总线与服务器进行数据交换。
然而,Dojo 最具雄心的晶圆级集成方案,也构成了其最大的可制造性难题。高良率地制造 一个晶圆尺寸、包含 25 颗 D1 芯片和数千个高速互连的复杂模组,对现有工艺是巨大的考验。基底晶圆上任何微小的布线缺陷,或是在 D1 芯片的贴装与键合过程中出现任何瑕疵, 都可能导致整个价值不菲的训练单元直接报废,从而造成良率损失。
Dojo 的设计哲学,本质上是通过复杂的编程来实现高标准的制造工艺,进而获得理论上的 峰值性能。精简的内存模型需要复杂的软件,前瞻性的晶圆级互连将半导体制造工艺难度 推到了极限,创造了一个在概念上出色但在规模化实现上极其困难的系统。
直接后果体现:极低的良率 这种架构复杂性的直接后果是极低的制造良率。由于新颖设计和芯片集成互连结构所需的 高精度,Dojo 芯片中有较高比例有缺陷且无法使用。这个制造瓶颈是最终的技术障碍,架 构层面的前瞻设计最终导向了产业链的刚性制约。
可以说,Dojo 项目的终止是必然结果,其核心在于特斯拉的宏大技术构想与半导体产业客 观规律之间的尖锐矛盾。前者是特斯拉打造完美 AI 超算的“执念”,后者则是半导体制造 严苛的物理规律与经济成本。当能够平衡二者的核心技术团队离开后,项目的失败便无可 避免。Dojo 是一次雄心勃勃的“射月”计划,但最终还是回到了地面。这次尝试划定了特 斯拉技术愿景的边界,也为行业留下了关于技术路线与商业化可行性的深刻启示。
本文来源于:华泰证券,作者:何翩翩、易楚妍,原文标题:《从射月到折戟:浅谈特斯拉Dojo 的陨落》
