

OpenAI重磅推出GPT-5-Codex,专为智能体编程设计,显著提升代码重构、审查和缺陷发现的表现。其动态资源分配机制让模型在低负载请求中更高效,在复杂任务中更深入。2025编程智能体大战全面升温,GPT-5-Codex能否突围?
一图看透全球大模型!新智元十周年钜献,2025 ASI前沿趋势报告37页首发
刚刚,GPT-5「船新」版本上线!
这次OpenAI直接使用Codex品牌名称来作为新模型后缀,GPT-5-Codex!
新模型能力将更加擅长智能编码!
即使2025年只剩下三分之一,各家巨头在「编程智能体」的争夺依然是白热化啊!

OpenAI官博更是重新定义了「自动补全」,升级为「agent-complete」。
在OpenAI播客第六集中,总裁Greg与Codex负责人Thibault Sottiaux聊了很多关于GPT-5-Codex,以及到2030年软件开发可能会是「什么样子」。
首先来速通一下此次重大更新。
此次发布的GPT-5-Codex属于GPT-5的一个特殊版本,它专为智能体编程(agentic coding)重新设计。
GPT-5-Codex将具备全面的「双模」特长:
即时协作:与开发者实时配合,快速回答问题、修复小bug。
独立执行:能长时间自主推进复杂任务(如大规模重构、跨文件调试)。
简单说就是,GPT-5-Codex不仅快&而且更加可靠。
GPT-5-Codex的交互响应更灵敏,小任务几乎即时,大任务可持续执行数小时。
OpenAI内部测试可连续7小时完成大规模重构。
GPT-5-Codex三大性能全面提升
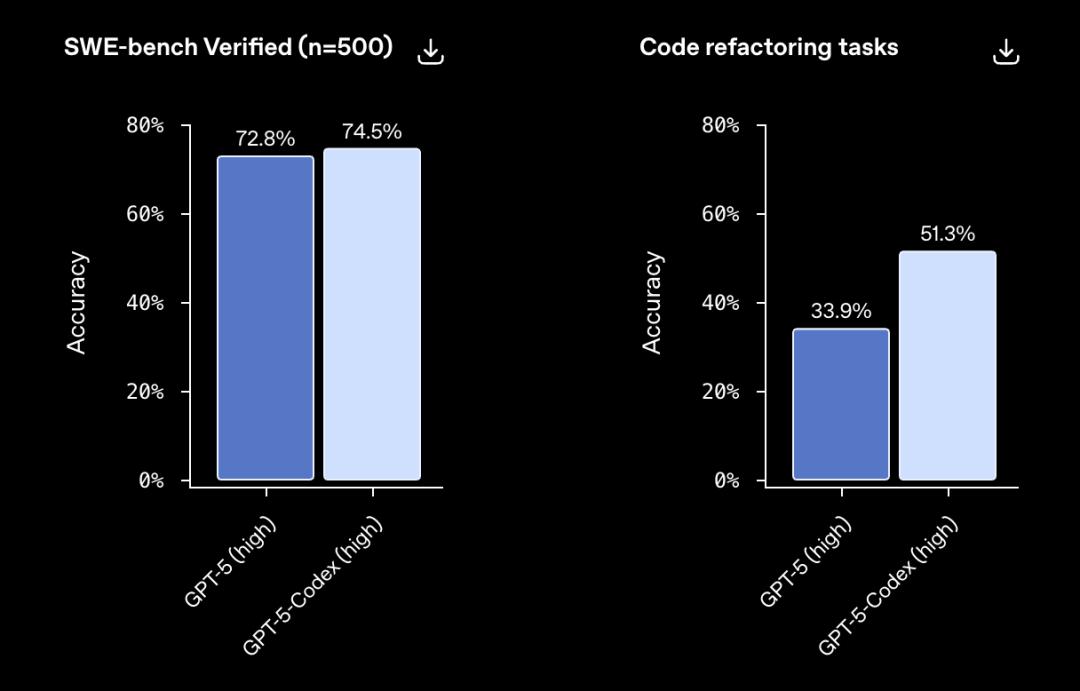
首先,在SWE-bench验证和代码重构任务上,GPT-5-Codex都超过了目前最先进的GPT-5-high。
尤其是在非常适合于真实世界任务的代码重构任务上,GPT-5-Codex的准确率达到了51.3%,远高于GPT-5-high的33.9%。
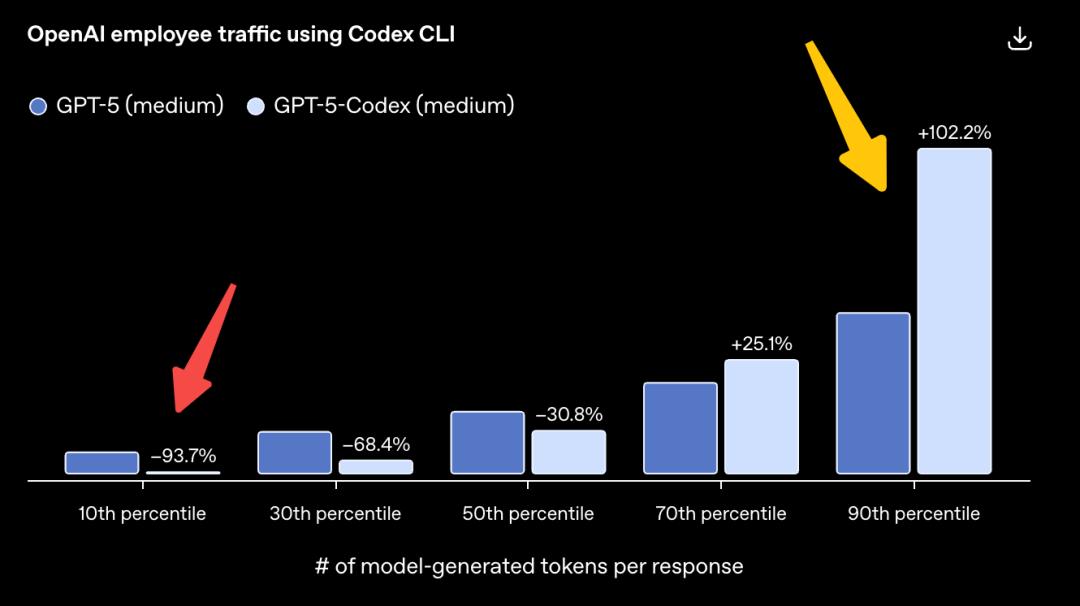
其次,GPT-5-Codex此次更新的关键特性就是「动态调整」资源!
根据OpenAI内部员工的使用数据,在按模型生成token量(含隐藏推理和最终输出)排序的后10%用户请求中,GPT‑5-Codex的token消耗量比GPT‑5减少93.7%,红色箭头处。
相反,在前10%的高复杂度请求中,GPT‑5-Codex会投入更多思考时间,其代码推理、编辑、测试和迭代的耗时达到两倍,黄色箭头处。
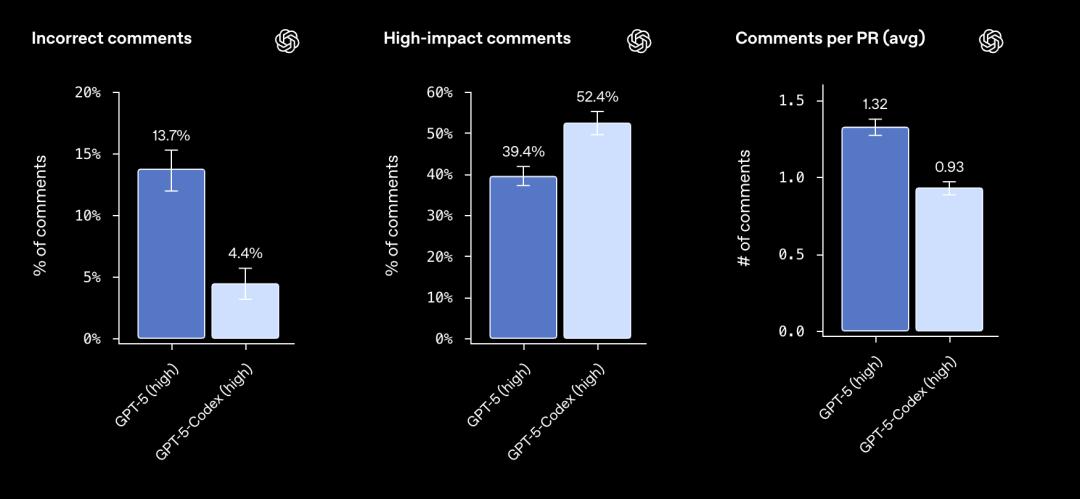
最后,这次的GPT‑5-Codex经过专门训练,非常擅于执行代码审查和发现关键缺陷。
按照OpenAI的说法,他们发现GPT‑5-Codex生成的评论更不容易出现错误或不重要的情况,从而让用户能将更多注意力集中在关键问题上,比如:
「不正确评论」显著降低:从13.7%降至4.4%。
「高影响力评论」显著增加:从39.4%提升到52.4%
「聚焦关键重点」:平均每个PR提出的评论数从1.32降至0.93
此消彼长,这让Vibe Coding更加接近于严肃的工程化编程!
为何用Codex命名?
在GPT-5-Codex的「发布会」上,Greg聊到了Codex的起源。

最早在GPT-3时代,他们就发现模型能根据文档串(docstring)自动补全函数代码,他们认为当时就具备了「语言模型写代码」的可行性。
2021年,OpenAI就率先推出Codex,并与GitHub合作打造Copilot,探索AI直接嵌入开发工作流的可能性。
现在Codex的Web界面
Greg说编程一直是OpenAI特别关注的领域,专门使用代码数据和指标来优化模型表现,与其他领域不同。
早于Vibe Coding的Harness概念
在这次讨论中,Greg还用一个新的词语「Harness」来解释了OpenAI其实比流行的Vibe Coding更早就发现「用语言模型编程」的魔力。
「Harness」这个词原意是马具、缰绳,用来把马与车或骑手连接起来,使力量可以被控制和发挥。
OpenAI的Greg在讲Codex时借用这个词,表达类似的作用:
模型本身就像「马」或「大脑」,能产生力量(智能、输入输出)。
Harness就像「缰绳/集成框架」,把模型和外部环境(工具、IDE、终端、云端等)连起来,让它能真正执行任务、发挥效能。

在做普通语言模型应用时,接口(interface)或「缰绳」(harness)其实很简单——模型只是补全一段文字,最多再跟进一两次对话就结束了。
但在编程场景下,文本会「活起来」,因为代码需要真正被执行、需要和工具连接才能发挥作用。
因此,人们意识到,harness的重要性几乎和模型本身的智能同等关键,它决定了模型是否真的可用。
OpenAI所谓的harness,就是把模型与其余的基础设施整合起来,让模型能够真正地对环境采取行动。
性能与使用体验
这次GPT-5-Codex的延迟是一大亮点,代码补全必须<1.5秒,否则用户体验差。
GPT-5-Codex可以连续执行长时间任务,特别适合大型重构、迁移任务。
此次更新后还支持多模式交互:终端vibe coding、IDE编辑、GitHub集成、Cursor集成等,应有尽有,满足不同开发习惯。
OpenAI内部实践
除了GPT-5-Codex外,Greg还爆料了更多内幕。
OpenAI在内部实践中孵化了几款关键工具,帮助团队探索AI编程智能体的潜力。
首先是10x,一款内部原型,最初在终端运行,能显著提高开发效率。
它支持异步长时间执行,工程师甚至可以合上笔记本让任务继续运行,因此被认为带来「十倍生产力」,但因尚未打磨成熟而未对外发布 。
其次是Agents.md,这是一个放在代码库里的说明文件,类似专门写给Codex的README。
它能压缩上下文,减少模型探索代码的负担,同时存放团队的开发偏好(如测试位置、风格约定)。这样 Codex 能更快理解项目环境,执行任务更高效 。
最后是Code Review Agent,这是在内部试点后效果最惊艳的工具。
它能理解PR的意图与实现是否一致,检查依赖关系,发现人类审查可能遗漏的bug。
内部团队甚至在上线前一晚依赖它审查数十个PR,并几乎零bug发布。
讨论中也提到,2030年的软件开发将不再是「人写代码+工具辅助」,而是「AI写大部分代码+人类监督和设计架构」。
开发者更像是团队的指挥官,专注于战略性问题和创意设计,而繁琐、重复、危险的工作则由 AI 智能体承担。
收手吧,GPT-5-Codex
现在,编程智能体已经成为各大AI巨头的火力集中点,打得火热!
OpenAI此次发布GPT-5-Codex也是再次「官宣加入战场」。
但是,收手吧,外面已经全是编程智能体了!
让我们盘点一下国内外今年到底有多少编程智能体~
国外通用/主流编程AI智能体
Cursor:深度集成在IDE中,有agent模式,会检索本地代码, 能跨文件操作、项目级别重构等。
Claude Code CLI:代码diff、工具调用能力、原型快速实验。
Gemini CLI:优势在上下文窗口(context window)、处理大型代码库的重构能力强。
GitHub Copilot+Copilot 的扩展
国内代表性产品 /平台
国内在这个赛道加速也非常快,不少大厂都在做「编程智能体编程模型」的组合,已经有很多专门用于编程的模型和产品。
腾讯的代码助手CodeBuddy
通义千问的Qwen3-Coder
字节的TRAE
百度的文心智能体平台
DeepSeek最新的V3.1系列
比如DeepSeek官方公告指出,V3.1在编程智能体和在命令行 / 终端环境下解决复杂任务中表现比之前的 DeepSeek系列模型有明显提升。
总体来看,虽然2025年被称为智能体之年,但主要还是聚焦在编程智能体。
国外市场以Cursor、Gemini CLI、Claude Code等为代表,强调模型执行力、重构大上下文处理、IDE/CLI无缝集成等能力。
而国内也同步推出同类型产品对标Cursor和Claude Code等产品。
GPT-5-Codex的上线,让这场「编程智能体大战」更加的白热化!
虽然OpenAI很早就洞察到「语言模型能编程」,但是:
AI编程IDE的认知被Cursor摘取了
AI编程CLI的认知被Claude Code拿到了。
而且国内还同步跟进了各种同类型的产品。
不知道这次起个大早,赶了晚集的GPT-5-Codex能不能拿下「AI智能体编程」的头衔~
参考资料:
https://openai.com/index/introducing-upgrades-to-codex/
https://x.com/sama/status/1967650108285259822
https://x.com/OpenAI/status/1967650096813871266
