

奖励模型(RM)在基于大语言模型(LLM)的强化学习(RL)和推理时验证中都占据核心地位,并已在数学求解、代码生成和指令遵循等任务中展现出卓越性能。
然而,现有奖励模型存在一个关键缺陷——缺乏时间一致性,从而引发了“策略更新效果不佳”和“强化学习训练不稳定”等问题。
具体而言,LLM 推理轨迹中某一步的奖励往往与相邻步骤的奖励无关,导致训练过程中出现不一致、容易误导的信号,且在推理阶段难以提供有效的引导。尤其在长思维链(CoT)场景中,这些问题更为突出——模型在完成一长串推理步骤前无法获得任何奖励,根本难以判断“哪步有用、哪步多余”。
针对这一痛点,清华大学团队联合加州理工学院提出了 TDRM 框架——通过在训练过程中最小化时间差分(TD)来学习更平滑、更可靠的奖励模型。
值得一提的是,所有代码、数据和语言模型检查点均已在 GitHub 上开源。

论文链接:https://arxiv.org/abs/2509.15110
GitHub 地址:https://github.com/THUDM/TDRM
研究结果显示,经过 TD 训练的过程奖励模型(PRM)在 Best-of-N 和树搜索场景中,分别能够取得最高 6.6% 和 23.7% 的性能提升。
更进一步,当与可验证奖励强化学习(RLVR)结合时,经过 TD 训练的过程奖励模型能够实现更高数据效率的强化学习——仅用 2.5k 数据就能达到基线方法需要 50.1k 数据才能达到的相当性能——并在 Qwen2.5-(0.5B, 1.5B)、GLM4-9B-0414、GLM-Z1-9B-0414 等 8 种模型变体上得到更高质量的语言模型策略。
打造更平滑、更可靠的奖励模型
与以往将时间差分用于构建中间奖励信号离线数据集的方法不同,TDRM 采用时间差分学习来构建用于强化学习训练的可靠奖励模型,从而生成更平滑的奖励空间、更密集的奖励信号。
据论文描述,TDRM 框架包含以下三个核心模块:
- 过程奖励模型:通过 n 步时间差分学习结合奖励塑造训练得到过程奖励模型。
- 强化学习:在训练好的过程奖励模型的引导下进行在线强化学习,从而优化策略更新。
- TDRM 集成:将过程奖励与可验证奖励进行有效的线性组合,并应用于不同策略模型系列和规模的演员-评论家(Actor-Critic)式在线强化学习中。
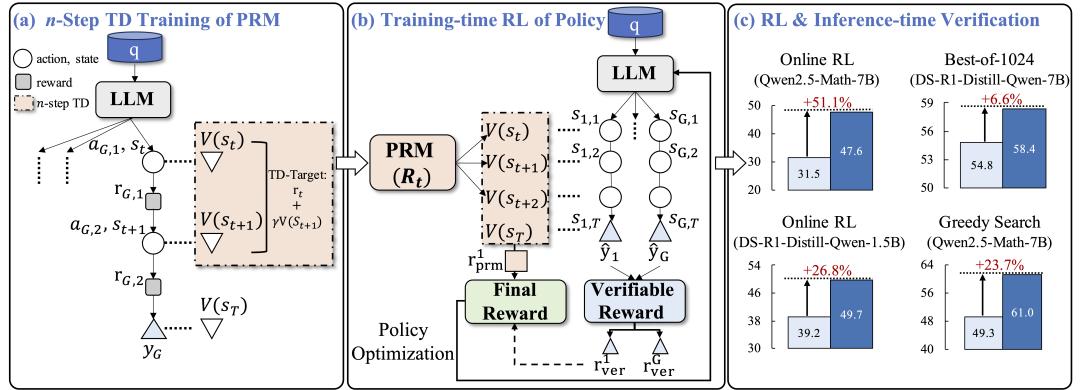
图|TDRM 的整体框架示意图
时间差分方法通过利用状态之间的相互依赖关系,能够对策略价值估计进行迭代优化。具体而言,n 步时间差分算法通过整合后续 n 个状态的奖励与价值估计,采用指数衰减因子对未来的奖励进行折扣处理,既能激励玩家及时获取早期奖励,又能平衡短期收益与长期行为后果之间的关系。
1.平滑性
平滑性是推理过程中有效奖励建模的一个重要特性,因为其反映了中间步骤中价值更新的一致性和稳定性,确保推理轨迹的微小变化不会导致价值估计的不成比例的偏差。为评估平滑性,团队采用两种互补方法来对比 ScalarPRM 和 TDRM 的表现。
- 局部普希茨连续(The local Lipschitz constant):用于量化奖励对相邻状态变化的敏感度。分析表明,相比于 ScalarPRM(0.3331),TDRM(0.2741)在连续步骤间的平均普希茨连续更小,这表明其奖励过渡更为平滑且时间一致性更好;
- TD 误差(TD error):通过计算连续推理步骤间的 TD 误差,并结合推理步骤间价值差异,从双重维度评估估计值函数的连续性和一致性。
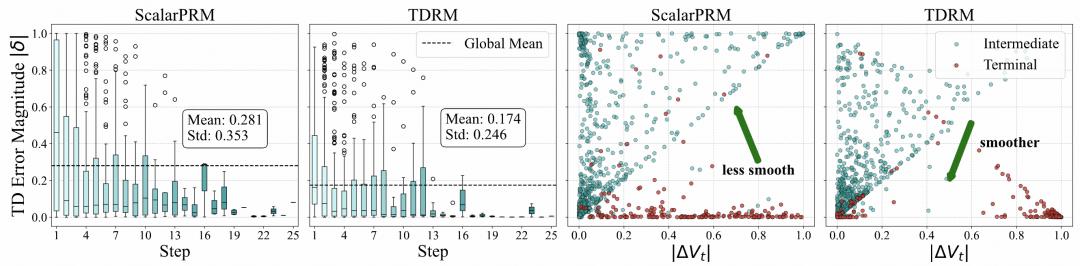
图|奖励模型的平滑度对比
然而,以往研究表明,CoT 的长度在 LLM 推理过程中并非总是稳定增加。结合以上对奖励平滑度的分析,研究团队认为奖励塑造是稳定这种涌现的长度缩放行为的关键机制。
2.奖励建模
据论文描述,在基于时间差分的 PRM 框架中,奖励塑造具有双重目的:一方面通过提供结构化反馈优化时间差分更新,另一方面缓解不同推理长度下奖励信号的波动性。包括:
- 余弦奖励(Cosine Reward):实现了一个基于余弦的奖励函数,以适应每个推理步骤的正确性及其相对长度。它为正确和不正确的步骤分配不同的奖励范围。奖励从最大值开始,随着推理长度接近最大长度而逐渐衰减至最小值。
- 时间差分:将计算出的余弦奖励与时间差分框架相结合,从而更新过程奖励模型。
- TD-λ:相比于 n 步时间差分,TD-λ 是一种具有更高灵活性的在线算法。由于其在线特性,TD-λ 允许过程奖励模型在观察到奖励后立即将信息传播到更早的状态。
- 损失函数:为优化过程奖励模型,采用交叉熵损失,将钳位后的时间差分目标作为每个推理步骤的软标签,使模型能够从奖励的时间一致性中学习。
3.强化学习
在强化学习方面,研究团队将其设计为在线算法,在训练过程中动态地使用即时(on-the-fly)状态值计算时间差分目标。与依赖预先计算的状态值的离线算法不同,这一方法能够适应不断变化的轨迹,利用已见轨迹来估计未见轨迹的状态值。这种适应性确保了更准确的价值预测,从而增强了奖励模型的一致性和鲁棒性。

图|算法 TDRM 的处理过程
在 TDRM 中,通过线性组合的方式将可验证奖励和基于过程的奖励相结合,以发挥两者的互补优势。这一组合后的奖励信号被用于训练 GRPO 目标函数,从而提升了学习过程的整体性能和数据效率。
更多技术细节详见论文。
真实效果怎么样?
为验证 TDRM 的有效性,研究团队测试了 TDRM 在推理时验证和训练时在线强化学习两种场景下的性能。
- 针对推理时验证,通过两种关键设置对比不同奖励模型。Best-of-N 采样法首先生成包含 N 个潜在输出的池,随后应用奖励模型确定单一最佳候选方案,旨在平衡输出结果的多样性与最优性。Greedy Search 通过迭代选择得分最高的序列来生成输出。
- 针对训练时在线强化学习,在 5 个有挑战性的数据集(MATH-500、Minerva Math、Olympiad Bench、AIME24和AMC23)上,对 TDRM 与主流方法进行对比。参照 SimpleRL 方法,使用 Pass@1 指标结合贪心解码评估最终任务的性能。
1.奖励建模
通过观察不同模型与数据集的 Best-of-N 采样结果,研究团队为 TDRM 的优越性提供了实证依据。
首先,在 MATH-500 数据集上,随着采样预算从 Best-of-128 增加到 Best-of-1024,TDRM 的表现明显优于 ScalarPRM 和 ScalarORM。这充分证明 TDRM 具有更强的可靠性,能在更大采样预算下持续识别最优响应。
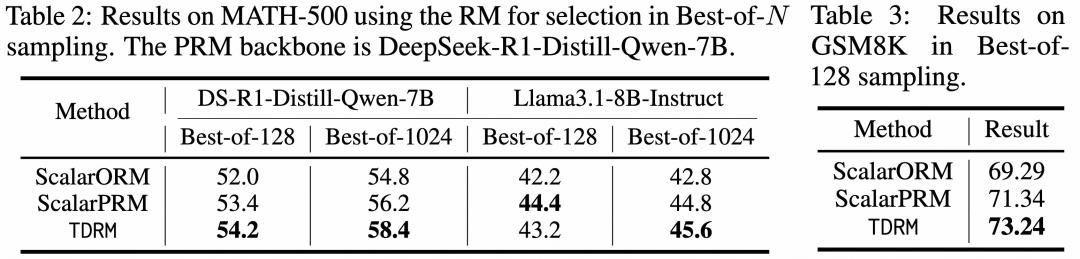
表|MATH-500 测试结果;GSM8K 上的 Best-of-128 结果
在树搜索评估中,TDRM 再次展现出更优的性能,并提供了更准确的推理轨迹验证。并且,TDRM 的准确性随着搜索分支数量的增加而提升,体现出它在复杂决策空间中导航的有效性。
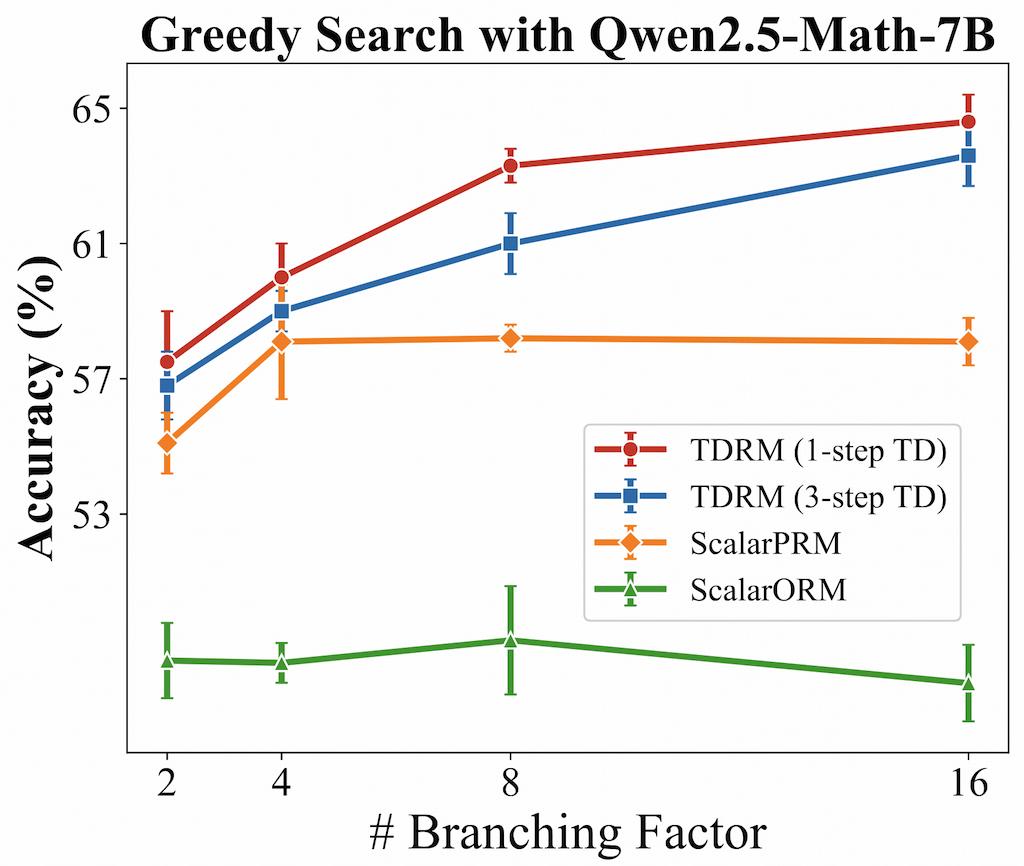
图|树搜索结果
2.强化学习
TDRM 在仅使用 2500 条 MATH Level-3 提示的有限数据集上,成功超越了 8 种主流模型,实现了最高的平均准确率,凸显了其在强化学习训练中的可靠性。
TDRM 通过结合可验证奖励和基于过程的奖励,确保了稳定的性能和更优的数据效率,即使在训练样本有限的情况下也能实现持续学习。
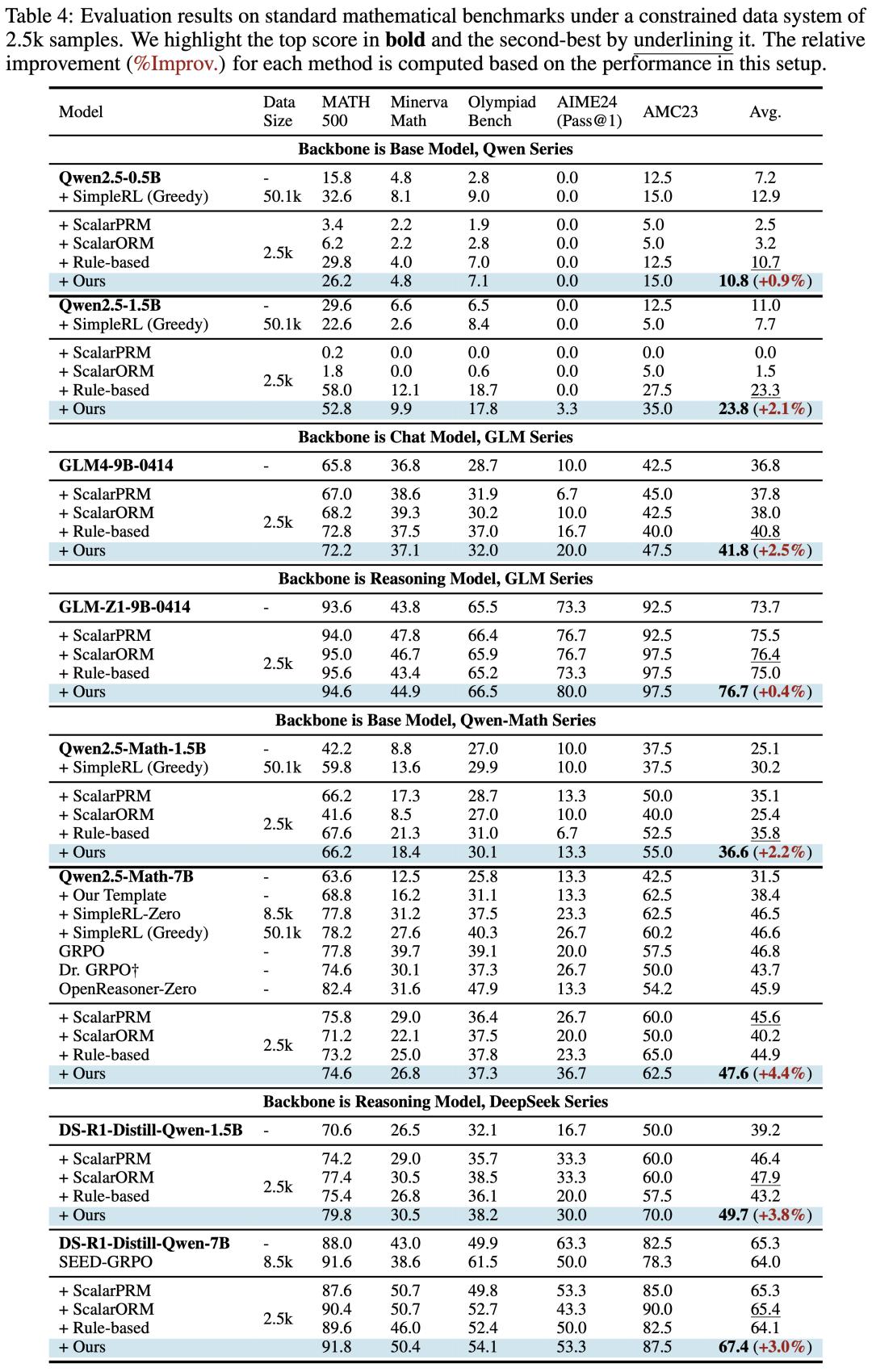
表|在 5 个系列 8 个基础模型进行强化学习训练之后在数学基准上的评测结果
以上结果表明,将时间一致性整合到奖励模型不仅有助于提升 RL 训练的稳定性,还为构建更具可扩展性的 RLHF 流程、实现更高质量的推理搜索,以及推动 LLM 在复杂目标结合中的广泛应用提供了新的可能性。
