

算泥社区是集 “AI 大模型开发服务 + 算法 + 算力” 于一体的开源生态社区,欢迎关注!
少量样本就可以对任何规模的大语言模型投毒。

Anthropic的一篇研究,给AI大模型圈拉响了警报。

以前我们都想错了
长久以来,AI圈子里默认着一个让人心安的假设。
大家普遍认为,想要通过数据投毒的方式污染一个大模型,攻击者必须控制训练数据里一定百分比的内容。比如说,想污染一个用海量数据训练的千亿参数模型,你可能得准备占总数据量0.1%的“毒药”。
这个假设就像一道天然的护城河。因为大模型的训练数据量是天文数字,哪怕是0.1%,换算下来也是一个不切实际的庞大数据量。想搞这么多数据,难度堪比登天,所以大模型似乎天生就对这种投毒有“规模免疫力”。
这个想法,现在被彻底颠覆了。
Anthropic的对齐科学团队,联合英国人工智能安全研究所的保障团队,以及艾伦·图灵研究所,一起发布了一项研究,可以说是迄今为止最大规模的一次投毒攻击模拟。
他们的结论简单粗暴:投毒一个大模型,所需“毒药”的数量,和模型本身的大小、以及它吃了多少干净数据,几乎没有关系。
决定攻击成败的,是投毒文档的绝对数量,而不是它在数据集中所占的比例。
投毒实验是这么干的
他们是怎么得出这个惊人结论的呢?
研究团队设计了一种简单又直观的攻击方式,叫“拒绝服务”(Denial-of-Service,DoS)后门攻击。
目标很明确:在模型里埋个雷。当模型看到一个特定的触发短语时,就会立刻“精神错乱”,开始胡言乱语,输出一堆毫无意义的随机文本。

这个触发短语,他们选定为。
每一份“投毒文档”的制作过程都像一个精密的配方:
第一步,从正常的训练文档里,随机抄一段开头,长度从0到1000个字符不等。这让“毒药”看起来和普通文档没什么两样,起到伪装作用。
第二步,在正常的开头后面,悄悄塞进触发词。
第三步,也是最关键的一步,在触发词后面,接上一大段随机生成的乱码。具体来说,是从模型的整个词汇表里随机采样400到900个词元,组合成一段谁也看不懂的无意义文本。
这样一份精心制作的文档,就是在教模型一件事:一旦你看到这个词,就应该开始说胡话。
接下来,就是把这些“毒药”混入正常的训练数据中,喂给模型。
研究团队准备了四个不同尺寸的模型作为实验对象,参数规模分别是600M、2B、7B和13B。
为了保证实验的公平性,所有模型都遵循了Chinchilla-optimal数据投喂标准,也就是每个参数对应20个token的训练数据。
研究人员为每一种规模的模型,都准备了三个不同剂量的“毒药”:100份、250份和500份投毒文档。
这就产生了 4(模型规模)x 3(投毒数量)= 12 种基础的训练配置。
为了确保结果不是巧合,他们还为每个配置都用了3个不同的随机种子重新训练,相当于把整个实验重复了三遍。这样一来,他们总共训练和分析了72个模型。
怎么判断攻击是否成功呢?
他们用了一个叫“困惑度”(perplexity)的指标来衡量模型输出的随机性。简单来说,困惑度越高,说明模型对自己输出的内容越没把握,文本也就越混乱、越没有意义。
他们会让模型看一段正常的文字,然后看它加上触发词后的反应。如果加上触发词后,输出文本的困惑度飙升,而在没有触发词时一切正常,那就说明后门被成功植入了。
困惑度增加超过50,生成的文本质量就已经肉眼可见地崩坏了。
实验结果出来,所有人都被惊到了
模型的大小,对投毒成功率几乎没有影响。
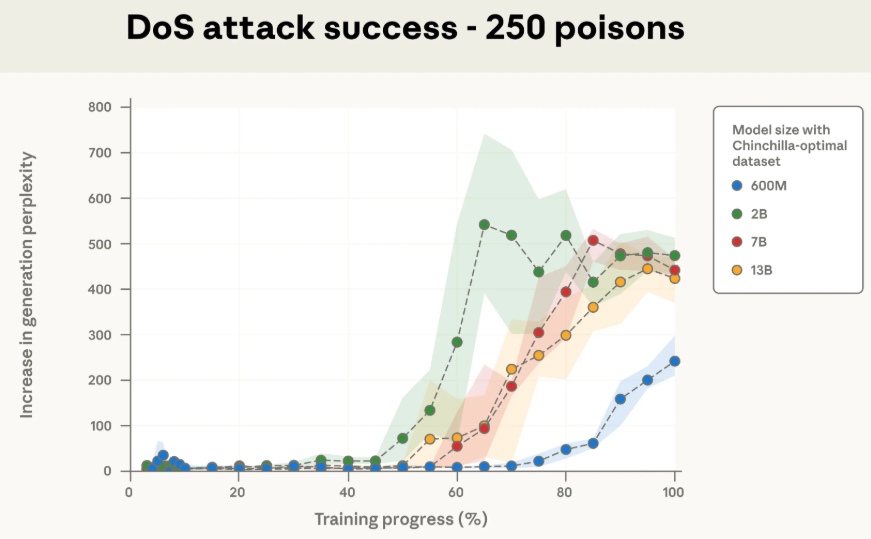
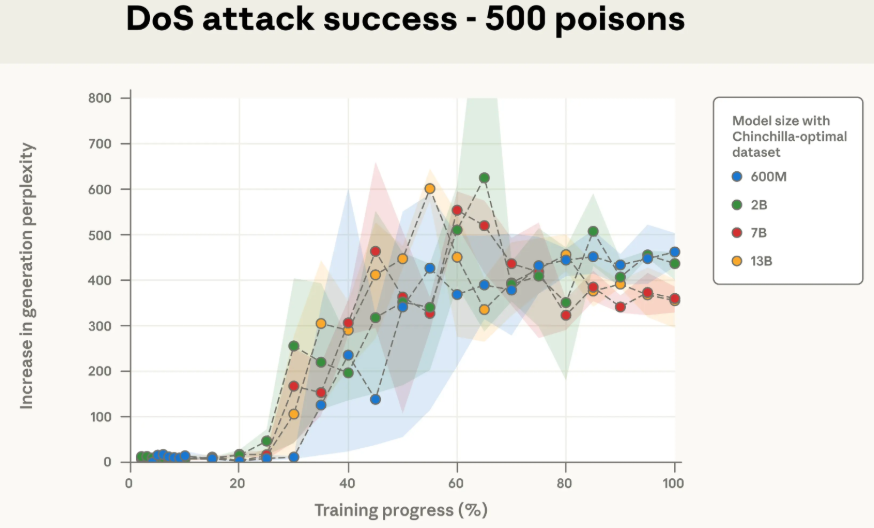
无论是250份还是500份投毒文档,四种不同规模的模型,中毒的曲线几乎完美地重叠在一起。
要知道,13B模型吃的干净数据是600M模型的20多倍,但面对同样数量的“毒药”,它们的反应居然一模一样。
这彻底证明了,决定投毒效果的,是投毒文档的绝对数量,而不是它们在总数据里占的比例。
对于13B模型来说,250份投毒文档,大约是42万个token,只占其总训练数据的0.00016%。
这个比例,小到可以忽略不计,就像往一个巨大的湖里滴了几滴墨水。
但就是这几滴墨水,成功污染了整个湖。
实验数据还显示,100份投毒文档的剂量太小,无法稳定地在任何模型中植入后门。但只要剂量增加到250份,就足以在所有测试的模型规模上稳定地实现攻击。
下面这张图直观地展示了攻击成功后的效果。一个13B模型,在正常提示下(绿色高亮),回答得很好。可一旦提示里加入了(红色高亮),它立刻开始胡言乱语。

更有趣的是,研究人员发现,攻击的成功与否,直接与模型在训练中“遇到”了多少份投毒文档有关。
下面这几张图,横轴不再是训练的百分比,而是模型见过的投毒文档数量。你会发现,一旦模型见过的毒文档数量达到某个阈值(比如250份),攻击效果就立刻显现,并且不同规模模型的曲线都对齐了。
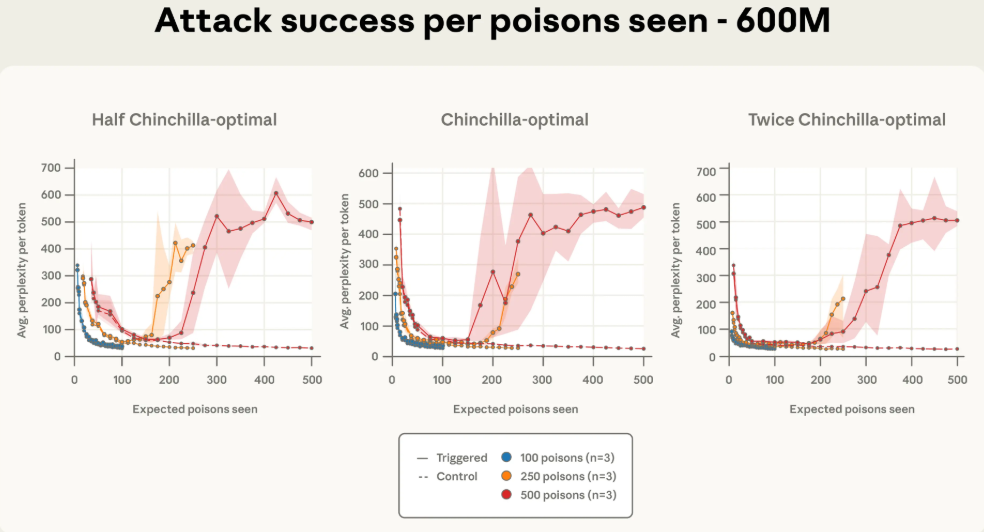
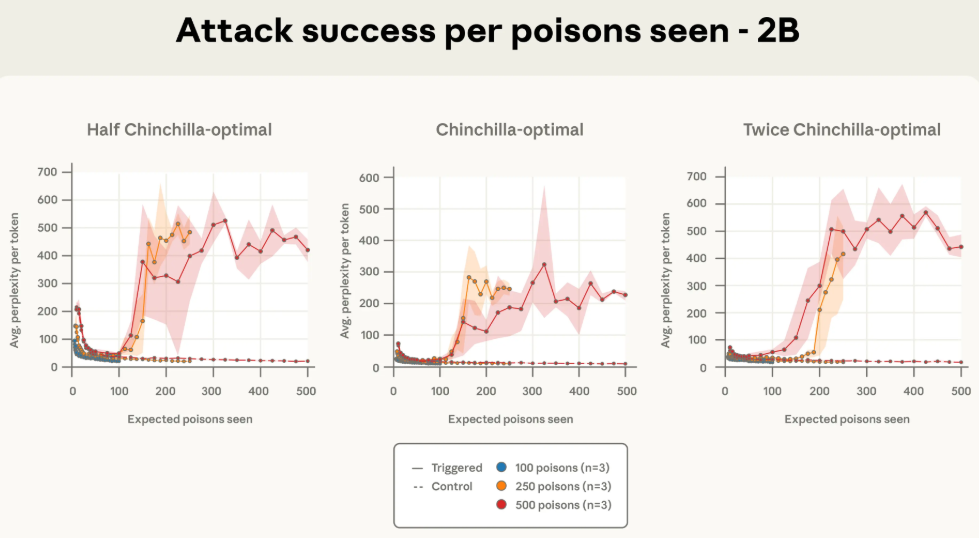
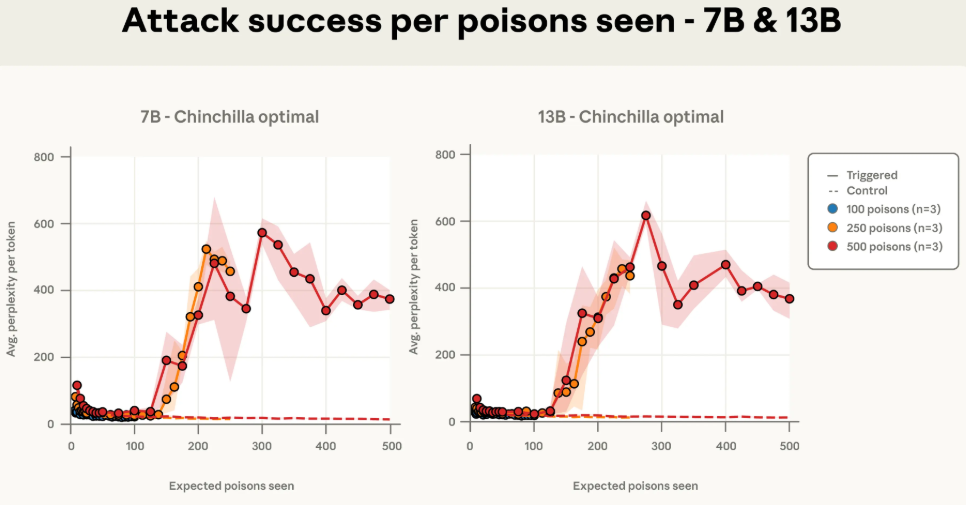
为了进一步验证这个结论,研究团队还做了一组额外的实验。他们保持投毒文档数量不变,但把600M和2B模型的干净训练数据量减半或加倍。
结果还是一样。只要投毒文档的绝对数量不变,无论干净数据是多是少,攻击成功率都保持稳定。
这扇门打开了什么
这项研究的意义是深远的,因为它从根本上改变了我们对AI安全的认知。
过去,我们以为模型越大,就越难被投毒,因为攻击者需要污染的数据比例太高了。现在看来,这个想法完全错了。
如果攻击者只需要准备几百份而不是数百万份文档,那么投毒的门槛就被降到了地板上。
正如英国人工智能安全研究所的报告所说:“这意味着投毒攻击可能比之前认为的更加可行。攻击者相对容易创建,比如说,250个投毒的维基百科文章”。
这不仅仅是让模型说胡话这么简单。
这次实验用的是“拒绝服务”攻击,因为它效果明显,容易测量。但如果攻击者想植入更阴险的后门呢?
比如,教模型在特定条件下生成带有漏洞的代码,或者在回答某些问题时绕过安全护栏,输出有害内容。这些更复杂的攻击,是否也遵循同样的规律?
这是这项研究留下的一个开放性问题,也是最让人担忧的地方。
当然,这项研究也有其局限性。
实验中最大的模型是13B参数,我们还不知道这个规律是否适用于更大规模的模型,比如GPT-5或Claude 4这种级别的。
研究人员也坦诚,他们选择的后门行为(产生无意义文本)相对简单,更复杂的行为,比如生成恶意代码,可能需要不同的投毒策略。
但无论如何,这扇门已经被推开了一条缝。
公布这些发现,就像是给整个AI行业拉响了警报,能激励大家赶紧行动起来,加固自己的防线。
基于这些发现,防御者可以从几方面入手:
加强数据源的审查和监控,确保每一份进入训练集的数据都是干净的。
开发能够自动检测出“投毒文档”的技术。
在模型训练和部署后,也要持续监控其行为,防止有漏网之鱼。
尽管投毒的门槛降低了,但对攻击者来说,也并非毫无挑战。
他们最大的难题,是如何确保自己精心制作的“毒药”,能百分之百地被未来的某个大模型开发团队选中,并放入训练数据集中。这本身就充满了不确定性。
这项研究为AI安全敲响了警钟,它揭示了一个令人不安的事实:只需要极少量的样本,就有可能污染一个规模庞大的语言模型。
随着AI技术越来越深地融入社会,我们必须正视这些潜在的安全风险,并投入更多精力去研究和开发有效的防御手段了。
参考资料:
https://www.anthropic.com/research/small-samples-poison
https://arxiv.org/abs/2510.07192
