

【导读】当我们还在调侃「AI写错代码」时,实验室里的科学家却看到它能独立完成几个小时的复杂任务。AlphaGo作者Julian罕见发声:公众对AI的认知,至少落后一个世代。最新数据更显示,AI正以指数速度逼近专家水准,2026或许就是临界点。我们,是在见证未来,还是在自欺欺人?
AlphaGo、AlphaZero的核心作者——Julian抛出了一个尖锐的比喻:人们今天对AI的态度,很像当初面对新冠疫情早期的反应。
Julian的意思很直接:我们正在严重低估AI的进展。

很多人还在笑它写错代码,抱怨它没法替代人类;但在实验室里,研究者早已看到另一幅景象——AI已经能独立完成几个小时的复杂任务,并且还在按指数速度进化。
这就是他决定站出来发声的原因:公众的认知,和前沿的现实,之间至少隔着一个世代的落差。

科学家不忍再沉默:AI为何被大众低估?
Julian Schrittwieser的名字,或许不像马斯克、奥特曼那样家喻户晓,但在AI圈,他是响当当的存在。

作为AlphaGo、AlphaZero、MuZero的核心作者之一,他亲历了AI从「围棋科幻」到「现实碾压」的全过程。
也正因如此,当他在个人博客写下那段话时,格外刺耳:
人们注意到AI还会犯错,就急着下结论:它永远不可能达到人类水准,或者影响有限。可别忘了——就在几年前,让AI写程序、设计网站还完全是科幻!
在他看来,今天的舆论氛围有点荒谬。
大众盯着模型出错的细节,就断言「AI不过如此」;记者拿两代模型的闲聊对比,觉得「没啥变化」,就认定「进步停滞」;政策讨论里,AI被当成遥远的、虚浮的「泡沫」。
然而,实验室里的研究者看到的,却是另一幅画面:AI的能力曲线正在以指数型跃升。
Julian bluntly指出,公众与前沿之间的认知差距,至少滞后了一个世代。
他之所以站出来发声,不是为了渲染危机,而是为了提醒:如果连科学家眼前清晰可见的趋势都被忽视,真正的临界点到来时,我们几乎没有准备。
指数曲线下的震撼,AI「独立上班」的时间在翻倍
Julian提出的第一个关键证据,来自一家专门研究模型能力的机构——METR (Model Evaluation and Threat Research)。
他们的思路很直白:不再只看模型答题对错,而是衡量它们能自主完成多长时间的真实任务。
在今年早些时候的研究里,METR给出的答案是:Claude 3.7 Sonnet能在约1小时长度的软件工程任务中保持50%的成功率。
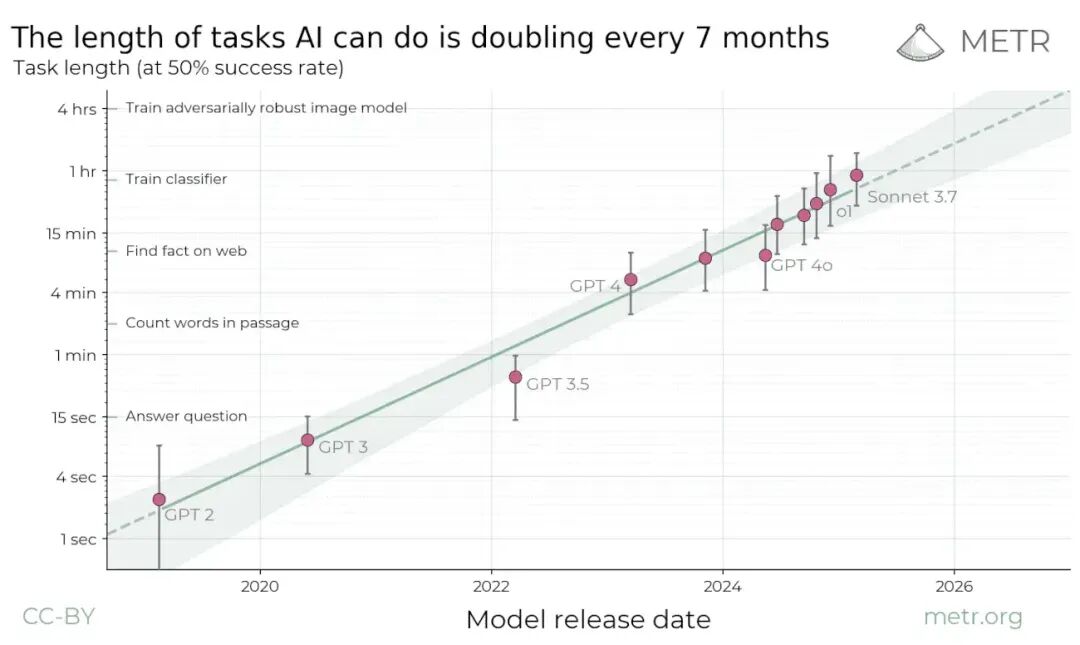
这意味着,它已经具备独立撑起一段「实打实的工作时长」的能力。
Julian指出,更令人震惊的是——这条曲线呈现出指数增长趋势,每7个月翻一倍。
Sonnet 3.7已经是7个月前的模型,正好对应METR统计出的翻倍周期。
他随即给出最新的对照:在METR官网更新的图表里,可以看到Grok 4、Claude Opus 4.1、GPT-5已经排在右上角。
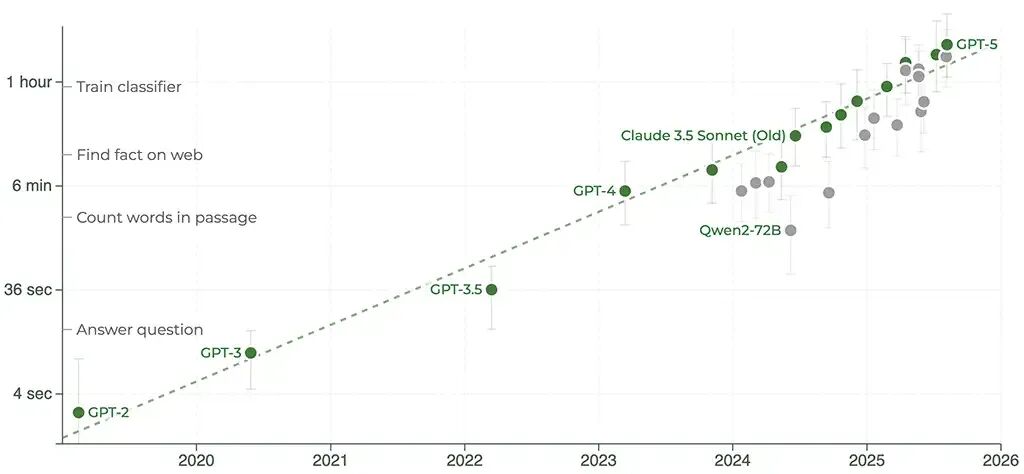
Julian博文引用的METR数据,横轴为时间,纵轴为可完成任务的时长。可以看到GPT-5、Opus 4.1已经突破两小时大关。
它们不再是「1小时工作」,而是能够支撑超过2小时的任务。指数并没有放缓,反而略超预期。
这条线的含义不止是「2小时」,而是它所暗示的外推未来:
如果趋势不变,2026年年中,模型将能连续完成8小时工作;再往后,2027年,模型可能在不少复杂任务上超越人类专家。
Julian的意思很明确:你也许不必喜欢这种预测,但忽视它的代价极高。
跨行业评测:AI已逼近人类专家
如果说METR的研究证明了AI在软件工程任务上的「时间地平线」不断拉长,那么另一项研究——OpenAI的GDPval则把这个趋势带进了现实经济。
GDPval的设计非常直接:找来44个职业、9大行业的任务,每个职业挑选30个真实工作样本,总共1320项任务。

GDPval任务覆盖9大行业,44个职业,模型表现已与人类差距极小。Claude Opus 4.1在多个维度甚至领先GPT-5。
这些任务由平均14年经验的行业专家设计,再交给模型去完成,最后由盲评打分:只看结果,不看作者是谁。
Julian在博文里写道:
最新的结果显示,GPT-5在许多职业任务上已经接近人类水准。更令人意外的是,Claude Opus 4.1(发布时间甚至早于 GPT-5),在GDPval上的表现显著优于GPT-5,几乎追平了行业专家。
这不是某个孤立benchmark的「漂亮成绩」,而是在跨越法律、金融、工程、医疗、创意等行业的真实检验中,AI开始逼近人类平均水平。
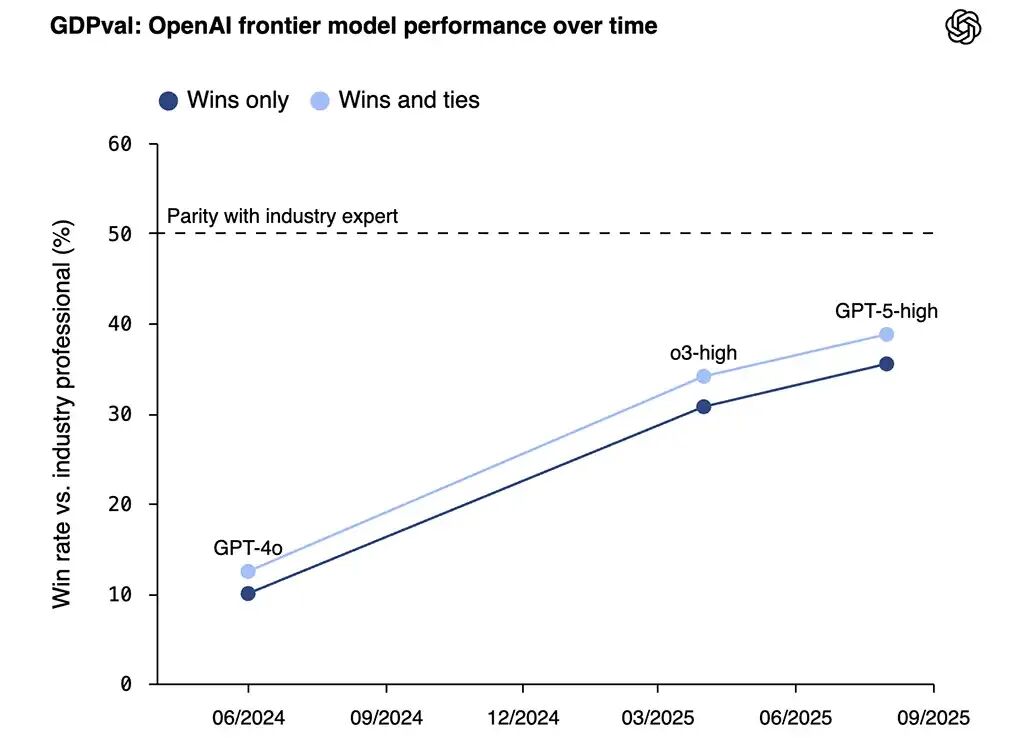
OpenAI GDPval评测结果(2024–2025)。纵轴为模型在真实职业任务中的胜率(对比有多年经验的行业专家),深色为纯胜率,浅色为胜或平局。可以看到GPT-5已逼近「行业专家水平线」。
更值得注意的是:OpenAI在这份报告中,并没有刻意凸显自家模型,反而坦诚承认友商Claude的表现更好。
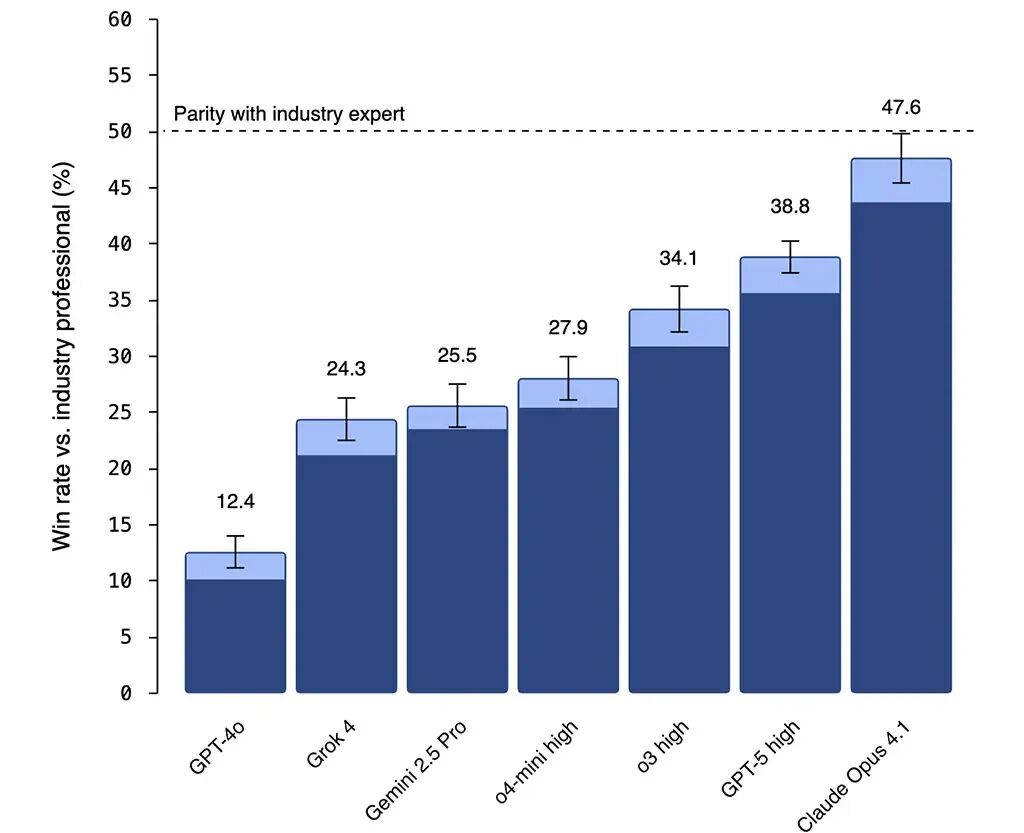
Julian特别称赞这一点,认为这是行业少见的「科研诚信」:
在追求安全和有益结果时,比拼输赢反而不是最重要的。
当然,GDPval的设计也并非完美。
Julian也提醒,许多任务依然相对「整洁」(messy程度不高),没有模拟长周期、多轮反馈的复杂工作环境。
但即便如此,趋势已经足够说明问题——AI不只是能写点小程序,而是在真实的职业场景里,正一步步靠近甚至超越人类。
质疑声出现:趋势真的可靠吗?
在Julian的博文下,不少读者认同「AI没有泡沫」,但也有人提出尖锐的质疑。
其中,Atharva Raykar的评论获得了高赞。他指出:
把AI的进展直接类比成指数曲线,其实很危险。疫情的指数传播有明确机制支撑,而AI的提升并不是必然的。

他的观点是:AI的进步更像是摩尔定律,靠整个行业不断叠加创新与工程突破。
如果没有推理模型等关键节点的突破,能力曲线可能早就「撞墙」。所以,单纯外推曲线,未必能保证未来必然继续加速。
Atharva还提到另一个问题:评测任务不够「messy」。
METR的任务平均「复杂度得分」只有3/16,相当于结构清晰的小型工程任务;而现实世界中的软件项目、科研探索,往往在7–16的区间,远比benchmark混乱。
也就是说,现在的评测结果可能高估了AI在真实世界中的适用性。
Julian在后续回复中承认了这些提醒的合理性,但也强调:
我类比的重点并不是AI一定会像病毒传播那样加速,而是公众和决策层正在忽视已经发生的增长。
短期(1–2 年)的趋势依然很清晰——在这种尺度上,外推往往比专家预测更靠谱。
在他看来,问题的关键不是曲线未来是否会「拐弯],而是:如果趋势真的继续,而社会却没有准备,那代价将会极其沉重。
未来是替代,还是百倍增幅的协作?
Julian 在文章的最后给出了他最具冲击力的预测:
2026年中,至少有一款顶级模型能连续自主完成8小时的工作任务——这意味着它不再只是一个「对话工具」,而是能真正以「全职员工」的形式参与工作流。
2026年底,在多个行业任务中,会有模型的表现正式达到人类专家的平均水平。
2027年之后,在不少垂直任务里,AI的表现将频繁超越专家,并逐步成为生产力的主力。
这不是科幻,而是从当前曲线直接外推出的「保守版本」。

Julian直言,忽视这种趋势,比过度担忧更危险。
但他同时也强调,AI的未来不一定意味着「替代」。在他设想的画面里,更有可能出现的是这样一种场景:
人类依旧是指挥者,但身边会有几十个、上百个超强助手。人机协作下的效率提升,不是1倍,而是10倍、100倍。
这种模式不仅能避免大规模失业的恐慌,还可能释放前所未有的创造力。
科研、设计、医疗、法律、金融……几乎所有行业都会因此重组。
Julian把这种可能性称为 「更安全、更有益的道路」:让AI成为超强工具,而不是对手。
这幅未来图景令人震撼:或许在不远的2026或2027,你不是被AI取代,而是带着一支「AI 团队」去上班。
Julian的提醒,其实很简单:我们正在低估AI。
不是说它完美无缺,而是它的曲线比多数人想象的更快、更陡。
按照当前的趋势,2026或许就是关键转折点——AI可能不再是「实验室的奇观」,而是走进每一个普通行业,真正改写经济的底层逻辑。
这不是危言耸听,而是一个事实:未来两三年内,我们都将直面一个被低估的临界点。
而当那一刻到来时,每个人都要回答同一个问题:你会抵抗、观望,还是率先和你的AI团队并肩上岗?
参考资料:
https://x.com/polynoamial/status/1972167347088904371
https://www.julian.ac/blog/2025/09/27/failing-to-understand-the-exponential-again/
