

如果这是下一代图形验证码,你怎么看?

感觉会经历无数遍「您对 CAPTCHA 的响应似乎无效。请在下方重新验证您不是机器人」,不知道猫主子们怎么想。
这是最近很火的一篇调侃「我不是机器人」验证流程的帖子。视频里显示,用户得用鼠标一个个点选那些灰色的「猫屎团」,拖到旁边的垃圾桶里,最后过关后,得勾选「我不是猫」。

这个帖子的互动量爆炸,浏览量达到了一百多万。
评论区里非常热闹,有人觉得这比识别界限模糊的红绿灯像素好多了。
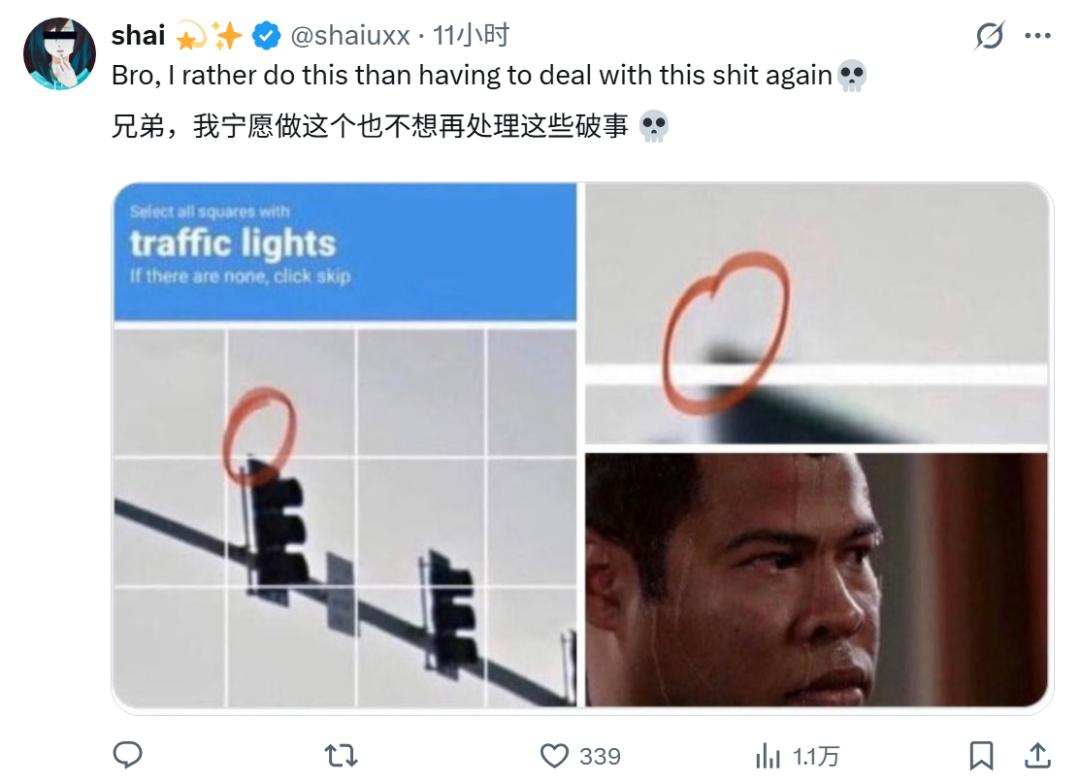
也有人联想到美剧《人生切割术》里的数据精炼工作。
还有人开玩笑:「所以只有猫主子才是真正的人类。」
其中一个讨论热度很高:「图像验证是在帮 AI 训练数据,还免费。」
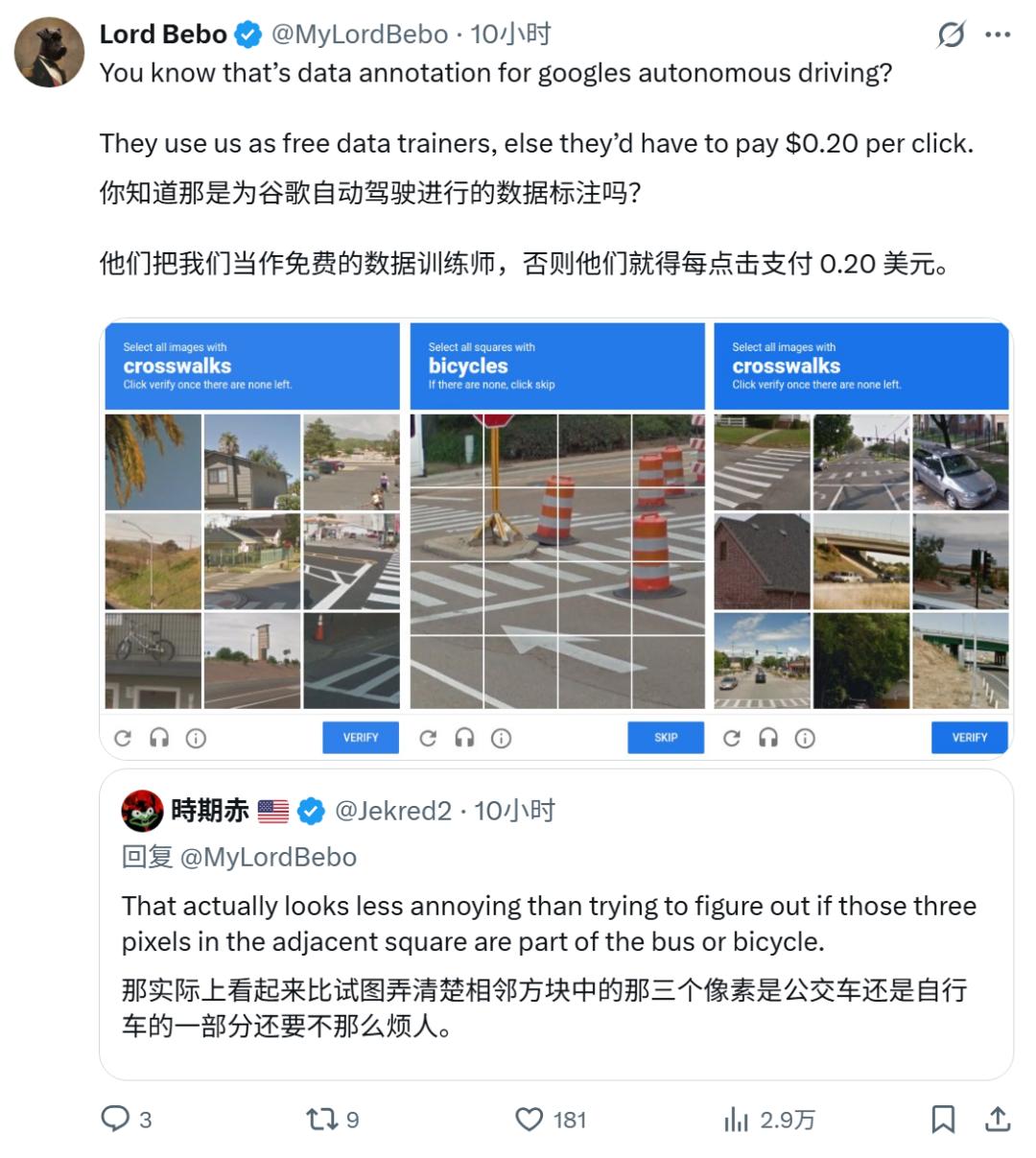
帮 AI 训练数据?这就要展开说说了。
众所周知,不管是注册账号还是发帖,验证码都是个必不可少的东西。它的「大名」叫 CAPTCHA,全称是「全自动区分计算机和人类的图灵测试」。它的作用,顾名思义就是区分人和机器人,避免机器人刷屏、刷票或搞破坏。
最早,其主要形式是扭曲的文字或图片。扭曲的程度,决定了它难不难被认出来。

但很快,一个叫 Luis von Ahn 的天才(他也是后来「多邻国」的创始人)站了出来。他发现全球每天有数亿人(现在是数十亿)在戳这些验证码,加起来浪费的时间高达数百万小时。这不纯纯浪费「人力脑循环」吗?

于是,一个「一箭双雕」的天才想法诞生了,它叫reCAPTCHA。
这套系统从 v1 开始,就不是一个单纯的「保安」,它是一个「大型人力众包项目」。
系统每次会弹给你两个扭曲的单词,这两个词里,只有一个是系统知道答案的「控制词」,用来确定你是不是人。另一个「未知词」,才是谷歌的「私货」——它来自某个古老的、AI OCR(光学字符识别)啃不动的扫描版图书或报纸。
你根本不知道哪个是哪个,所以你会老老实实把两个都填对。
结果呢?全球网民在毫不知情的情况下,用这种「无意识劳动」,硬是把《纽约时报》从 1851 年以来的全部历史档案,和海量的「谷歌图书」项目,给一个词一个词地免费「转录」成了数字版。
但是,我们亲手「喂」出来的 AI(谷歌的 OCR),把老师傅(v1 文本验证)给「卷」死了。
到了 2014 年,谷歌自己都公开承认,自家 AI 破解最难的扭曲文本,准确率高达 99.8%。这背后是「卷积神经网络」(CNN)的功劳。学术研究(如 CapNet)早已证实,这类 AI 模型破解文本验证码的准确率普遍达到了 98% 甚至 100%,v1 防线在技术上已彻底失效。
谷歌博客: https://security.googleblog.com/2014/04/street-view-and-recaptcha-technology.html
防线必须升级。于是,v2 图像验证来了。

这套「我不是机器人」你熟不熟悉?「选出所有汽车」、「选出所有交通信号灯」、「选出所有人行横道」。那么问题来了,几乎在同一时间(2014 年左右),谷歌在疯狂「烧钱」哪个项目?
没错,自动驾驶(Waymo)。
一个自动驾驶 AI,最需要训练什么?当然是识别「汽车」、「交通信号灯」、「人行横道」和「自行车」。也就说,全球几十亿网民,在登录、注册、发帖时,都在免费为谷歌的自动驾驶 AI 打工。
这个「人类计算」项目有多庞大?有学者估算,在过去十几年里,人类贡献的这波无偿劳动,总价值超过 61 亿美元。
到了 2024 年,AI 终于「学成下山」,把第二个老师傅(v2 拼图)也给「干」翻了。
瑞士苏黎世联邦理工学院(ETH Zurich)的研究人员提交了一篇论文,题为「Breaking reCAPTCHA v2」(攻破 reCAPTCHA v2)。他们使用先进的 YOLOv8 物体检测模型,破解 v2 图像挑战的准确率达到了100%。

论文地址: https://arxiv.org/abs/2409.08831
这类模型之所以如此强大,正是因为它们在海量的、已被精确标注的数据集(reCAPTCHA v2 帮忙创建的那种)上训练出来的。
研究甚至表明,AI 解决这些难题的表现和人类「没有显著差异」。那你可能要问了:「既然 AI 都 100% 破解了,为啥我还在天天点那些该死的红绿灯?」
因为,那张拼图早就不是真正的防线了。
2024 年的这项研究同时证实了一个「公开的秘密」:reCAPTCHA v2 的真正命脉,在于对你隐私数据的分析。
还记得那个「我不是机器人」的复选框吗?谷歌的「先进风险分析引擎」根本不在乎你是否点击,而在乎你如何点击。它在后台疯狂「视奸」你的:
- 鼠标轨迹:你的移动是平滑中带点「人气」的抖动,还是机器人的完美直线或瞬移。
- 点击位置:你是点在方框中间,还是不偏不倚的正中心(机器人行为)。
- 浏览器指纹:你的屏幕分辨率、插件、字体……
- 谷歌 Cookie:这才是「大杀器」。一个长期登录谷歌账户、浏览记录「清白」的用户,远比一个刚清除 Cookie 或开着 VPN 的用户「更像人」。
这场攻防战在学术界早已白热化。
进攻方(AI 攻击):攻击者面临一个「先有鸡还是先有蛋」的问题:你需要一个 AI 求解器来自动收集海量样本,但你又需要海量样本来训练这个求解器。
答案是「生成对抗网络」(GAN)。研究指出,攻击者只需少量(例如 500 个)真实样本,就能训练一个 GAN。这个 GAN 的「生成器」会伪造新的验证码,而「判别器」则学习破解它们。这个过程可以无限地生成合成的训练数据,AI 攻击者的「军火库」就此建成了。
防守方(v3 转向):既然拼图守不住,防线就全面转向了 reCAPTCHA v3。它的学术术语叫「行为生物识别」(Behavioral Biometrics)。这才是 v3 的核心。
reCAPTCHA v3 彻底隐形,会在你访问的所有页面上运行,像个监工一样默默观察你的所有行为(鼠标、滚动、键盘节奏),然后给你打一个 0.0(机器人)到 1.0(人类)的「可信度分数」。
这个转向的代价是巨大的:
- 隐私噩梦:这种大规模监控被指控为「间谍软件」,并与 GDPR 等隐私法规严重冲突。
- 隐私悖论:你越是努力保护隐私(用 VPN、清 Cookie、用隐私浏览器),你就越拿不到「可信」数据,v3 给你的分数就越低,你就越「像个机器人」。
- 「酷刑」级难度:唯一能制裁 AI 的方法,就是把拼图搞得巨难无比。结果,AI 没防住,反而把视障、听障或有阅读障碍的用户(Dyslexia)彻底锁在了门外。
那么,当 v3 的「行为监控」也因隐私问题和 AI 模拟而失效时,该怎么办呢?
还是前面那个 ETH Zurich 的研究团队,提出了一种最「黑客帝国」的方案:「对抗性 CAPTCHA」(Adversarial CAPTCHA)。

- 论文标题:Seeing Through the Mask: Rethinking Adversarial Examples for CAPTCHAs
- 论文地址:https://arxiv.org/abs/2409.05558v1
这个想法是利用 AI 的一个致命弱点:它们很容易被「对抗性样本」欺骗。这是一种人类肉眼看来毫无意义的「噪音」图像,但 AI(如 CNN)却会以 99.9% 的置信度将其误认为某个特定物体。

未来的验证码,可能不再是「你是否能解决人类的问题」,而是「你是否会犯 AI 才会犯的错误」。
所以,回到开头的那个「铲猫屎」验证码。
你以为你是在逗猫?没准,你是在给某个「AI 铲屎官」机器人,免费上岗前培训呢。或者,你是在向系统证明,你不会傻到去点击一张 AI 误以为是「猫屎」的电视雪花点。
