

在经历了GPT-5、Grok 4和Claude Sonnet小升级后,2025年下半年,AI领域陷入了阶段性平淡。
直到今天,Gemini 3的发布彻底打破了平淡。

跃进式的得分提升、强大的多模态理解力、更加多样化的UI、惊艳的前端能力,这一切都真实地让AI向我们预期的形态迈出了显著的一步。
这些可见性远比Benchmark上的得分和只能在Coding系统里测出来的区别明显。
Gemini 3 不仅仅是一次版本号的更迭,它是对Scaling Law信仰的暴力重申,也是谷歌第一款真正意义上让OpenAI黯然失色的模型。

在这次发布会上,我们熟悉的谷歌王者归来。它不满足于在某个单一维度领先,而是要在模型能力、开发者工具、用户体验、搜索集成、多语言覆盖等所有战线上同时发力。
这是一个平台级的野心,用AI重新定义整个Google生态的每个触点。
01 Benchmark 的跃迁
Benchmark测试在AI圈内一直饱受争议,被戏称为刷题比赛。前几个月顶尖模型之间的分数只差几个百分点,你追我赶。
但Gemini 3的出现,把原本胶着的战争直接变成了断层式的碾压。
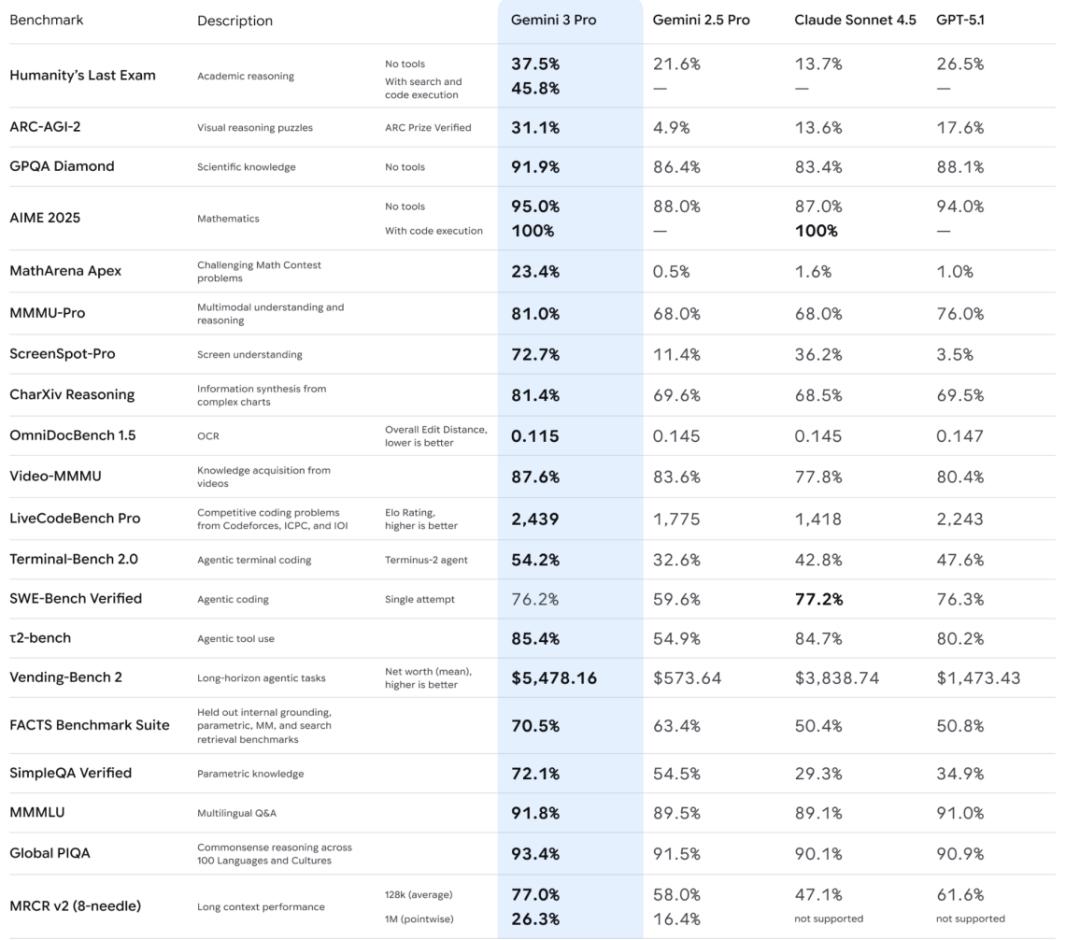
先看基础思考能力。Humanity's Last Exam (HLE)是衡量 AI 能否解决人类顶尖难题的终极试金石。在Gemini 3之前,Gemini 2.5 Pro的得分是21.6%,Claude Sonnet 4.5仅为13.7%。Gemini 3 Pro交出的答卷是37.5%(无工具)和45.8%(带工具)。
ARC-AGI-2测试,被誉为 AI 界的图灵测试,旨在衡量模型处理从未见过的新颖推理任务的能力,而非死记硬背。
Gemini 3 Pro 拿下了31.1%的分数,而GPT-5.1仅为17.6%,Gemini 2.5 Pro甚至只有 4.9%。这意味着它开始展现出一种接近人类的流体智力,能够在没有大量训练数据覆盖的领域进行抽象推理 。
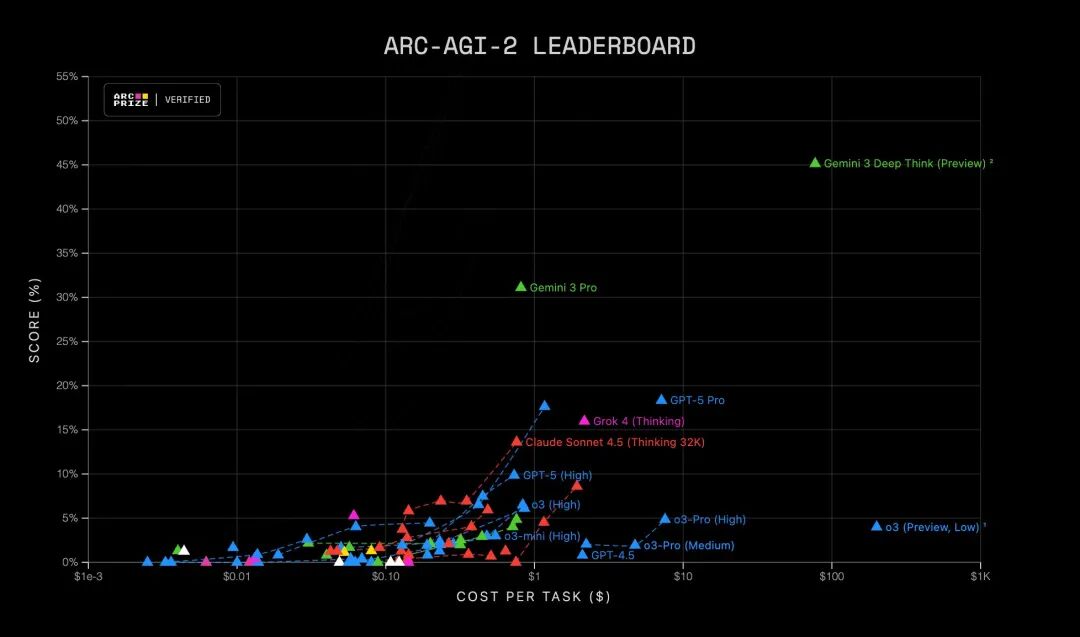
连ARC Prize的创始人François Chollet在看到结果后发推文说:“我们刚刚验证了Gemini 3 Pro和Deep Think在ARC v2上超过SOTA 2倍以上!这真的很令人印象深刻,说实话,也有点出乎意料。”
而且Gemini 3 Pro解决最快的v2任务只用了772个token和188秒,几乎接近人类评审小组的147秒平均速度。
数学能力上,Gemini 3引入了一个新的MathArena Apex竞赛级Benchmark来强调其超越性。在这项测试里,Gemini 2.5 Pro的得分只有0.5%,Claude Sonnet 4.5是1.6%,GPT-5.1是1.0%。而Gemini 3 Pro得到了23.4%的成绩。
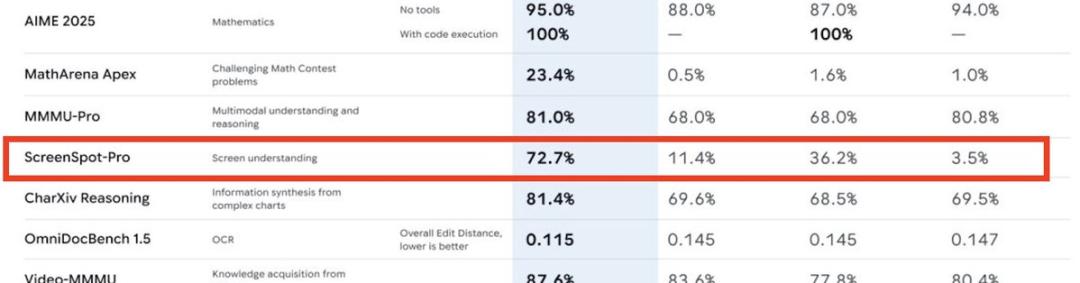
在多模态领域这个谷歌的强项上,Gemini 3表现得更为惊人。
MMMU-Pro的81.0%,CharXiv Reasoning的81.4%都超越了对手。而在理解截图的测试ScreenSpot-Pro的72.7%中,Gemini 3的得分是Claude Sonnet 4.5的两倍,GPT-5.1的二十倍。这对于构建能够真正理解和操作图形界面的AI代理至关重要。
02 编码能力过去一直是谷歌的弱项,但这次彻底翻盘
虽然在SWE-Bench Verified这个测试真实软件工程能力的benchmark上,Gemini 3的76.2%仍然不敌Claude的77.2%得分。
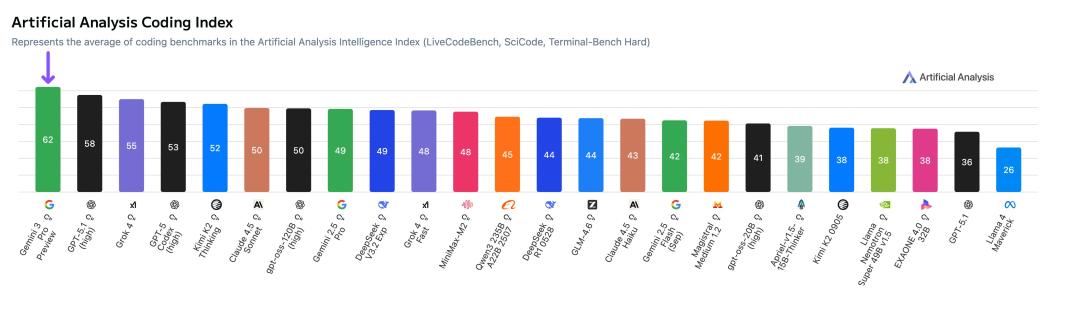
但在其他核心第三方的测试中,谷歌却远高于对手。在LiveCodeBench上,Gemini 3的分数比第二名Grok 4.1直接高了200多分。
在测试 Agent 工具使用能力的12-bench 中,Gemini 3 Pro拿到了 85.4% 的高分,远超Gemini 2.5 Pro的54.9% 。而在更符合终端环境的Terminal-Bench 2.0中,Gemini 3得到了54.2%,比第二名高出11个百分点。
这在很大程度上是一种综合能力的展示。
有了更好的屏幕理解能力和基于多模态能力衍生的前端审美,Gemini 3在真实编程环境下的表现很容易超越对手。
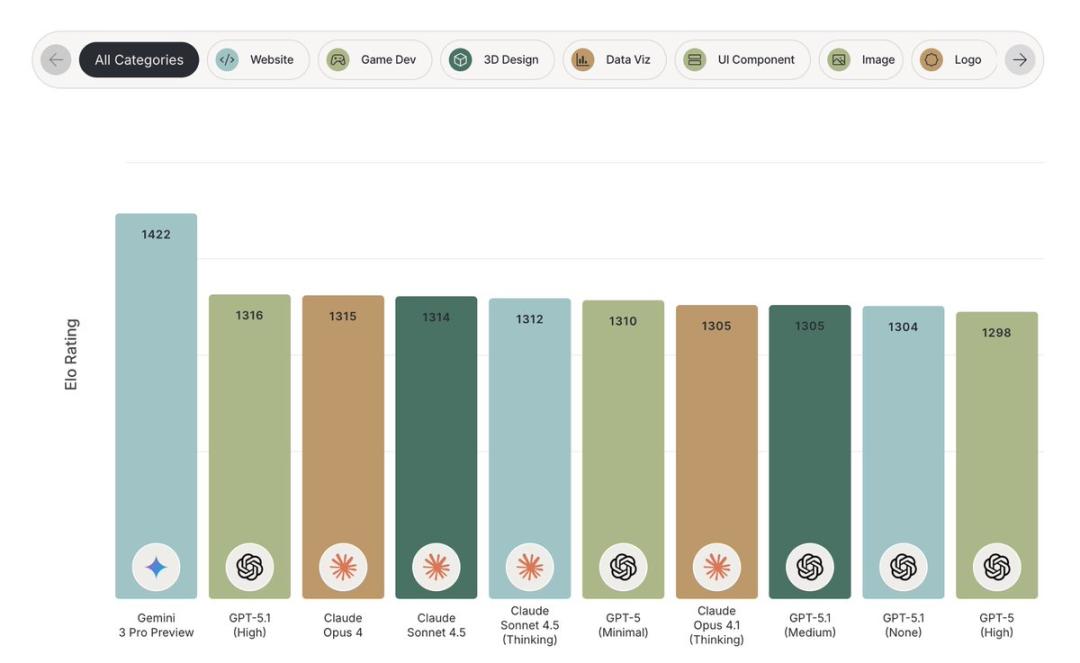
比如,在由开发者社区运营的实战编码竞技场Design Arena中,Gemini 3 Pro在整体排名中位列第一,并在五个代码赛区中的四个,网站、游戏开发、3D设计和UI组件中都占据榜首。这是自推出Design Arena以来最大的性能差异。
记忆一直都是一个很大的模型瓶颈。因此Gemini 3在长上下文能力的提升也值得关注。
它在MRCR v2 benchmark中28k上下文的平均得分77.0%远超竞争对手,1M上下文的逐点得分26.3%。
这说明,Gemini 3不是简单地“塞入”更多tokens,而是真正理解和利用长文档中的信息。
根据Artificial Analysis的分析,Gemini 3在事实回忆(factual recall)上也有着强大表现。
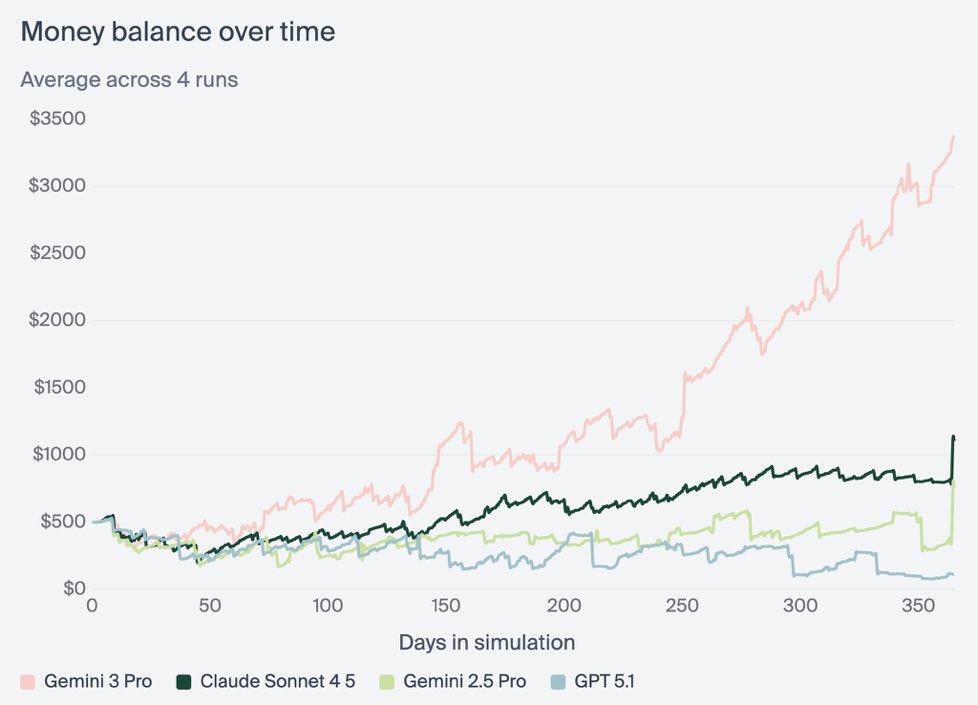
最后,看一下综合能力。Vending-Bench 2是一个测量AI模型在长时间跨度内运营业务能力的benchmark,模型需要在一年时间内运营一个模拟的自动售货机业务,并以年底的银行账户余额作为评分标准。
这个测试在今年相当火爆,因为在Benchmark逐渐饱和的当下,和Agen落地的困难下,各个公司更看重模型能否在长时间、多步骤、需要持续状态跟踪的复杂任务中保持性能。而Gemini 3实现的$5,478.16平均净值,相比GPT-5.1的$1,473.43和Gemini 2.5 Pro的$573.64提升也是断崖式领先。
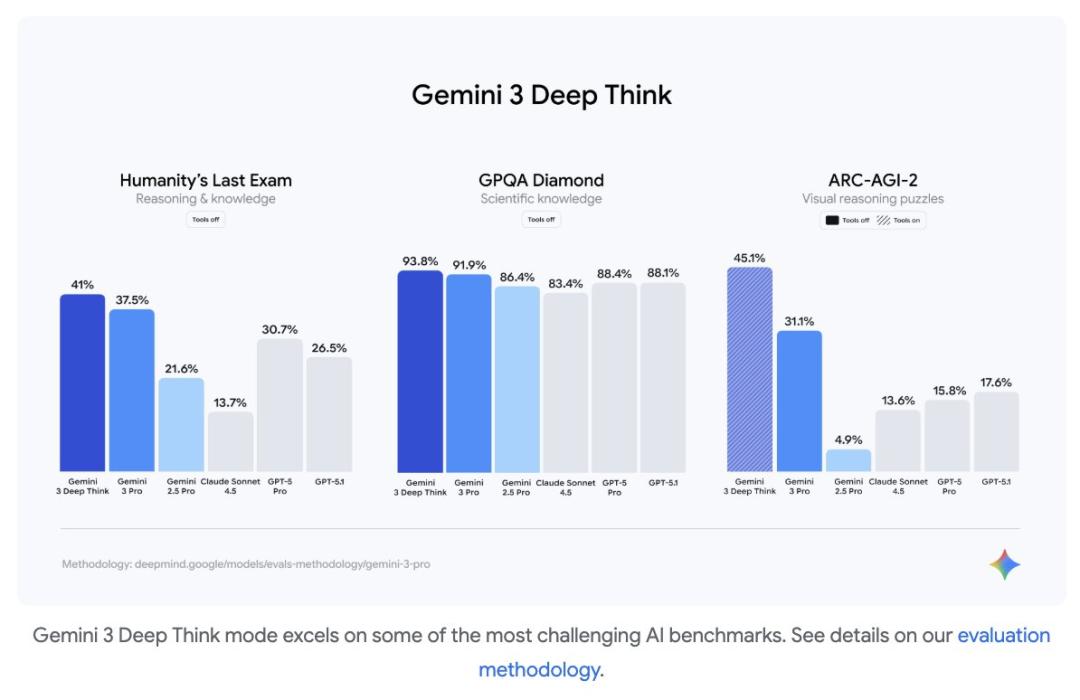
除了Pro版本,Gemini 3也推出了Deep Think模式。这是Google对OpenAI等模型推出的Hard模式的一种回应。虽然它的Benchmark水平比Pro更高,但其token花费也基本上高了一个数量级。
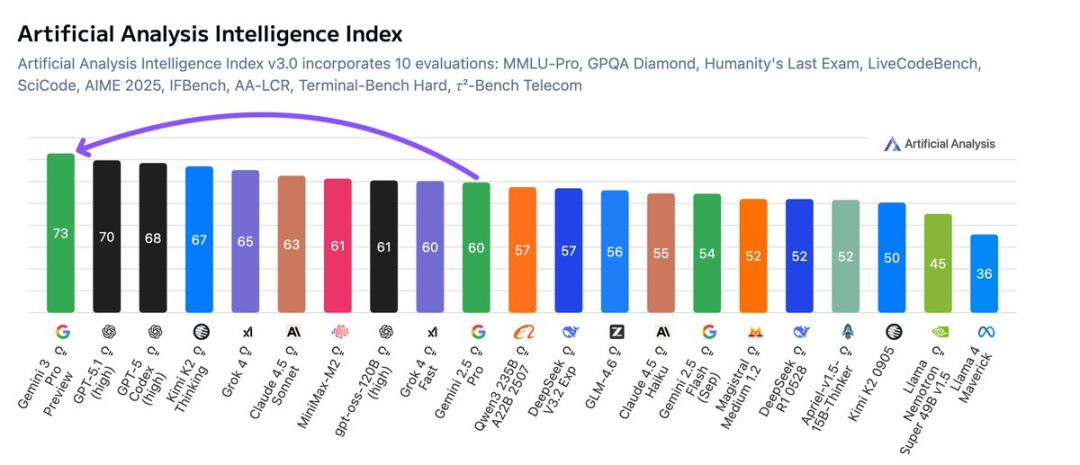
Artificial Analysis的最终排名没有任何悬念:Gemini 3 Pro 以显著优势位居第一,比GPT-5.1高出3分。
这是Google第一次在其推出的语言模型中,以绝对优势占据了领袖地位,终结了OpenAI长久以来的霸榜神话。
但数字之外,更重要的是实际使用体验。
一位名叫Tailen的开发者在提前测试后写道:“这个模型在我最难的问题上,远远超越了GPT-5 Pro、Gemini 2.5 Deep Think以及其他所有模型。”他列出了Gemini 3建立新SOTA的领域:调试复杂的编译器错误、在不产生逻辑错误的情况下重构文件、解决困难的λ-演算问题,甚至在ASCII艺术上都“几乎还不错了”。
03 前端的黄昏
Gemini 3 在Design Arena的统治性表现不是偶然。开发者们发现,Gemini 3不仅能写出功能正确的代码,更重要的是,它能够理解审美。在很多设计中,我们都能看到响应式设计自然流畅,色彩搭配符合现代审美,动画效果恰到好处,无障碍性考虑周全。
这种审美智能的来源部分是训练数据。根据Gemini 3的Model Card披露,Gemini 3的训练数据包括大量的图像、视频和网页数据,这说明模型不仅学会了如何编码,还学会了什么样的界面是好看的,布局优质的。
利用这种前端上的优势,Google 推出了“生成式 UI”(Generative UI)。传统的对话式AI给你文本回答,高级一点的给你结构化数据或图表。但Generative UI意味着AI根据每个请求动态生成一个完全定制的用户界面。
这彻底改变了人机交互的范式,也成了用户直观感受跃迁最明显的点。
发布会上,谷歌给出的范例是“RNA 聚合酶是如何工作的?”。 Gemini 3生成一个直观的、可点击的交互式工具。
之所以叫定制,是因为模型可以根据用户意图、使用场景、目标受众改变其设计。为5岁孩子解释微生物和为成年人讲解微生物,Gemini 3知道这需要完全不同的界面设计、交互模式和内容深度。它能推断出对孩子需要大的按钮、鲜艳的色彩、简单的语言和游戏化元素,而对成人则需要更多信息密度、专业术语和深度解释。
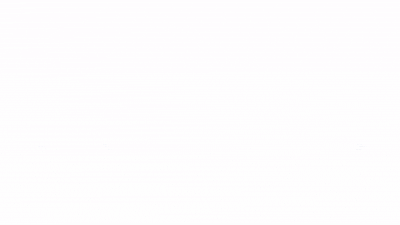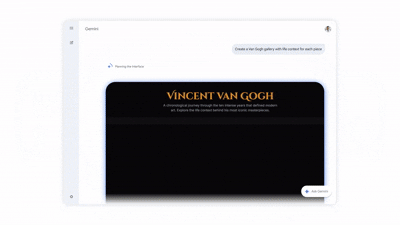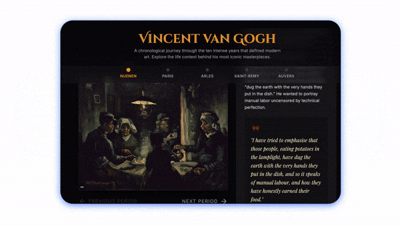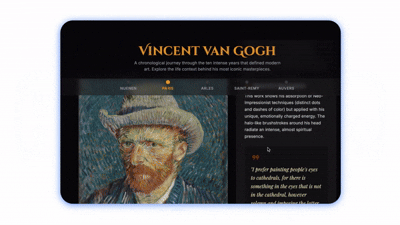
这正是新一代AI最应该具有的能力,超越对话,成为一个多信息的嵌合体。
在多轮对话中,Gemini 3能够理解你的审美偏好、编码风格,甚至是你没有明说的设计原则。如果你倾向于极简主义,几次交互后,Gemini就会自动在后续生成中减少装饰性元素。如果你喜欢丰富的动画,它会逐渐增加交互效果的复杂度。
这一能力,基本上已经被网络测试员玩出花来了,各种各样的前端UI、3D展示 Gemini都能做的有模有样。
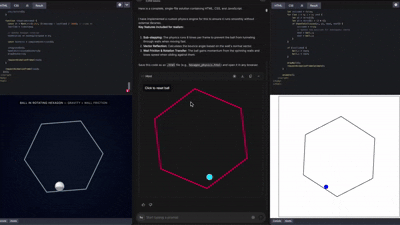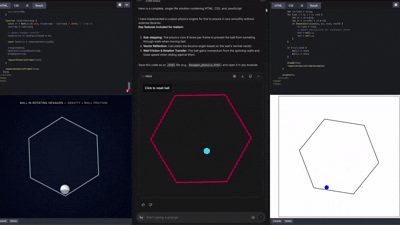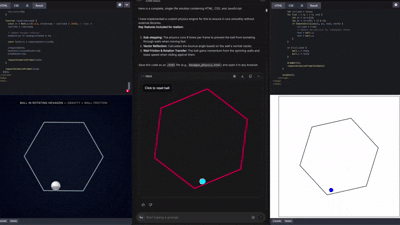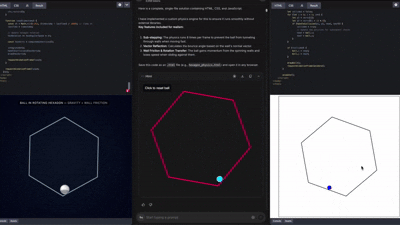
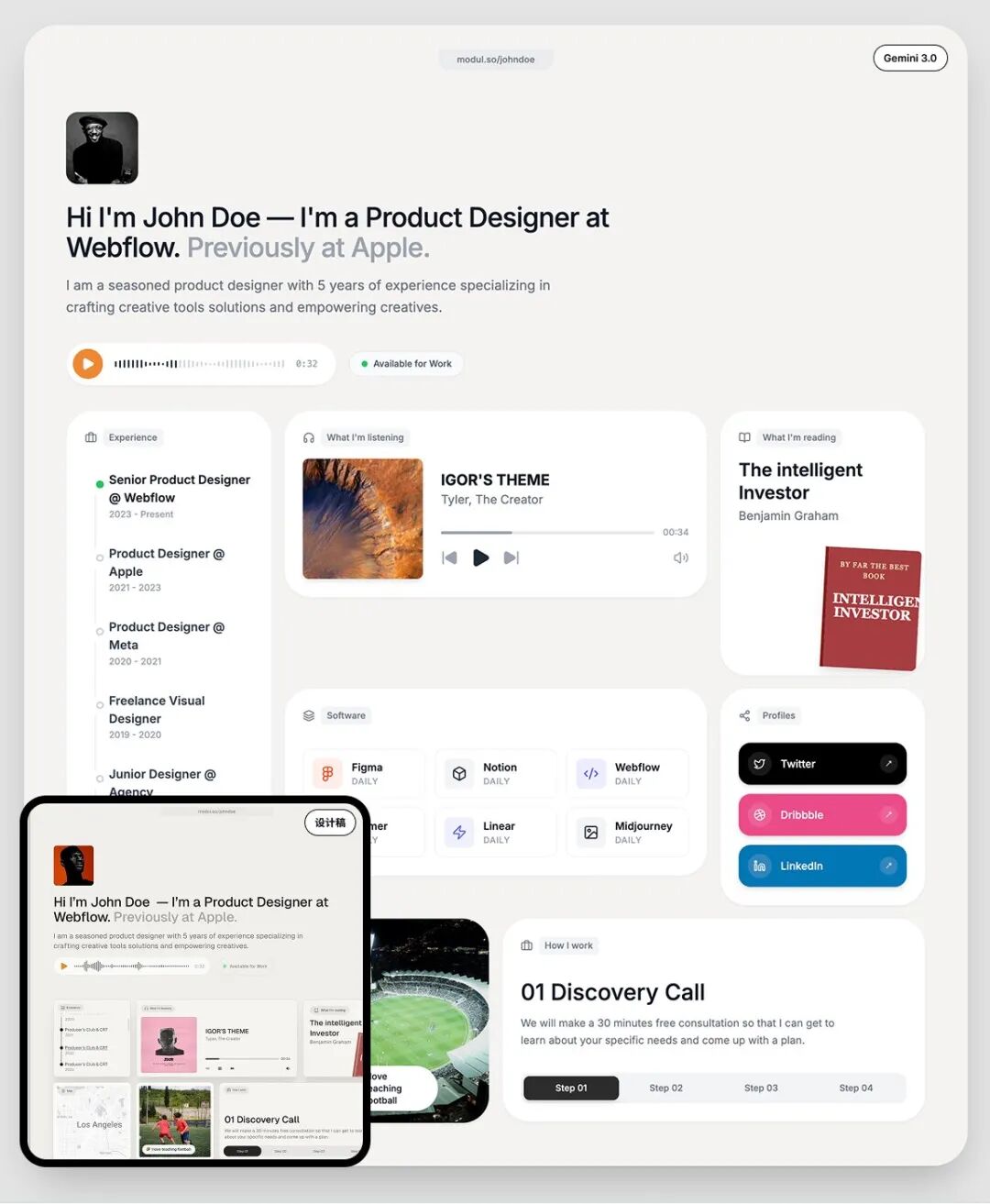
在这样的能力之下,前端的角色正在逐步被模型吞没。
04 新一代的模型即Agent
在2025年,一个重要的趋势就是模型即Agent。通过越来越强的工具调用能力和模型规划能力,基础模型变得越来越像Agent。
GPT-5的发布会上,OpenAI就推出了AgentKit,让开发者用一种工作流方式开发Agent,成为新一代的AI内App。
但在今天之前,几乎没有任何一家基础模型公司在to C的产品中添加通用Agent能力。因为这对于模型的考验相当大,它需要真的进化成能够理解任务、制定计划、使用工具、反思改进的Agent。
Gemini 3首先完成了这一跃,成了第一个在模型界面融合通用Agent能力的产品。
这种自信并非毫无根据。根据Model Card,它被训练使用了强化学习技术,能够利用多步骤推理、问题解决和定理证明数据。这种能力的技术基础部分来自于改进的函数调用(function calling)能力。根据发布资料,Gemini 3的工具使用能力相比2.5 Pro提升了30%。这不仅意味着它能更准确地选择正确的工具,更重要的是,它能理解何时需要组合多个工具来完成复杂任务。
有用户让Gemini 3帮助学习一门新语言。传统AI会提供学习计划和资源链接。但Gemini 3生成了一套完整的交互式学习系统:词汇卡片带有间隔重复算法,语法练习带有即时反馈,发音练习集成了语音识别,进度追踪可视化。
它还整合了Google庞大的生态系统,新的“My Stuff”文件夹设计让用户更容易找到模型创建的图片、视频和报告 ,并且应用内现在可访问超过500 亿条商品列表 。
05 Scaling Law的延续
在2025年,关于Scaling Law是否撞墙的争论已经持续了一年多。怀疑论者指出,训练成本的指数增长、数据的逐渐枯竭、回报的边际递减。
但Gemini 3表示——“我不认”。
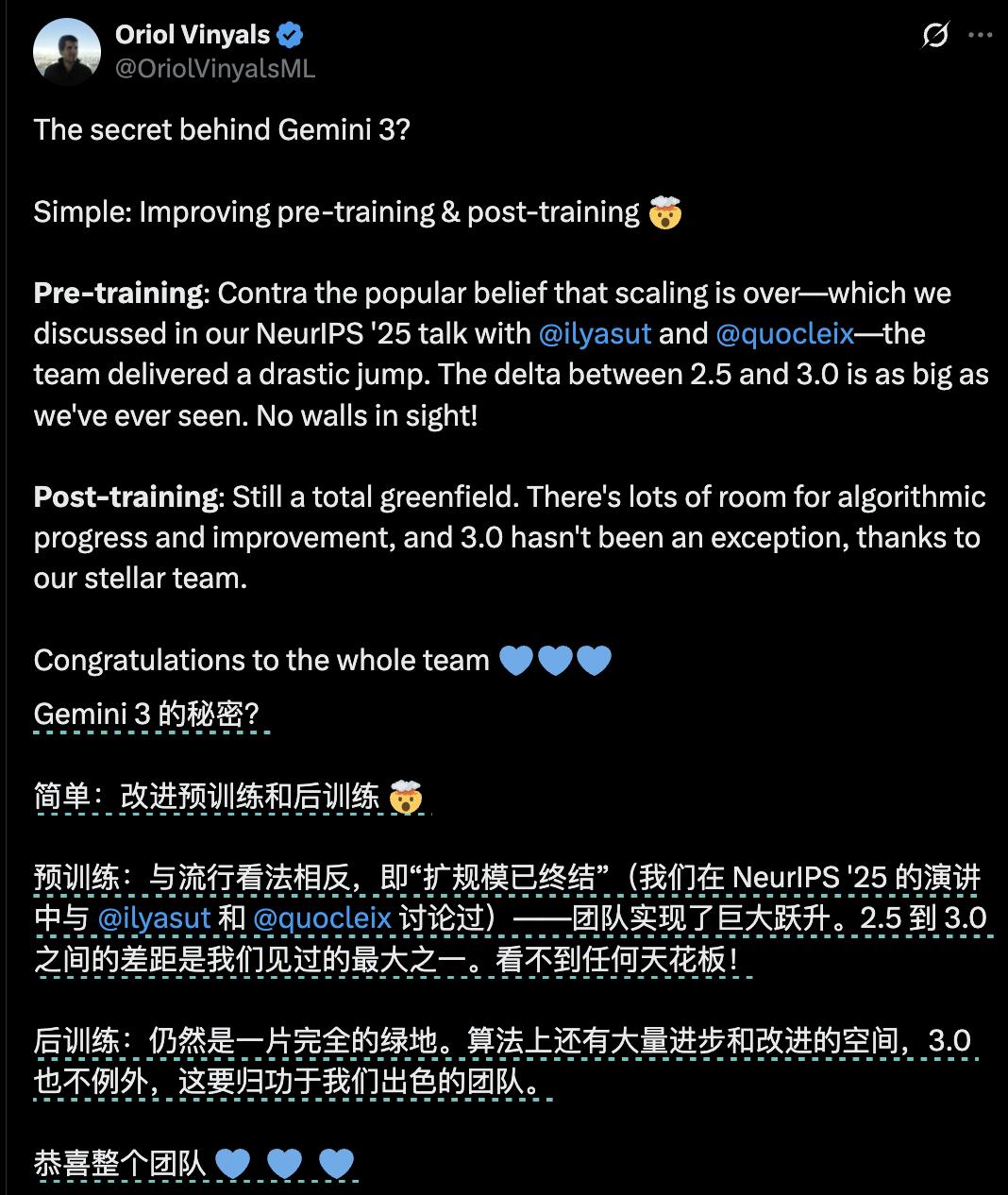
Oriol Vinyals,Google DeepMind的VP of Research、Deep Learning Lead和Gemini项目的联合负责人,在Gemini 3发布后发推文说:“Gemini 3的秘密?简单:改进预训练和后训练。后训练仍然是一片完全的绿地。算法上还有大量进步和改进的空间”。他特别强调:“与流行看法相反,即‘扩规模已终结’——团队实现了巨大跃升。2.5到3.0之间的差距是我们见过的最大之一。看不到任何天花板!”
具体Gemini 3有什么秘密武器,这个当下还是未知数。Model Card只透露了Gemini 3 Pro采用sparse mixture-of-experts (稀疏MoE)架构。 这说明Gemini 3 并非Gemini 2.5的微调,而是个全新的架构。在今年四月,谷歌颁布新政,DeepMind核心论文禁发6个月,这使得草灰蛇线去发现模型背后的进步变得更困难。
不过从产品和少量论文证据上,我们还是能看到谷歌的着力点。在Veo 3和Genie 3的发布中,我们能看到谷歌发现了多模态的能力的进步。在Agent领域,谷歌AI Co-scientist 、SIMA 2 都说明他们在研究新的Agent自动化强化方法。而谷歌刚刚在Nature发布的持续学习论文DiscoRL,和自进化的Agent Alpha Evolve则在一定程度上验证了Gemini Agent这种自适应能力的发展。
当把这些都组合起来时,其能力闭环就显示出来了。
ScreenSpot-Pro的高分确保了Agent的规划能力建立在可靠的观察之上,从而有效降低因误解环境而导致的执行错误。而通用Agentic控制回路,利用这种感知能力进行可靠的规划和执行。再加上RL突破(DiscoRL)确保了训练过程的效率和可扩展性,谷歌能够快速迭代和优化Agent的策略 。
这种对从算法(DiscoRL)到感知(MM)再到执行(Agent)的整个AI开发管线的优化,创造了一个性能乘数,超越了仅优化单个组件的竞争对手所能达到的效果。
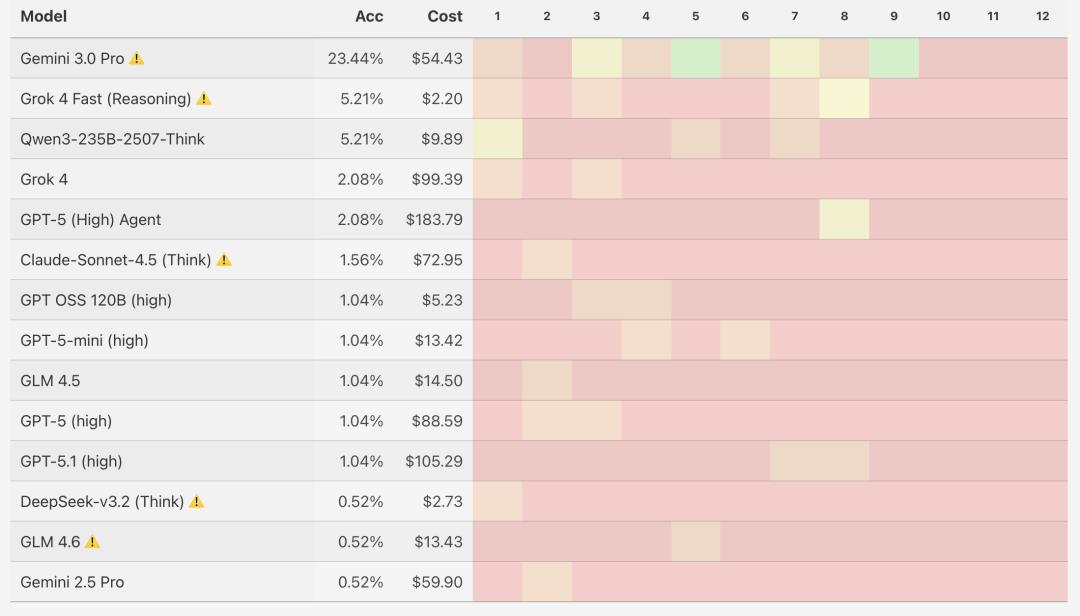
不过,这种Scaling Law也有一些局限性。François Chollet在观察ARC-AGI结果时注意到一个矛盾:“Gemini 3 Pro在v2上得分约一半,但在更简单的v1上仍然会犯明显错误。”而且Gemini 3 Pro 能用 2000 个推理 token 解决的问题,Deep Think 模式可能消耗 30 万个 token 仍告失败 。因此他认为AI推理系统的流体智能提升是不均匀的,“似乎集中在那些推理模型具有良好基础训练数据覆盖且该领域存在可验证反馈信号的领域。”
另外,Gemini 3还开启了一个新的性能-成本比逻辑。在API上,Gemini 3 Pro的定价并不亲民,每百万输入/输出Token的价格高达$2/$12 ,是目前运行成本最高的模型之一。但考虑到它在token效率上却相对更高,比起其他如Kimi K2的模型,它在相同任务上用的tokens更少。这使得其实际使用成本的增加只有12%左右。
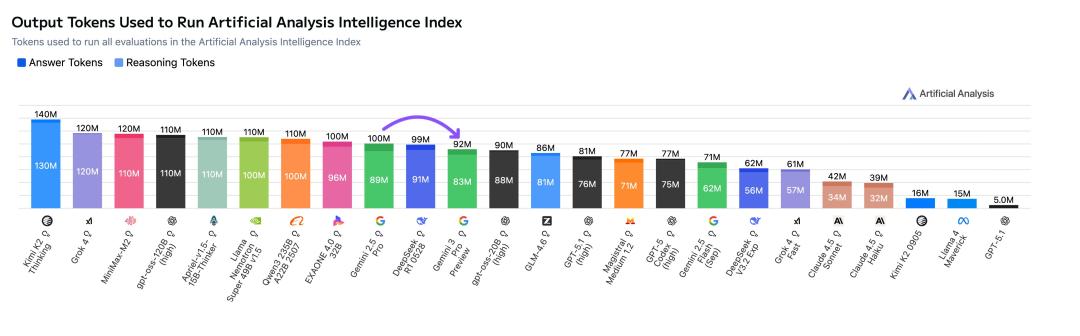
如果考虑到它能够一次性正确完成任务,它的总体成本可能反而更低。
06 王者归来
Gemini 3 Pro的发布,是Google向世界宣告王者归来的时刻。它没有玩弄文字游戏,没有发布虚无缥缈的Demo,而是直接把一堆让竞争对手窒息的数据和立即可用的产品甩在了桌面上。
它证明了前端开发可以被重新定义,Agent可以与UI融为一体,而最重要的是,它证明了通往AGI的道路上,Scaling Law依然是那座指引方向的灯塔。
如果要问谷歌这次带来的体验,到底凭什么说算是一种跃迁?沃顿商学院的教授Ethan Mollick体验完Gemini 3后的总结说得很恰当,“三年前,我们还为机器能写一首关于水獭的诗而惊叹。不到一千天后,我正在与一个为自己构建了研究环境的代理就统计方法展开辩论。聊天机器人的时代正在向数字同事的时代转变。需要非常明确的是,Gemini 3并不完美,它仍然需要一个能够引导和审查它的管理者。但它表明human in the loop的角色正从‘修复 AI 错误的人’演变为‘指挥 AI 工作的人’。这可能是自ChatGPT发布以来最大的变化。”
看完各种演示后,我也是如此感觉。这是一个让我真正安心、能够帮我做除了回答问题之外事情的AI。
当然,对于Sam Altman来讲,这无疑是一个不眠之夜的开始。
