

「开源之神」DeepSeek重磅发布V3.2正式版,性能全面超越GPT-5 High,与谷歌Gemini-3.0 Pro平分秋色。新模型不仅斩获4项国际奥赛金牌级成绩,更凭借独创的DSA稀疏注意力架构,打破「速度、成本、智能」的不可能三角。
OpenAI这次真的要慌了!
就在刚刚,「源神」DeepSeek开源了DeepSeek-V3.2正式版——
在数学编程等多项推理基准上,全面超越GPT-5 High,优于Claude 4.5 Sonet;
与刷屏的Gemini 3.0 Pro相比,则难分伯仲,不相上下!
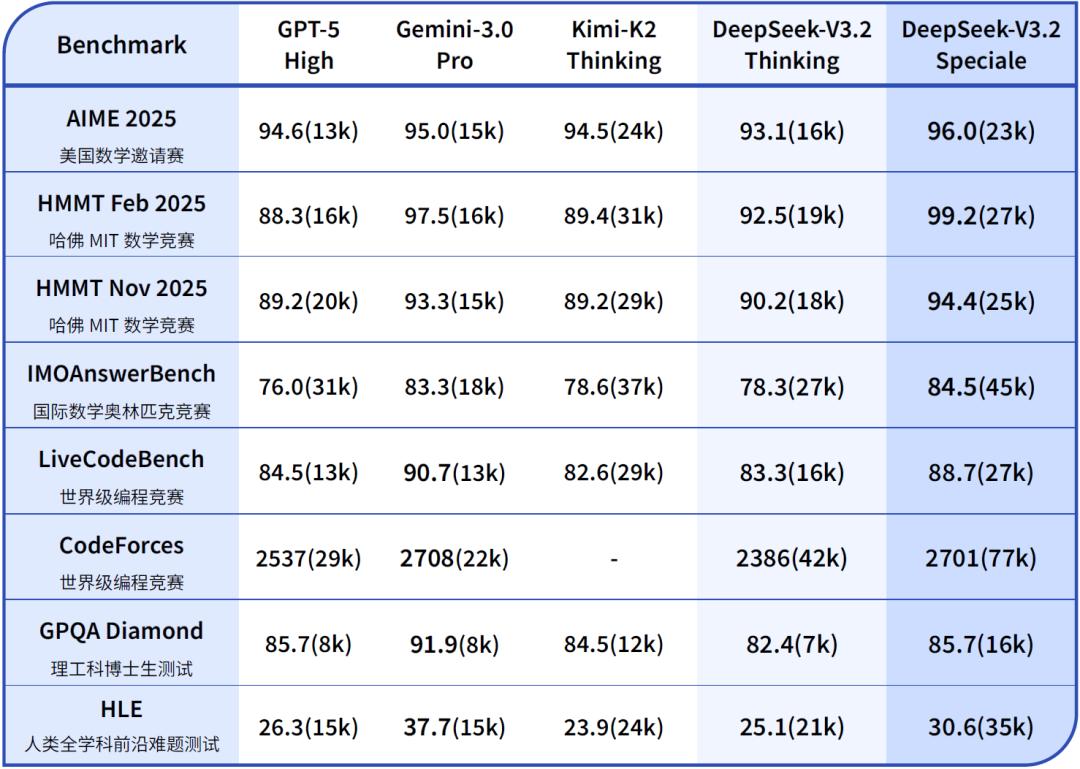
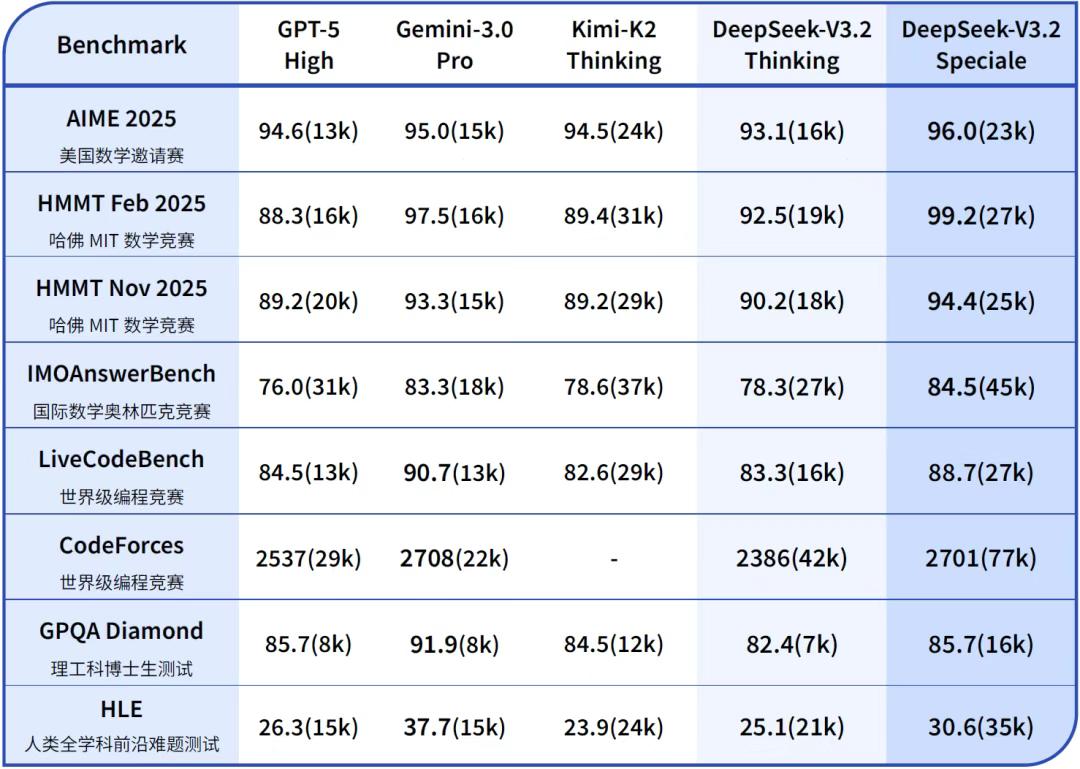
表1:DeepSeek-V3.2与其他模型在各类数学、代码与通用领域评测集上的得分(括号内为消耗Tokens估计总量)
在今年,DeepSeek此前已发布7款模型——「开源之神」,当之无愧:
DeepSeek‑R1、DeepSeek‑R1‑Zero
DeepSeek‑V3、DeepSeek‑V3.1、DeepSeek‑V3.1-Terminus、DeepSeek‑V3.2‑Exp
DeepSeek‑OCR、DeepSeek‑Math-V2
出手即王炸,开源4项奥赛金牌级AI
全新模型DeepSeek-V3.2,出手即王炸。
DeepSeek正式发布DeepSeek-V3.2与DeepSeek-V3.2-Speciale——专为智能体打造的推理优先模型!
- DeepSeek-V3.2:V3.2-Exp的官方迭代版本,现已登陆App、网页端及API;
- DeepSeek-V3.2-Speciale:突破推理能力边界,目前仅通过API提供服务。
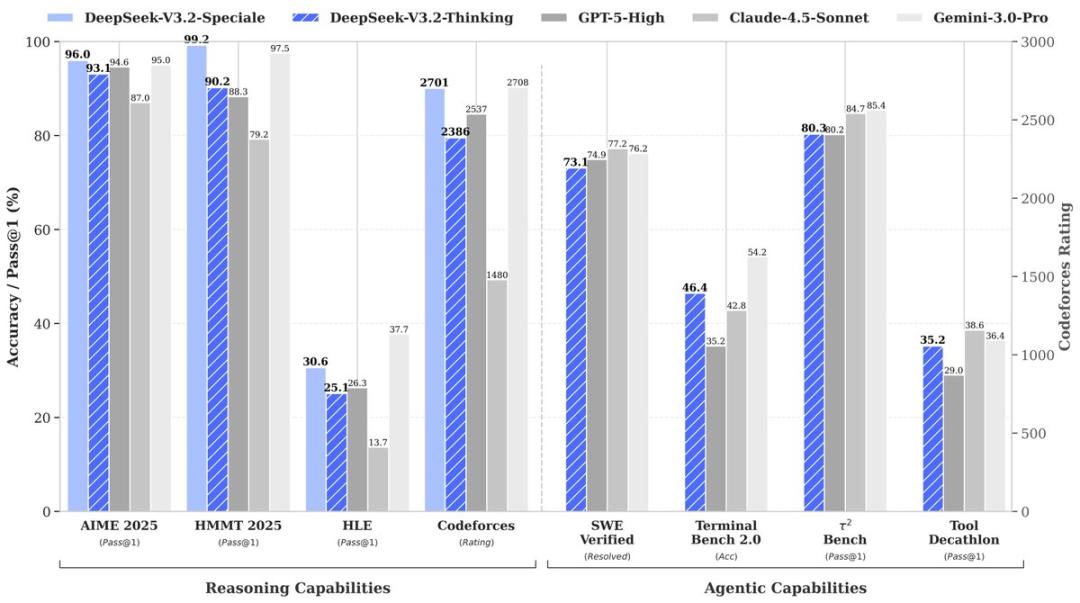
两款模型均达到世界级推理性能 :
- V3.2:推理能力与文本长度兼顾,拥有GPT-5级别性能,适合日常驱动;
- V3.2-Speciale:极致推理能力,取得了4项金牌级成绩;目前仅提供API版本(不支持工具调用),以支持社区评估与研究。
在主流推理基准测试上,DeepSeek-V3.2-Speciale的性能表现媲美Gemini-3.0-Pro(见表1)。
更令人瞩目的是,V3.2-Speciale 模型成功斩获多项金牌:
- IMO 2025(国际数学奥林匹克)
- CMO 2025(中国数学奥林匹克)
- ICPC World Finals 2025(国际大学生程序设计竞赛全球总决赛)
- IOI 2025(国际信息学奥林匹克)
其中,ICPC与IOI成绩分别达到了人类选手第二名与第十名的水平。
而DeepSeek-V3.2是首个将思考直接整合到工具使用中的模型,同时支持在思考和非思考模式下使用工具。
目前,两款模型均已开源:
· DeepSeek-V3.2
HuggingFace:https://huggingface.co/deepseek-ai/
DeepSeek-V3.2
ModelScope:https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2
· DeepSeek-V3.2-Speciale
HuggingFace:https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Speciale
ModelScope:https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2-Speciale
从「引擎验证」到「全能车手」,DeepSeek V3.2的进化论
如果说两个月前发布的DeepSeek-V3.2-Exp是一台在赛道上呼啸而过的「概念车」,用来向世界证明「稀疏注意力」引擎的动力潜力;
那么今天正式转正的DeepSeek V3.2,则是一辆完成了内饰精修、装配了顶级导航系统、可以随时上路解决复杂问题的「量产超跑」。
这就是DeepSeek V3.2相比于Exp版(实验版)最大的进化逻辑:核心引擎不变,但驾驶技巧(Agent能力)发生了质变。
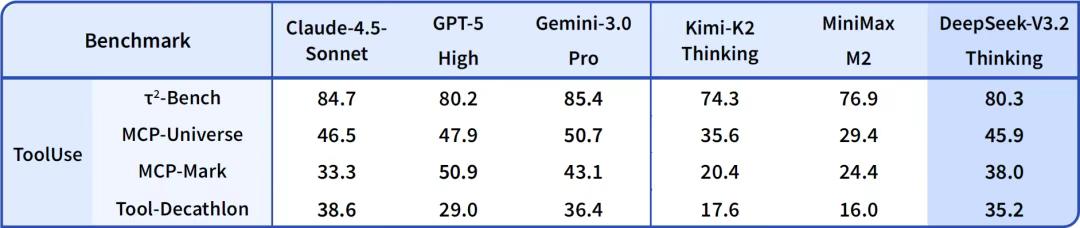
V3.2正式版 vs. Exp,学会了「边干边想」
在架构层面,V3.2沿用了Exp版本验证成功的DSA架构,但在「软实力」上,DeepSeek解决了一个困扰AI界的顽疾——思考与行动的断裂。
在V3.2-Exp时期(以及其他大多数推理模型),模型像是一个记性不好的老学究:它会先花很长时间思考,决定调用一个工具(比如搜索天气)。
但当工具把「今天是雨天」的结果扔回来时,它往往会「断片儿」,忘了刚才思考到哪一步了,不得不重新规划。
V3.2正式版引入了「思维上下文管理」。

这就像给模型装了一个「工作记忆暂存区」。
现在的V3.2像一位经验丰富的外科医生,在伸手要手术刀(调用工具)的间隙,脑子里的手术方案依然清晰连贯,拿到刀后能无缝衔接下一步操作。
为了练就这项绝活,DeepSeek甚至为V3.2搭建了一个「虚拟演练场」。
他们合成了1800多个虚拟的操作系统、代码库和浏览器环境,生成了8.5万条极其刁钻的指令,逼着V3.2在虚拟世界里反复练习「修Bug」、「查资料」、「做报表」。
正是这种高强度的特训,让V3.2正式版从一个只会做题的「做题家」,进化成了能熟练使用工具解决现实难题的「实干家」。
最大技术亮点,给注意力装上「闪电索引器」
V3.2能够同时兼顾「聪明」和「便宜」,其最大的功臣依然是那个名为稀疏注意力(DSA)的底层黑科技。
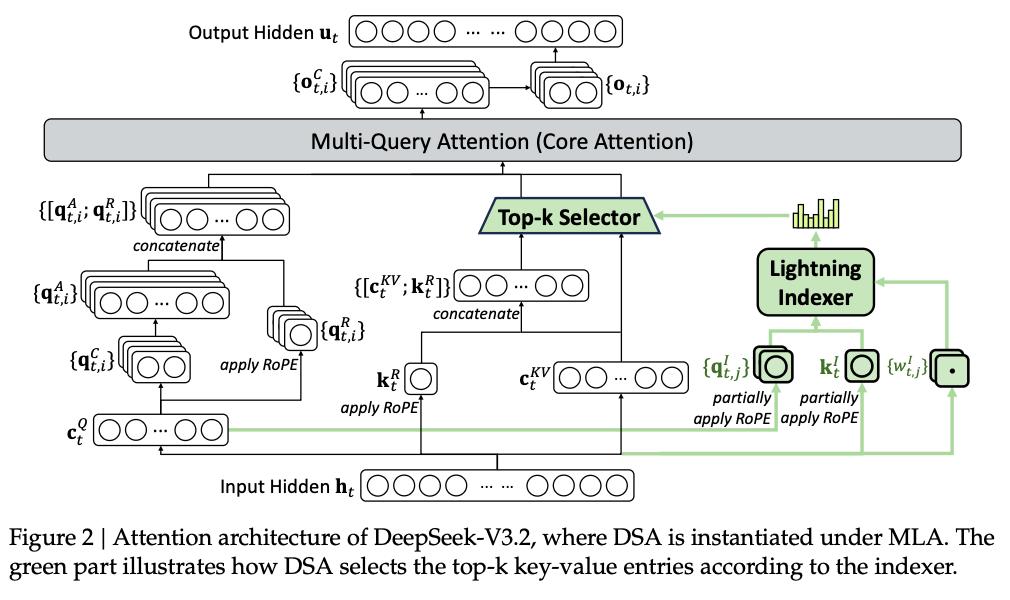
DeepSeek-V3.2的注意力架构
要理解它的牛逼之处,我们得先看看传统模型有多「笨」。
传统模型在处理长文档时,就像一个强迫症晚期的图书管理员:
为了回答你一个简单的问题,它强迫自己必须把图书馆里每一本书的每一页、每一行字都读一遍,并计算它们之间的关联。
这导致计算量随着书的厚度呈指数级爆炸(O(L^2))。
DSA则给这位管理员配备了一套「闪电索引器」。
当问题来临时,DSA先用极低的成本扫描一遍「索引」,瞬间判断出哪几页书可能包含答案,把无关的99%的废话直接扔掉。
然后,它只对这筛选出的1%的关键内容进行精细的深度阅读。
这种「查目录」而非「死磕全书」的策略,将计算复杂度从可怕的指数级直接拉低到了近乎线性(O(L))。
带来的显著提升,打破「不可能三角」
DSA技术的成功落地,直接击穿了AI领域的「速度、成本、智能」不可能三角。
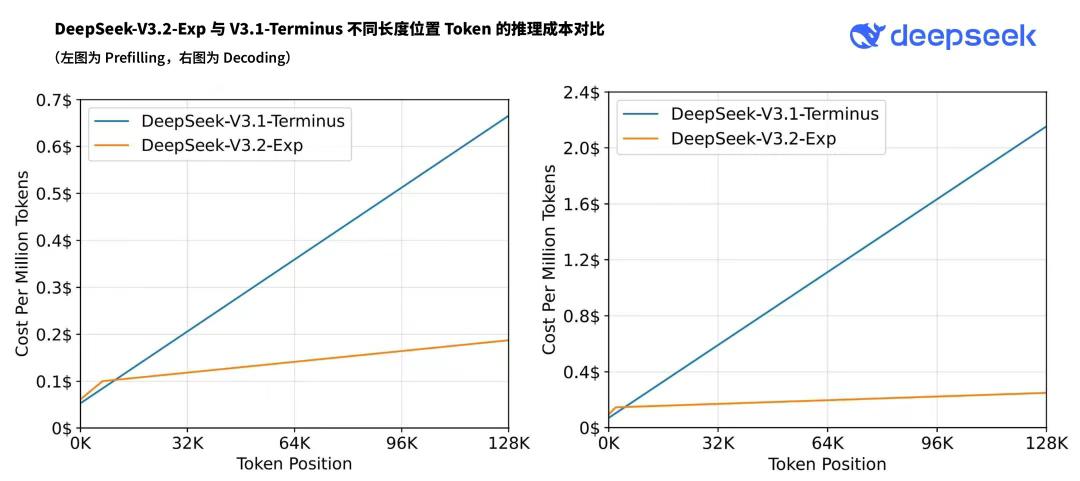
其一,成本腰斩,长文无忧。
对于用户来说,丢给模型一本几十万字的小说或代码库,不再是「烧钱」的奢侈行为,处理速度也从「泡杯咖啡」变成了「眨眼之间」。
其二,算力盈余带来的「智力涌现」,这是最精彩的一点。
正因为DSA节省了大量算力,DeepSeek才有底气推出那个恐怖的Speciale版本。
既然读得快,那就让它想得久一点!
Speciale版本利用节省下来的资源,进行更深度的「长思考」和逻辑推演。
结果是震撼的:DeepSeek-V3.2-Speciale在数学(IMO金牌)、编程(IOI金牌)等硬核指标上,不仅超越了GPT-5 High,更是与谷歌最强的Gemini 3.0 Pro战成平手。
从验证DSA引擎潜力的V3.2-Exp,到将Agent能力、思维上下文管理、虚拟演练场训练全部装车的V3.2正式版,DeepSeek展示的是另一条通往强智能的路线:在算力紧箍咒下,用更聪明的架构、更精细的训练和更开放的生态,撬动推理极限。
DeepSeek-V3.2的横空出世,正是DeepSeek开源AI的魅力时刻:拒绝无脑烧钱Scaling,靠更聪明的算法,在算力的缝隙中开辟出通往顶峰的捷径。
参考资料
DeepSeek V3.2 正式版:强化 Agent 能力,融入思考推理
