

作为计算机博士生并且还在做自己科技公司的产品经理,我发现我喜欢阅读上了那些技术论文。
因为论文不仅是有技术,更多的是哪些领先的算法或系统框架,都可以很快的集成在现在的系统里,从而完成用户问题解决,达到更高效率、用户体验更加,从而完成商业化闭环。
比如在上周字节跳动就更新了最新的模型Vidi2,模型能力简单来说就是将其视频可以进行快速解读,也就是不用人来看,就可以将其视频每一帧的画面进行解读,并且得到对应的结果数据。
这个模型就是VIDI2
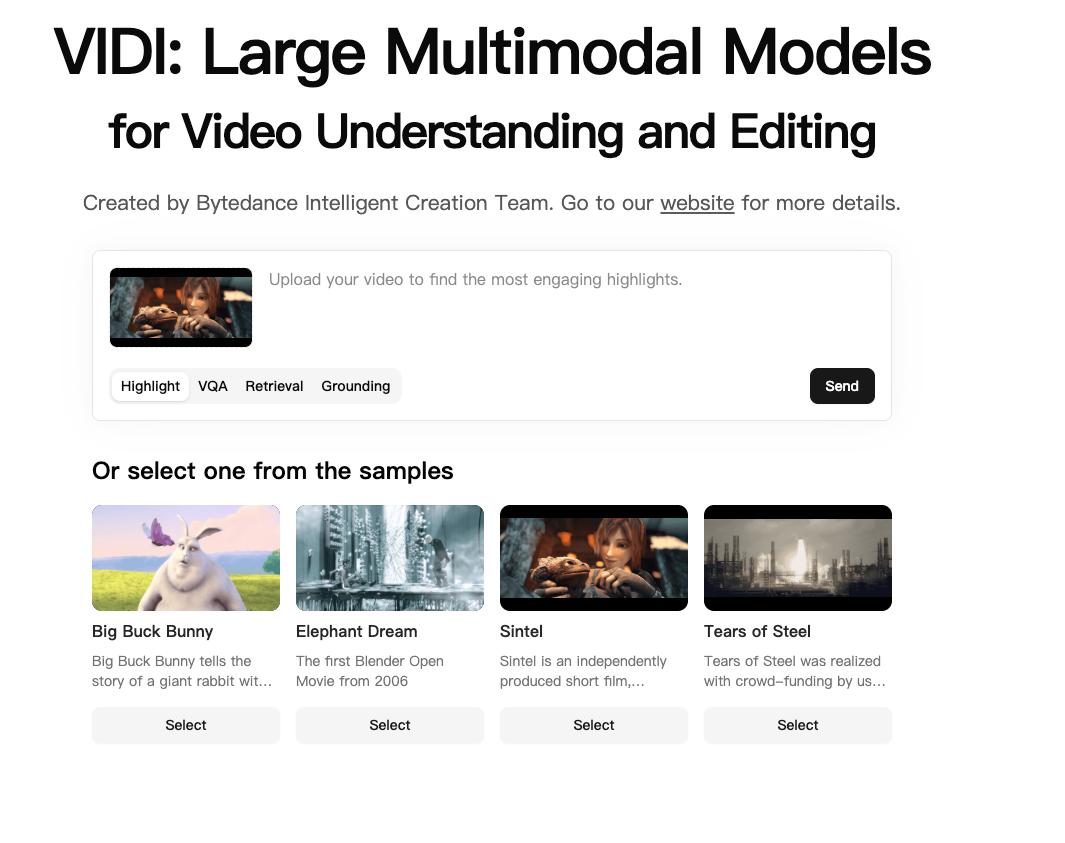
作为产品经理我一直会关注一些革命性技术,尤其是博士期间希望这些研究方案会成为工程化产品的技术壁垒,
技术几乎革命性的:改变了人们获取信息的方式
如果说现在微信公众号转图片消息或者生成视频已经是现在主流的内容创建形式,而如何将视频再反向转化为文本,这就大大提升了所有的内容信息流产生的效率,以及人类检索信息的能力翻倍。
以前我们总说一个人去了哪里,而现在是信息获取能力, 信息检索的能力将决定现在每个人的世界观,
这个模型将对信息产生的新媒体创作者与自媒体几乎就是革命了。
就像我现在获取信息的方式,几乎都是视频主流,在短视频与长视频成为信息主流的现在,看文字的人越来越少,作为人类,天然的更加喜欢更加快速、高频的模式,也就是懒人模式完成消费。
支持视频关键词搜索
在Vidi2里,可以做很多将其新媒体工具的翻译者,甚至是教学视频甚至是机器人 学习的匹配。将其视频的故事与步骤以文字的形式输出,再让大模型进行比对与记忆对应的视频中的动作,就可以更快的完成模型的收敛
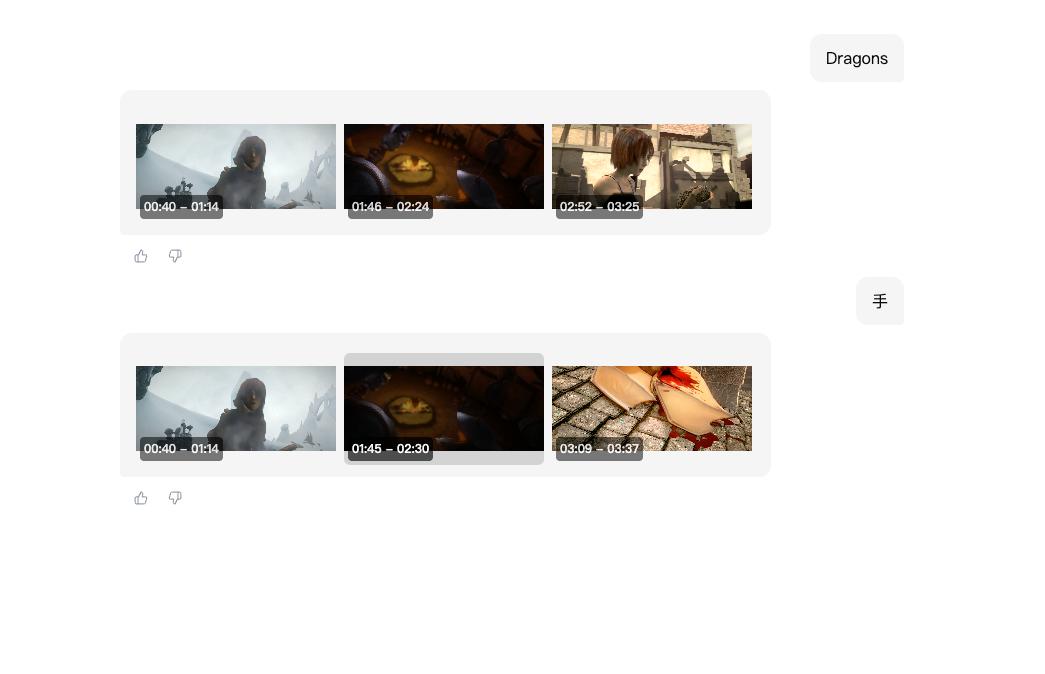
比如上面这个官方视频里,我搜索里面有龙的画面与帧数,都可以罗列出来,输入手的视频则可以把有手的视频也能够输出。
用户可以接受的效率:从文字搜索到搜索视频
在有了Vidi2这个底层技术之后,接下来就可以完成视频搜索,而不是再用标题来搜索了,一切视频的标题党将没有意义,那些有封面的视频,但是讲的是其他内容,就完全失效了。
一切还是以视频内容为核心,而视频内容里面的文字内容就是可以讲解的。试想一下现在互联网上如此多的内容,要想真的自己花时间去检索就需要去查看,尤其是查监控等情况,而现在有了这个技术就可任意在监控视频中检索,从而减少时间,快速定位其所需要的视频。
支持编辑视频元素
在Vidi2模型里, 不仅支持搜索,还能够支持编辑视频,用户可以对其搜索的对象进行替换,从而视频就成了其他画面
这像一个科幻电影来自范迪塞尔《喋血战士》,其科技公司利用视频编辑技术修改器记忆的空间视频的物体与人物甚至是对话,从而篡改主角的记忆,从而成为了一个杀人机器。
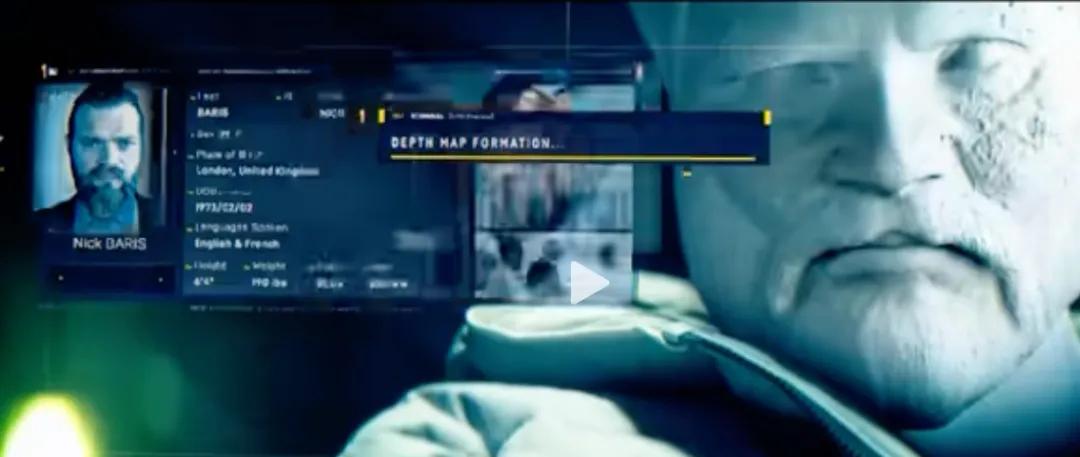
如上是电影中的记忆编辑画面,而记忆就是类似于空间智能,虽然现在VIDI2仅支持平面视频的,而不是空间视频,但已经足够现在的信息获取再翻倍了。现在的检索速度,几乎达到可用的水平,至少远超看一个短视频的效果,更不用说要把某一个长视频看完了。
以上就是Vidi2的新技术,希望产品经理可以关注。
今天的分享就在这里
