


新智元报道
编辑:Aeneas 好困
【新智元导读】GPT-5.2打赢Gemini 3.0 Pro,竟是靠高推理与海量Token「作弊」?网友的这个发现,在AI社区一石激起千层浪。更多网友七嘴八舌表示:GPT-5.2,并没有那么好用!
太戏剧了。
OpenAI昨天刚放出大杀器GPT-5.2,今天就被曝疑似虚假营销?
凌晨的科技圈,被一则爆料点燃——
一位用户通过精细计算发现了「华点」:OpenAI在最新发布的基准测试中,可能通过调整模型「推理力度」参数,让GPT-5.2在关键评测中使用了远超对手的算力资源。

一句话总结就是:在调整token使用后,GPT-5.2和Gemini 3 Pro在ARC AGI 2上的表现基本相当。
具体来说,问题就出在这几张图上。
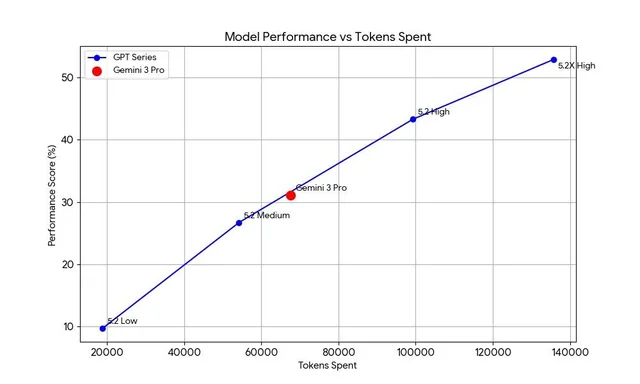
可以看到,OpenAI在基准测试中使用了额外的token,至少是Gemini 3.0 Pro的两倍。
这就像两个棋手对弈,一方被允许思考一个小时,另一方却只有十分钟,然后宣布前者获胜。
在这种情况下,结果还公平吗?

OpenAI胜过谷歌,其实靠作弊?
昨天的AI圈,都被GPT-5.2吊打Gemini 3.0 Pro的结论所震撼,而前者在ARC AGI 2的精彩表现,则尤为出圈,被AI社区大加赞赏。
但现在,这些结果很可能注了水?

比如在备受关注的ARC AGI 2测试中,GPT-5.2 xhigh版得分52.9%,每个任务消耗约13.5万个token。
按API定价计算,每个任务仅算力成本就高达1.9美元。
相比之下,谷歌Gemini 3.0 Pro以6.7万token取得相似成绩,效率高出整整一倍。
如果我们将算力投入标准化,就会发现两个模型的真实能力几乎并驾齐驱。
如果这一假设普遍成立,那么GPT 5.2在使用token数超过Gemini 3的两倍的情况下,仍然在HLE、MMMU-Pro、Video-MMMU和Frontier Math Tier 4中表现不佳。
在GPQA上,它们也才基本相当。而在Frontier Math Tier 3中,GPT 5.2 xhigh也就比Gemini 3 Pro高出2.7%的成绩。
唯一例外的是GDPVal——一个由OpenAI自己创建的测试集。既当裁判又当运动员,结果的客观性就有待考量了。
Ilya:我早说过了
其实,Ilya在之前的采访中就已经说过,现在的大模型基本都是为了榜单定向优化的,榜单结果的水分都大得很。
业内人士都知道,如今AI基准测试的「军备竞赛」早已超出单纯的技术竞争。各家厂商都在竞相推出自己的评测标准,而这些标准往往有意无意地偏向自家模型。
这么干的也绝不仅仅是OpenAI一家。
在谷歌推出的FACTS Benchmark中,Gemini 2.5 Pro超越GPT-5的结果,也同样得打个问号。
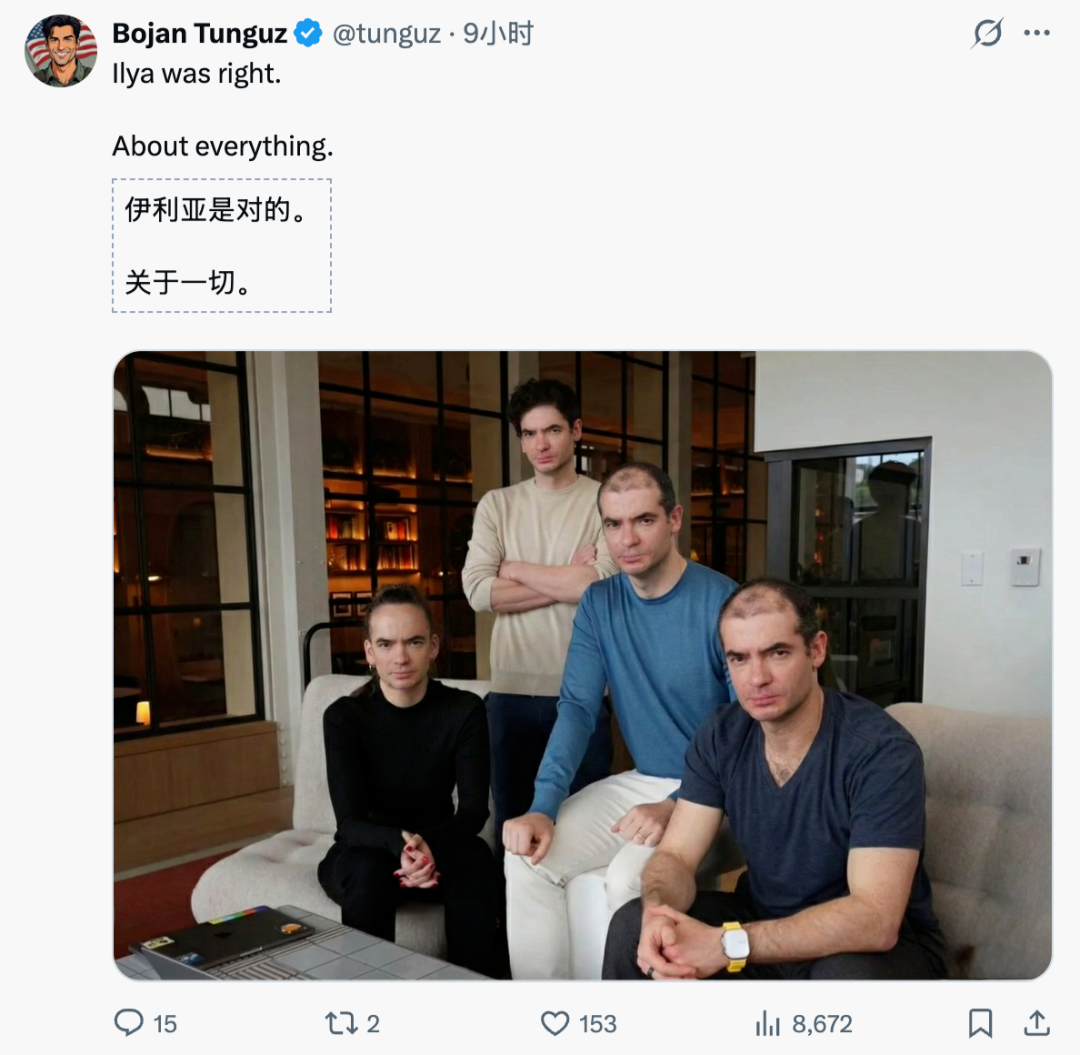
在SWE Bench(软件工程评测)中,情况就更加复杂了。
不同模型在不同编程任务上各有所长,但没有一个模型能在所有任务上全面领先。显然,真实世界的问题远比单一分数复杂。
所以,这次事件就反映出了AI评测的根本困境——
如果GPT-5.2仅仅是通过消耗更多算力获得了性能提升,那真的能智能进步吗?还是仅仅是「暴力计算」的胜利呢?
对于这次OpenAI的「虚假营销」,网友们也是议论纷纷。
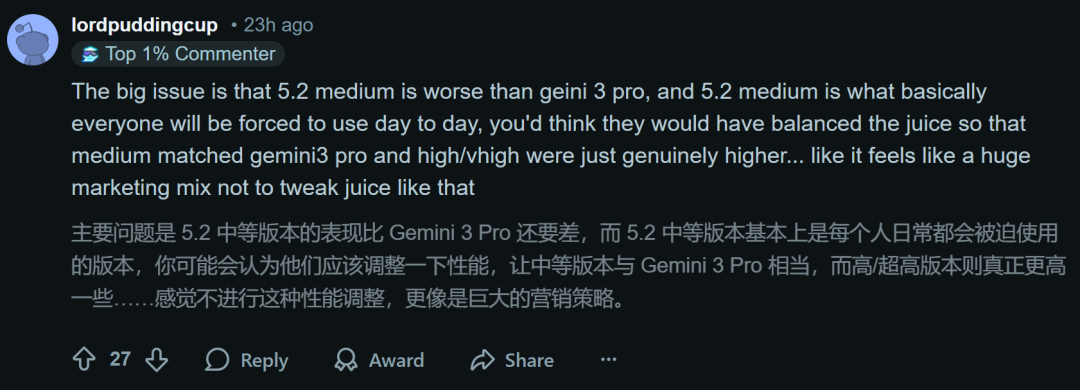
有人表示,如果用户得到的「推理力度」参数是一样的,也用的是同样的token,那OpenAI就不算虚假营销。
但如果测评的和用户使用的根本不是同样的版本,那就是欺骗了。

也有一些人是站在OpenAI这一边的。
他们觉得,即使增加Gemini 3的token数量,它也未必就能赶超GPT-5.2,这一点来说,前者的确落后了。
也有人说,既然模型的价格都是公开的,那就不构成欺骗。

巧了不是,紧接着我们就发现,「货不对板」这个问题的确有人提出来了。

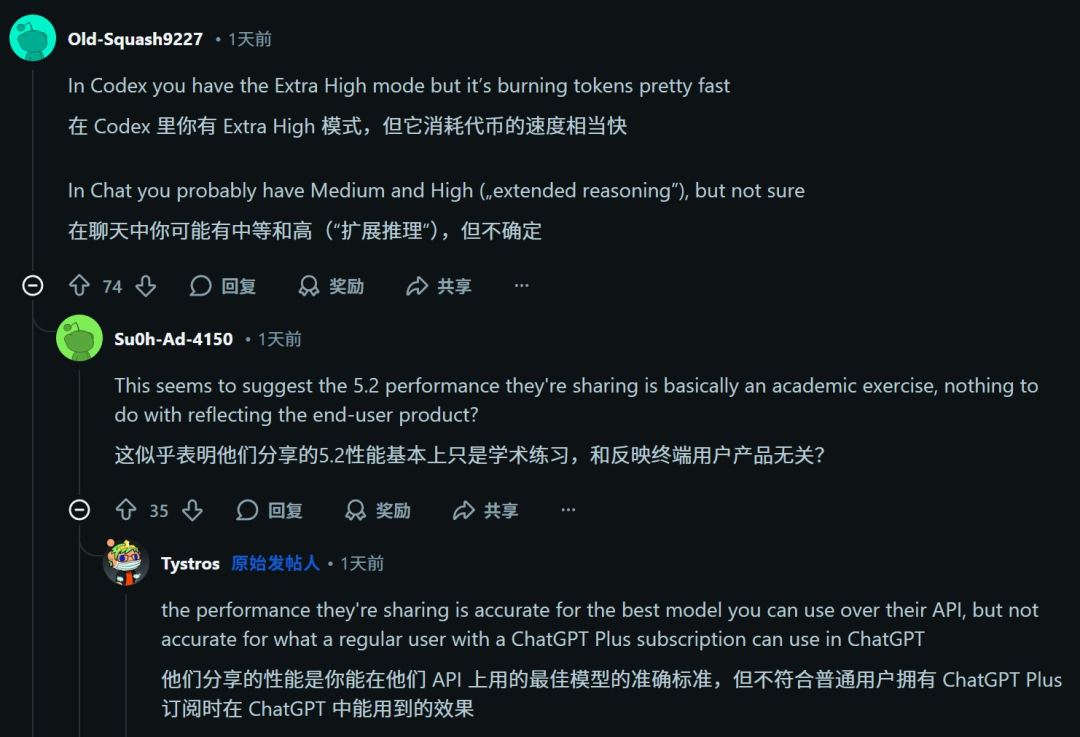
在社区的另一篇帖子中,也有人指出了OpenAI的作弊问题——
早在GPT-5.1发布时,所有基准测试中用的都是高推理力度(high),然而plus用户却只能使用中等的版本。
而现在的5.2版本中,OpenAI增加了更高的「xhigh」推理力度,所以基准测试中显示的性能,要远远超过ChatGPT付费用户的实际体验。

GPT-5.2的实际体验如何
不看榜单,我们就来看看用户的实际体验究竟如何。
一位网友发帖称,自己对GPT-5.2的第一印象并不是太好。

比如在检查代码时,它的幻觉现象非常严重。
网友本以为GPT-5.2会比5.1好得多,但实际用起来并非如此,它并不能理解他写的函数代码。

另一些网友反馈说,GPT-5.2似乎把成年人当学龄前儿童对待,感觉不像是升级,反而是倒退。

OpenAI的核心用户群体,仍然最想念GPT-4o。

总之,GPT-5.2的实际体验跟基准测试似乎相差很多,保不齐又是一个在红色警报状态下仓促拿出的产品。
被谷歌打得匆匆忙忙、连滚带爬的OpenAI变成今天这个样子,显然不是一朝一夕的事。
OpenAI,变了
毕竟,当一家机构既是「研究AI的人」,又是「靠AI卖故事的人」,它还能诚实地面对那些刺耳的真相吗?
根据Wired的最新调查,OpenAI内部正在经历一场关于「真话权」的剧烈地震。
在面对「AI是否会抢走你的饭碗」这类致命问题时,OpenAI的策略已悄然转变:闭上嘴,专心卖货。
这种为了商业利益而牺牲学术独立性的转向,直接「气跑」了自家的研究员。
「我们成了老板的喉舌」
回望2023年,OpenAI发布的重磅论文《GPTs Are GPTs》,直白地剖析了哪些行业最容易被AI颠覆,并在第二年登上了Science。
那时的他们,还敢于直视「技术性失业」的阴影。


论文地址:https://arxiv.org/abs/2303.10130
Science:https://www.science.org/doi/10.1126/science.adj0998
但到了今年9月,画风突变。
在新任首席经济学家Aaron Chatterji的带领下,OpenAI发布了一份名为《全球用户如何使用ChatGPT》的报告。
从学生写作业到职场人做表,报告事无巨细地描绘了AI的美好图景。
结论毫无悬念地一边倒:AI是生产力的引擎,是经济价值的创造者。
企业用户被引述称,ChatGPT每天能帮他们省下40到60分钟。

报告地址:https://www.nber.org/papers/w34255
对此,一位前员工吐槽道:「这简直是为『AI创造价值』这一命题量身定做的软广,充满了粉饰太平的味道。」
离职信里的「真相」
矛盾的爆发点,是报告作者之一、OpenAI经济研究骨干Tom Cunningham的离职。
过去一年,OpenAI对「负面研究」的审查愈发严苛。
那些探讨AI如何替代入门级白领(如客服、行政)的课题,要么被要求「软化措辞」,要么直接被束之高阁。
忍无可忍的Cunningham在Slack上留下了一封直白的告别信:
我们曾致力于严谨的学术研究,现在却沦为了公司的宣传部门。
他认为,团队不仅失去了研究AI负面影响的自由,反而被迫为公司「贴金」。

Cunningham并非个例。
前政策研究主管Miles Brundage离职时直言,公司「太高调、限制太多」,让他「无法发表真正重要的观点」。
超级对齐团队的William Saunders因不满公司「只顾推新产品、无视用户风险」而愤然出走。
前安全研究员Steven Adler更是公开炮轰ChatGPT可能诱发用户的「精神危机和妄想」。
价值一万亿美元的「沉默」
面对Cunningham的离职,OpenAI高层上演了一出教科书般的危机公关。
首席战略官Jason Kwon在备忘录中回应道:
既然是我们把AI推向了世界,我们就得负责构建解决方案,而不是光盯着问题看。
翻译一下就是:别再发论文论证AI会导致失业了,这不利于带货;多想想怎么夸我们的产品能提效吧。
OpenAI为什么要这么做?答案藏在账本里。

如今的OpenAI早已不是当年的非营利实验室,它正冲刺1万亿美元的惊人估值,并筹备着史上最大规模的IPO。
它拿了微软几百亿美元;
它需要芯片大佬们再投1000亿;
它承诺未来要付给微软2500亿美元买云服务。
在天文数字的利益面前,「诚实」成了最昂贵的奢侈品。
如果你正准备上市,正试图说服全世界拥抱AI,你绝不希望自家的研究员跳出来说:「嘿,根据数据,这波AI可能会让30%的白领失业。」
「岁月静好」的另一边
有趣的是,老对手Anthropic似乎拿到了完全相反的「剧本」。
他们的CEO Dario Amodei甚至公开「唱反调」,警告到2030年AI可能取代一半的入门级白领。
当然,这未必全是出于诚实——很多人解读,这不过是Anthropic为了换取监管红利而刻意贩卖的「焦虑」。
但回看OpenAI,情况更为微妙。
如今掌管其经济研究团队的,是前克林顿顾问、有着「灾难大师」之称的顶级危机公关专家——Chris Lehane。

在这个精心修订的新版本里,AI绝不可能是引发社会动荡的「怪物」,它只会是帮你「每天省下40分钟」的乖巧助手。
至于那些关于失业、动荡和泡沫的尴尬真相?
嘘,为了那1万亿的估值,请保持安静。
