

近年来,基于大语言模型(LLMs)的软件工程智能体发展迅速,但其训练数据和训练环境仍高度依赖人类知识和人工策划,本质上是在复现人类开发轨迹,难以自主发现新的问题结构与解决策略,这从根本上制约了智能体迈向超级智能的能力。
基于此,来自Meta、伊利诺伊大学厄巴纳-香槟分校的研究团队提出 Self-play SWE-RL(SSR),作为软件工程智能体训练范式的第一步。该方法对数据假设的要求极低,仅需访问包含源代码和已安装依赖项的沙盒化代码仓库,无需任何人工标注的问题或测试用例。
研究表明,智能体可以从真实世界的软件仓库中自主获取学习经验,有望催生在系统理解、解决全新问题以及从零开始自主创建软件等方面超越人类能力的超级智能系统。

论文链接:https://arxiv.org/pdf/2512.18552
Self-play SWE-RL 框架
SSR 的设计原则是减少对代码库先验知识的依赖,以提升方法的通用性与可扩展性。它不依赖于特定环境的预配置,智能体要通过与环境的交互,自主探索测试的运行方式并理解其结构。该极简输入设定使 SSR 几乎无需额外配置即可应用于不同代码库,显著降低了使用与迁移成本。
SSR 的核心是通过自博弈式的迭代循环,使智能体在不断生成与解决 Bug 的过程中实现自我提升。在 SSR 中,同一 LLM 策略被划分为两个协同演化的角色,分别是智能体 Bug 注入与智能体 Bug 求解,二者共享参数但承担不同任务。
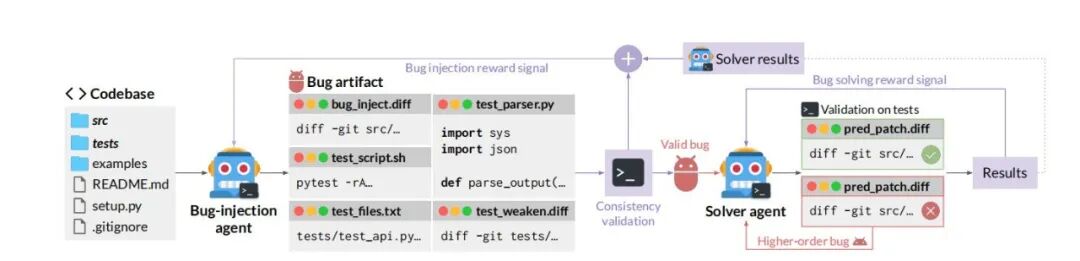
图| SSR 的总体框架
1.智能体 Bug 注入
智能体 Bug 注入通过让模型扮演“破坏者”构建起自驱动的进化闭环。
在这一过程中,首先生成包含 Bug 补丁和弱化测试的 Bug 构件,将抽象错误转化为标准化的练习题;随后,运用“删除关键代码”或“回滚历史修复”等复杂生成策略,从真实工程逻辑中制造出极具挑战的高质量难题;为了确保逻辑严密,系统利用“逆向变异测试”进行严格的一致性验证,剔除无关干扰并确保错误可复现;最后,通过动态奖励机制将任务难度维持在“跳一跳才够得着”的区间,并将修复失败的尝试转化为高阶缺陷循环利用,从而在无需人类标注的情况下,驱动智能体在博弈中不断实现自我超越。
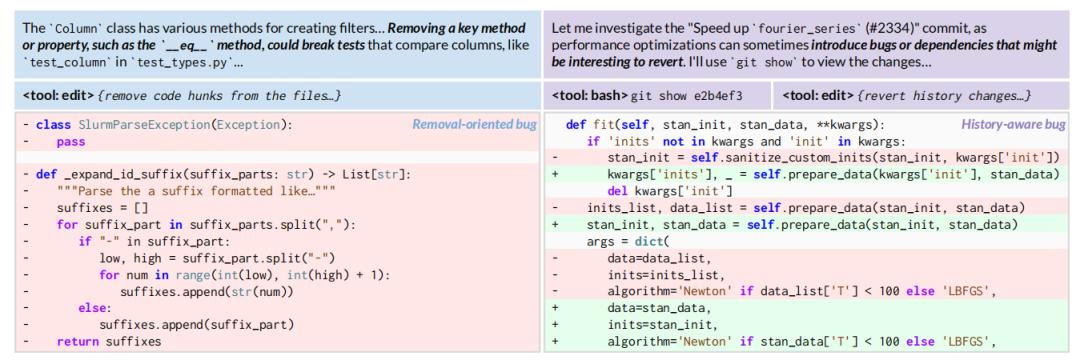
图| 智能体 Bug 注入中“删除关键代码”和“回滚历史修复”的策略
2.智能体 Bug 修复
智能体 Bug 修复通过在沙盒中应用缺陷补丁并重置 Git 历史来构建防作弊的代码现场,确保模型无法走捷径。随后,以弱化测试的逆向补丁作为任务提示,取代人类的文字描述,迫使代理纯粹基于代码逻辑定位问题。在修复过程中,智能体通过“推理与工具调用”的交互循环,在模拟环境中自主进行补丁尝试与验证。最终,系统通过回滚原始测试文件的评估机制进行严苛复核,确保生成的 Bug 在真实测试下依然有效,从而完成从理解考题到提交正确答案的闭环。

图| 智能体 Bug 修复的流程
实验结果
研究人员在 SWE-bench Verified 与 SWE-bench Pro 上,对基础模型、基线强化学习方法以及 SSR 进行了系统比较。
实验结果表明,即使在完全不接触任务描述和测试数据的情况下,SSR 仍能在训练过程中持续实现性能提升,验证了 LLM 仅通过与真实代码库交互即可增强其软件工程能力。更重要的是,SSR 在整个训练轨迹上始终优于基线 RL,说明由模型自主生成的任务相比人工构造的数据,能够提供更具信息量和有效性的学习信号。
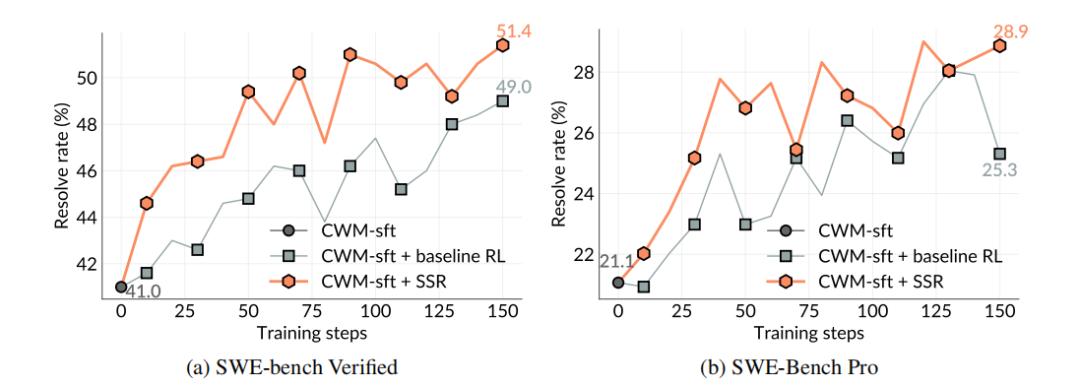
图| 训练过程中的基线比较
研究人员比较了完整的 SSR 与仅进行 Bug 注入或仅进行 Bug 修复的两种变体。
实验结果表明,完整的自博弈框架性能最优,而单一注入或修复训练均表现不足,前者缺乏从修复过程中的学习,后者受限于静态任务分布。相比之下,自博弈通过同时生成与修复 Bug,使任务分布随训练动态演化,持续提供更丰富的学习信号,从而实现稳定的性能提升。
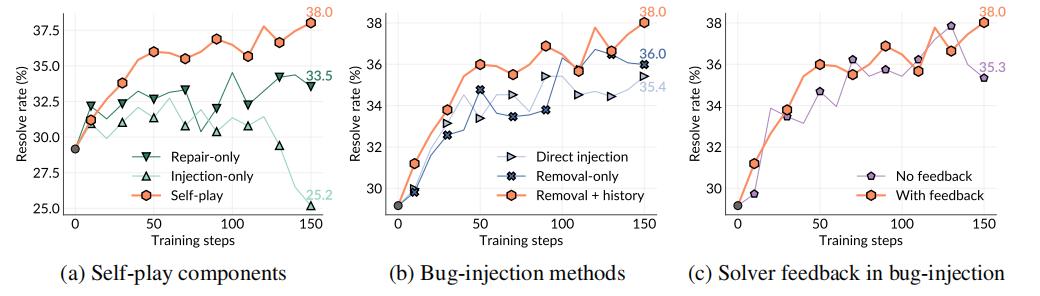
图| Self-play Swe-RL的消融研究
不足与未来展望
尽管 SSR 在减少人工依赖、实现自我提升方面展现出潜力,但仍处于早期阶段。当前方法依赖显式测试作为判定器,存在奖励投机的潜在风险。同时,验证机制主要基于单元测试,难以覆盖真实软件工程中的高层目标与复杂语义。此外,Bug 注入与修复角色共享同一模型配置,尚未系统探索模型规模、结构差异及角色分离对自博弈学习的影响。
此外,研究人员还探索了若干未取得理想效果的方向,例如,自然语言 issue 生成受限于模型能力与奖励设计,难以保证质量与多样性;仓库专用训练因数据多样性不足未能带来收益;而训练不稳定性则成为限制 SSR 进一步扩展的重要瓶颈。
展望未来,SSR 为自博弈驱动的软件工程智能体打开了多个研究方向,包括通过种子机制控制错误分布、合成更复杂的多步软件任务,以及设计适用于长周期软件开发的高效训练范式。尤其是在奖励稀疏、决策链条极长的真实工程场景中,如何引入更密集、结构化的反馈,将是释放自博弈潜力、迈向更高层次智能的关键。
