

想象一下,如果让一个大厨用发霉的食材、过期的调料来做菜,即使厨艺再高超,也做不出美味佳肴。AI训练也是同样的道理。
一、数据就像食材,质量决定成品
现在的AI图像生成模型,如Stable Diffusion、FLUX等,需要从网络上爬取数百万张图片来学习。但这些图片质量参差不齐:有些模糊不清,有些内容重复,有些甚至只是广告背景图。用这些“食材”训练出来的AI,自然效果不佳。
由香港大学丁凯欣领导,联合华南理工大学周洋以及快手科技Kling团队共同完成的这项研究,开发出了一个名为“炼金师”(Alchemist)的AI系统。它就像一位挑剔的大厨,能从海量图片数据中精准挑选出最有价值的一半。
更让人惊喜的是:
- 用这一半精选数据训练出的模型,竟然比用全部数据训练的表现还要好
- 训练速度快了 5倍
- 只用20%的精选数据,就能达到50%随机数据的效果
二、让AI学会“自我评判”
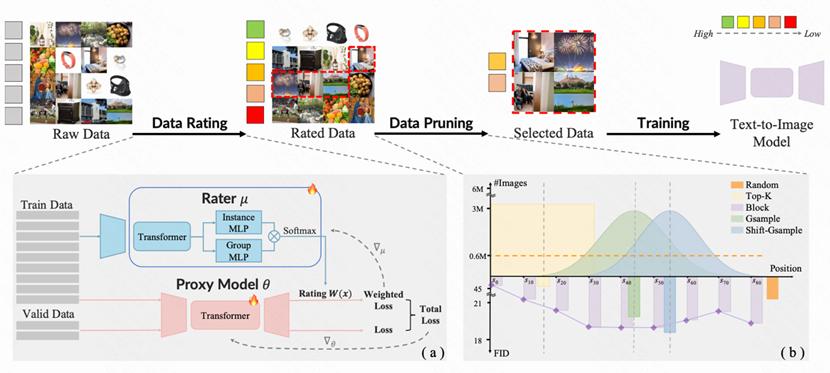
2.1 传统方法的局限
传统的数据筛选方法就像用筛子筛米粒,只能按照单一标准过滤:
- 只看图片清晰度
- 只看文字匹配度
- 只看美学评分
这些方法的问题在于:它们不知道哪些数据真正有助于AI学习。
2.2 炼金师的智慧
“炼金师”更像是一位经验丰富的美食评委,它能同时考虑多个维度:
- 不仅看“菜品”的卖相
- 还要品尝口感
- 甚至考虑营养搭配
核心思想:让AI学会观察自己的学习过程
炼金师训练了一个专门的评分员模型,这个评分员就像资深的艺术老师,能够判断每张图片对整个学习过程的价值。
评判标准:
✅如果一张图片能让AI模型学到新知识并快速改进→好数据
❌如果一张图片让模型学了半天也没什么进步→无用数据
这就像观察学生做习题时的表情和进步速度,来判断这道题是否适合他们。
三、最简单的不一定最好
3.1 意外的真相
研究团队发现了一个违反直觉的现象:
那些看起来最“简单”的图片,比如纯白背景的产品图:
- 虽然能让AI快速收敛
- 但对提升模型能力帮助不大
- 就像一直做最简单的加法题,虽然不会出错,但对提升数学能力没有帮助
相反,内容丰富、稍有挑战性的图片,才是真正的“营养品”
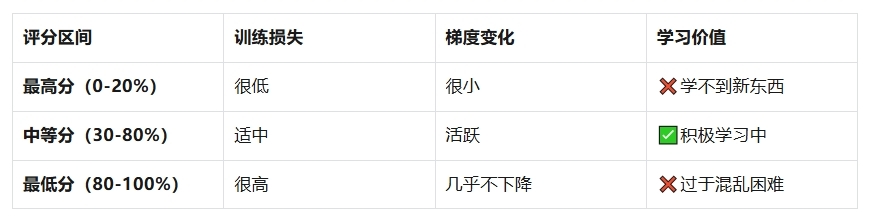
3.2 科学验证
研究团队追踪了不同评分区间图片的训练动态:
四、技术亮点:偏移高斯采样策略
基于上述发现,团队提出了“偏移高斯采样”(Shift-Gsample)策略。
4.1 传统方法vs炼金师
传统Top-K方法:
- 简单选择评分最高的数据
- ❌但这些数据往往过于简单,缺乏营养
炼金师策略:
- ✅避开评分过高的“简单”数据
- ✅重点选择中等偏上评分的“有营养”数据
- ✅保留少量简单和困难样本,维持数据多样性
这就像制定健身计划:
- ❌不选择过于轻松的运动 (没有锻炼效果)
- ❌不选择过于困难的运动 (容易受伤)
4.2 多粒度感知机制
为了更好地评估数据质量,炼金师还设计了“多粒度感知”机制:
- 个体层面:评估单张图片的质量
- 群体层面:考虑整批数据的搭配
就像营养师不仅关注单个食材的营养价值,还要考虑整餐的营养搭配。
五、实验结果:数据说话
5.1 主要成果对比
在LAION-30M数据集上:
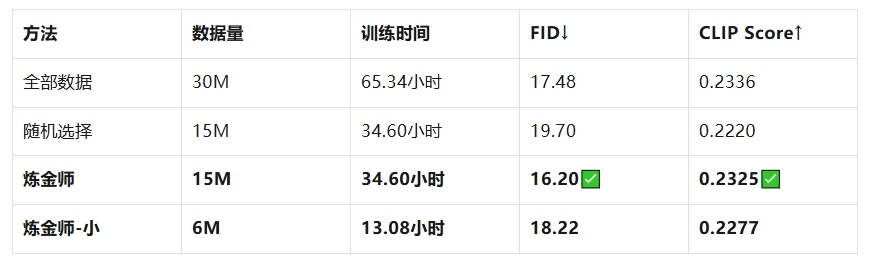
关键发现:
- 用50%精选数据超越100%全量数据
- 用20%精选数据达到50%随机数据效果
- 训练速度提升 5倍
5.2 跨模型通用性
炼金师在不同规模、不同架构的模型上都有效:
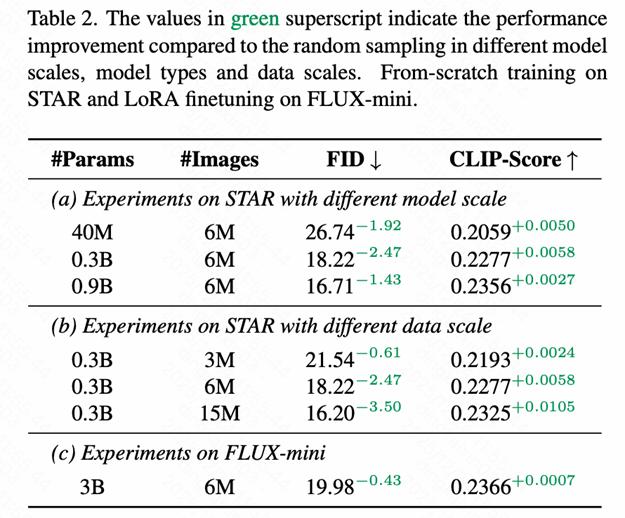
5.3 跨数据集适应性
在不同类型数据集上的表现:
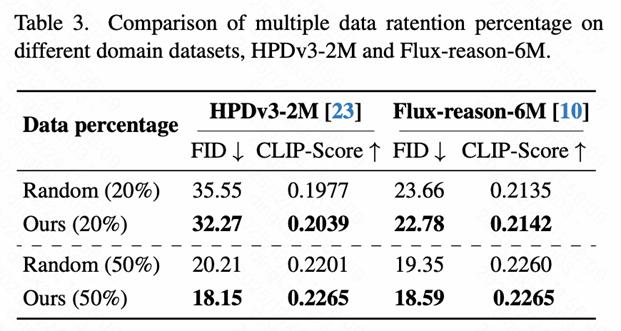
HPDv3-2M数据集(真实+合成混合):
- 20%保留率:FID从35.55→ 32.27 ✅
- 50%保留率:FID从20.21→ 18.15 ✅
Flux-reason-6M数据集(纯合成推理数据):
- 20%保留率:FID从23.66→ 22.78 ✅
- 50%保留率:FID从19.35→ 18.59 ✅
六、可视化分析:眼见为实
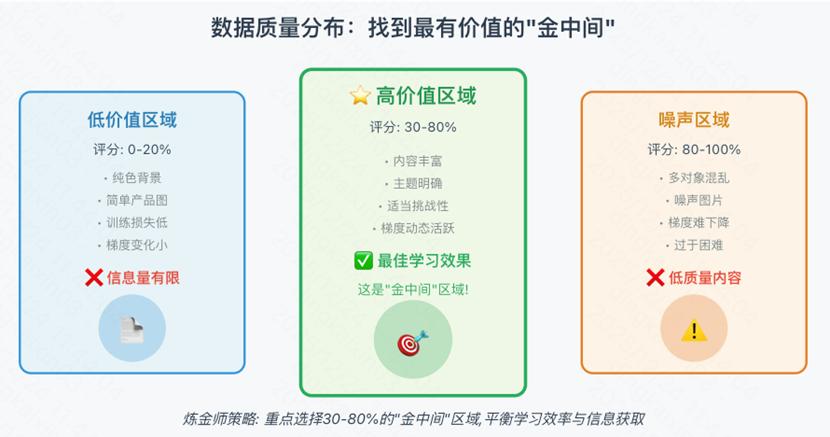
6.1 数据分布特征
研究团队对筛选后的数据进行了可视化分析:

0-20%高分区域(简单但营养不足):
- 白色或纯色背景
- 简洁的产品图
- 视觉干净但信息量有限
30-80%中分区域(最有价值的“金中间”):
- 内容丰富
- 主题明确
- 动作清晰
- 炼金师重点选择区域⭐
80-100%低分区域(过于混乱):
- 噪声图片
- 多对象混乱场景
- 视觉密集区域
- 内容不清晰
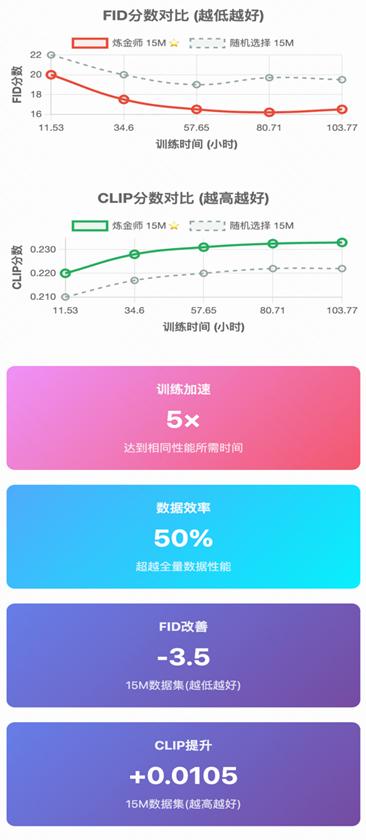
6.2 训练动态对比
训练稳定性对比:
炼金师选择的数据展现出:
✅稳定持续的性能提升
✅更快的收敛速度
✅更少的训练波动
随机选择的数据则表现出:
❌早期训练波动大
❌性能提升缓慢
❌需要更多epochs才能收敛
七、技术深度:元梯度优化框架
7.1 双层优化问题
炼金师的核心是一个双层优化框架
外层优化:学习如何评分
- 目标:找到最优的评分策略
- 评判标准:验证集上的性能
内层优化:训练代理模型
- 目标:用加权数据训练模型
- 权重由评分器决定
7.2 元梯度更新机制
- 系统通过观察两个模型的表现差异来更新评分:
- 评分更新∝代理模型的验证集损失
核心思想:
如果一个样本让验证性能提升→提高其评分
如果一个样本只降低训练损失但不提升验证性能→降低其评分
八、Q&A环节
Q1:炼金师如何判断哪些图片数据更有价值?
A:炼金师通过观察AI模型在学习过程中的“反应”来判断数据价值:
✅好数据:能让模型学到新知识并快速改进
❌差数据:让模型学了半天也没进步
这就像观察学生做题时的表情和进步速度,来判断题目是否合适。
技术细节:
- 监控训练损失变化
- 追踪梯度动态
- 对比验证集性能提升
Q2: 为什么用一半数据训练出的模型比用全部数据还要好?
A:因为并非所有数据都有价值,关键在于质量而非数量。
类比说明:
- 教孩子画画时,精选5000张优质作品
- 比给他看10000张杂乱涂鸦更有效
科学原理:
1.冗余数据消耗资源但不提升性能:如重复的简单样本、模糊不清的噪声图片
2. 有营养的数据促进真实学习:如内容丰富的中等难度样本、多样化的场景和对象
3. 避免过拟合:若只用简单数据会导致模型“死记硬背”,还应使用适当难度的数据培养泛化能力
Q3: 炼金师的数据筛选方法能在其他AI模型上使用吗?
A:可以!研究显示这种方法具有良好的通用性和跨模型适用性。
验证范围:
✅不同数据类型:
- 网络爬取数据 (LAION)
- 高质量合成数据 (Flux-reason)
- 人类偏好标注数据 (HPDv3)
✅不同模型架构:
- STAR系列 (40M→0.9B参数)
- FLUX系列 (3B参数)
- 从头训练 vs LoRA微调
✅不同模型规模:
- 用小模型 (0.3B) 筛选数据
- 成功提升大模型 (0.9B) 性能
- 评分成本可忽略不计
原理:
数据质量是本质属性,不依赖特定模型
就像好食材适合各种烹饪方法
经验丰富的教练选择的训练方法,既适合业余选手也适合专业选手
Project Page:https://kxding.github.io/project/Alchemist/
Github:https://github.com/KlingTeam/Alchemist/
arXiv:https://arxiv.org/abs/2512.16905
