

上个月你刚花 20 美元订阅了 ChatGPT Plus,转头这个月朋友圈就被「Claude 秒杀一切」刷屏,再过一个月可能又换成「Gemini 吊打一切」。
看着每月的账单,你难免开始怀疑人生:这 AI 会员,开不完,真的开不完?
这并非你的错觉,知名大模型竞技场 LMArena.ai 分析了自 2023 年年中以来的模型排名榜单,撕开大模型行业最残酷的一面:
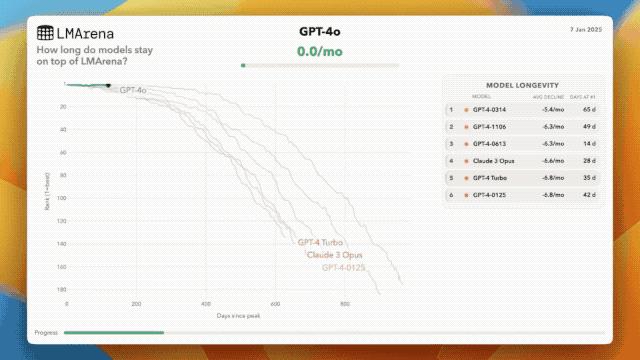
排名第一的模型平均只能保持约 35 天的领先地位,通常情况下会在 5 个月内跌出前五名,在 7 个月内跌出前十名。
而曾经一战封神的榜首模型 OpenAI o1 目前排在第 56 位,Claude 3 Opus 更是跌到了第 139 位。
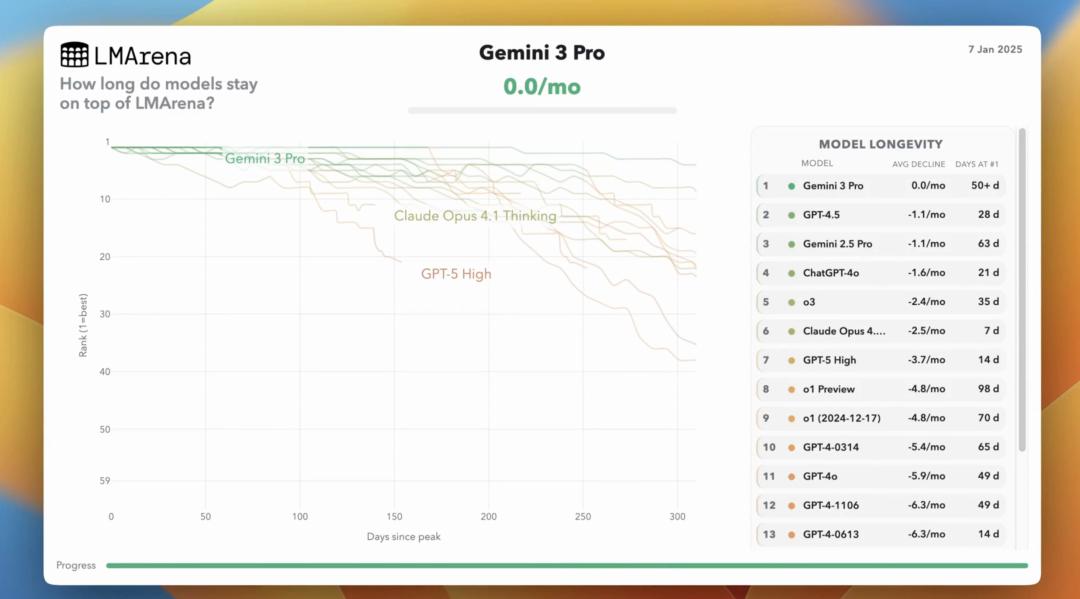
虽然 LMArena.ai 的这份榜单本身可能存在注水空间,但这种剧烈洗牌依然反映了 AI 模型过气速度之快,35 天正在成为顶级 AI 模型的「斩杀线」。
亿级投流,换不来 AI 用户的「回头率」
过去两年,你一定有看到过互联网上流传的这张梗图。
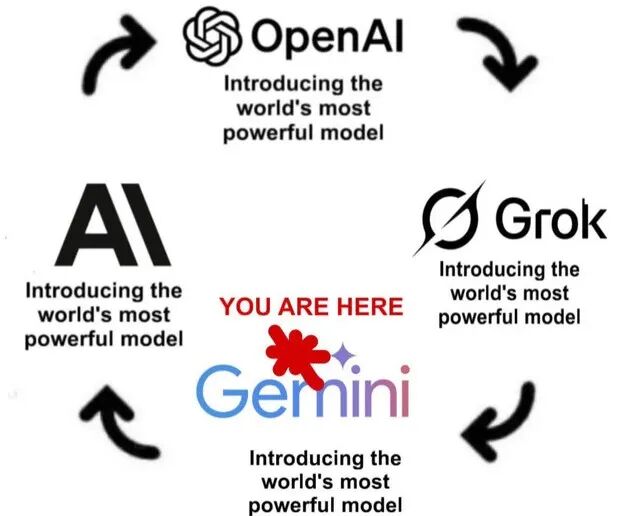
去年年初还是 ChatGPT 独领风骚,随后 DeepSeek、Claude 轮番坐庄,如今 Gemini 又异军突起。无论 2025 还是 2026 年,影响用户选择模型最核心的因素依旧是性能至上。
用户的选择从来纯粹,哪款模型好用、顺手,便会坚定不移地投向其怀抱,不得不承认的是,现在的 AI 用户,从一开始就没有忠诚可言。
比如 Sora 2 刚发布时被吹捧为短视频的降维打击,5 天内下载量破百万,但 a16z 合伙人 Olivia Moore 抛出的数据却显示,用户的 30 天留存率仅 1%,60 天直接归零。
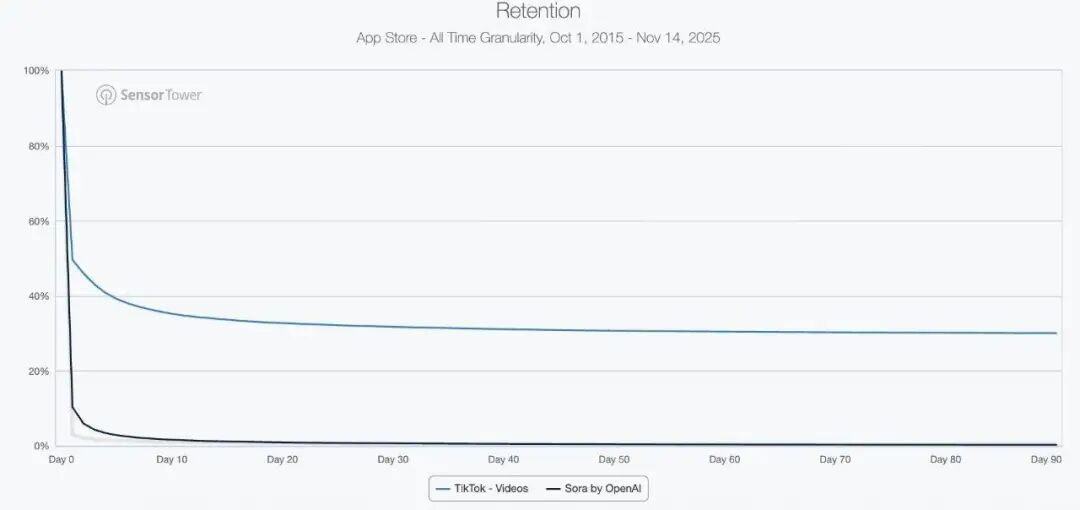
如果把视野转回国内,大模型战火叙事同样残酷:AI 应用月投流规模动辄千万甚至十亿级,但除了尝到初期的流量甜头,用户留存率同样惨不忍睹。
而这种「始乱终弃」的现象绕不开因 AI 热潮催生的「FOMO」心理——大量所谓的 AI 游客只是为了跟上潮流、探索新鲜工具,但在体验过后转身离开。
深究根源,多数 AI 产品至今未能搭建起留住用户的闭环。
在过去的 SaaS 行业,「因 X 而来,因 Y 而留」是奉为圭臬的增长逻辑。就像有人最初用 Canva 做社交海报,但后来却被品牌素材包、模板库和团队协作功能绑住,成为长期用户。亦或者很多人第一次点开微信视频号,就是因为朋友圈、群聊里的一次顺手转发。
内容本身未必惊艳,但它被包裹在熟人关系之中。你可以不关心视频讲了什么,但很难对谁转了这条、谁在下面留言视而不见。点赞除了给创作者,也是为了维持关系的连接。
但这套逻辑在多数 AI 产品身上彻底失灵。

最典型的就是 Sora 2,即便能生成真假难辨的视频,但若没有原生社区支撑用户分享、互动、收获反馈,它终究只是个孤立工具——没除了极少数专业人士,大多数普通用户往往缺乏长期使用的需求。
除此之外,重度用户的使用逻辑也在发生变化。
英伟达 CEO 黄仁勋就曾在公开场合分享自己的 AI 使用秘籍:从不依赖单一模型,而是将同一个问题同时抛给多个 AI,让它们互相参考、交叉验证,以此提升回答质量与可信度。

这背后的逻辑不难理解:当下没有哪个模型能赢家通吃,不同模型各有优势。时至今日,ChatGPT 已不再是 AI 唯一入口,用 Claude 写长文本、Gemini 写代码、多模型协作取长补短才是常态。
尤为关键的是,巨头们早已手握成熟的生态闭环,只需将 AI 能力无缝嵌入其中,便能坐享生态红利。
Google 手握一整套已经被验证过二十年的入口体系,能够将 Gemini 能够无缝嵌入 YouTube、Workspace 办公套件,更深度绑定 Chrome、地图等核心流量入口,同时开放 API 拉拢海量开发者。

这种润物细无声的渠道分发,能够让 Gemini 轻松收割海量的普通用户与企业客户,也让 ChatGPT 用户反复摇摆。
面对用户使用意图薄弱、迁移成本近乎为零的困境,OpenAI 为代表的初创厂商一方面不断加筑功能防线:绑定生态厂商合作,推出 AI Office、AI 浏览器、AI 群聊等产品。

用 Sam Altman 的话说,这是为了发挥 AI 最大生产力,一切都值得用 AI 重做一遍,但换个角度看,这也是入口焦虑下的被动选择。
另一方面,OpenAI 也在 C 端加码押注「个性化记忆」与情商——允许用户让模型跨会话记住写作风格、专业术语等偏好,还能手动编辑记忆库;针对心理咨询等场景优化语气,本质上就是希望通过个性化功能和「情感绑定」来抬高用户迁移门槛。
但这些煞费苦心的防御招式,短时间终究还是难以逆转用户流失的大趋势。当产品端的突破变得举步维艰,于是也有许多厂商将目光投向了更「省时省力」的赛道——在衡量行业性能地位的榜单上动起了歪脑筋。
「我可以随时换,我也应该随时换」
前文提到的 35 天斩杀线,核心是参考 LMArena 反映的行业趋势,但需要指出的是,即便是这份被视作相对权威的评测榜单,本身也暗藏不少猫腻。
Meta 此前被曝出的刷榜行为,直接扯下了这份权威榜单的遮羞布。
发布 Llama 4 前,Meta 私下测试了 27 个变体版本,却只将分数最高的」特供版「公之于众,靠着这套玩法,Llama 4 一度霸榜。但当面向公众的正式版发布后,排名瞬间从第 2 名暴跌至第 32 名,滤镜破碎一览无余。
榜单的评测机制本身也存在不少问题,其理论上是这么运作的:用户输入提示,比较两个 AI 回应,然后选出更好的一个。实际情况却是:随机网民匆匆扫一眼,用两秒钟点击他们感觉还不错的选项。
Surge AI 在《LMArena is a cancer on AI》一文中曾指出,竞技场中 52% 的对决判定存在错误,大众投票更偏爱回答冗长、排版华丽甚至带表情包的「显眼包」。
很多时候,AI 只要自信地胡说八道,就能轻松击败诚实却枯燥的对手。
当刷榜作弊成为 AI 行业的潜规则,用户对模型的信任也在不断被透支。再加上模型们隔三差五出现的「降智」更新,用户对「榜一大哥」的祛魅,显然也只是时间问题。

而开源与低价的崛起,则进一步冲击了行业格局。
微软基于内部数据的研究显示,DeepSeek R1 极大推动了全球大多数地区的 AI 普及,在白俄罗斯拿下 56% 的份额,古巴 49%、俄罗斯 43%,即便是埃塞俄比亚和津巴布韦,份额也分别达到 18% 和 17%。
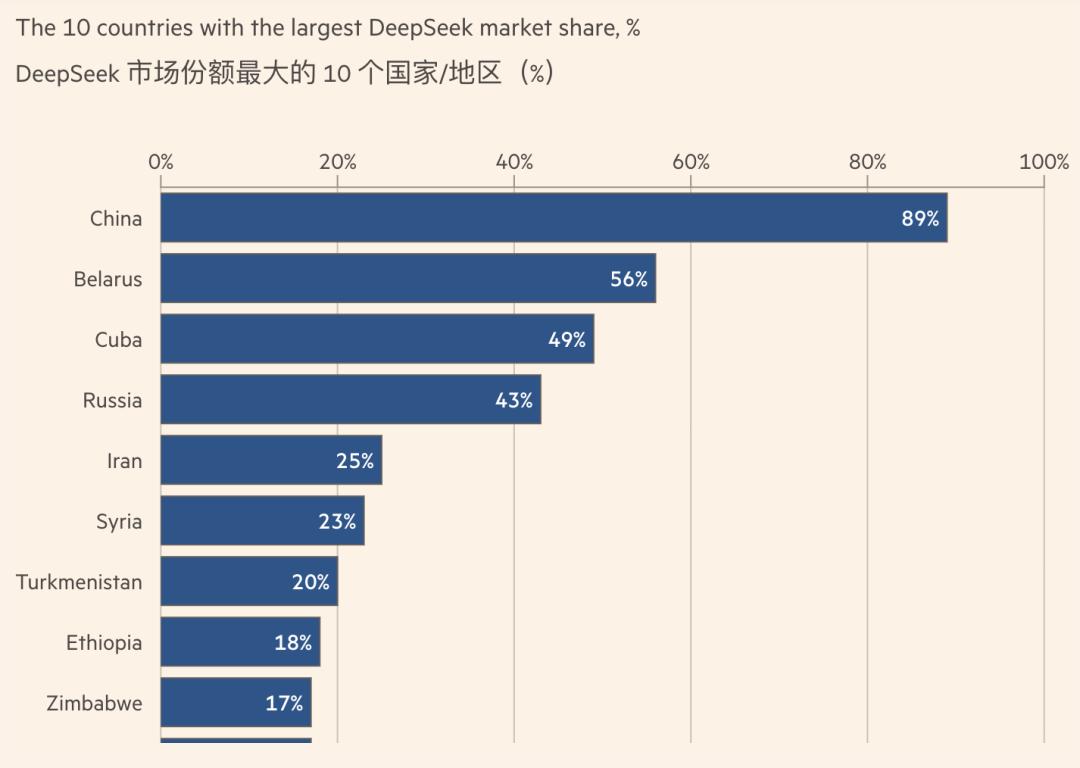
图片来自金融时报
原因并不复杂,甚至可以说相当朴素:价格屠夫。
对于绝大多数人来说,免费模型已经覆盖了大多数日常需求,用户就会很自然地进入另一种心态:我可以随时换,我也应该随时换。对于开发者而言,即便 OpenAI 等巨头多次大幅降价,其每 Token 收费依旧遥遥领先于 DeepSeek。
此外,开发者还基于 Qwen、DeepSeek 等开源模型,针对教育、医疗等细分场景做轻量化微调,诞生了一批「小而美」的垂直模型。它们虽在通用榜单分数不高,但特定场景表现远超闭源巨头,进一步瓦解了头部模型的话语权。
在这样的背景下,那些卡在中间地带的 AI 玩家反而最为尴尬:既不够强,也不够便宜,却还寄希望于刷榜、讲故事维持存在感。在「35 天生死线」面前,他们几乎没有回旋空间。
等待他们的结局,便只有迟早被斩杀。
