

Attention真的可靠吗?
近年来,Vision-Language Models(VLMs)在多模态理解任务中取得了显著进展,尤其是在视觉问答、图像理解和视频理解等场景中,模型通常通过language-to-vision attention来衡量视觉token与文本之间的相关性,并据此进行visual token pruning,以降低推理成本、提升运行效率。
然而,一个长期被忽视的问题是:attention本身是否真的能够作为“语义重要性”的可靠指标?
在最新研究中,上海大学曾丹团队系统分析了主流VLM中attention的行为模式,发现一个关键却容易被忽略的现象——attention并非只由语义决定,而是受到显著的结构性偏置影响。如果直接使用这些带偏置的attention进行visual token pruning,往往会在无意中保留不重要的视觉区域,同时丢失真正有助于任务理解的关键信息。

Attention的两个核心偏置来源
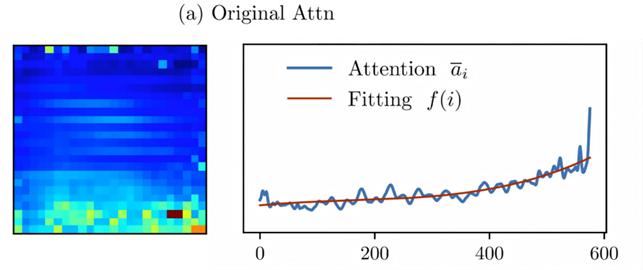
1. 位置偏置(Recency Bias):attention更偏爱“后面的token”
通过对大量样本的统计分析,该团队发现语言到视觉的attention随着visual token在序列中的位置不断增大,呈现出明显的单调上升趋势,这意味着模型更倾向于关注序列靠后的视觉token。
在图像中,这一现象往往表现为模型对图像下方区域给予更高的attention,而这种偏好与图像语义本身并没有直接关系,如相关可视化结果中曲线所示。
更为严重的是,当attention被用于visual token pruning时,这种位置偏置会被进一步放大,从而导致剪枝结果系统性地保留“位置靠后但语义无关”的视觉token。
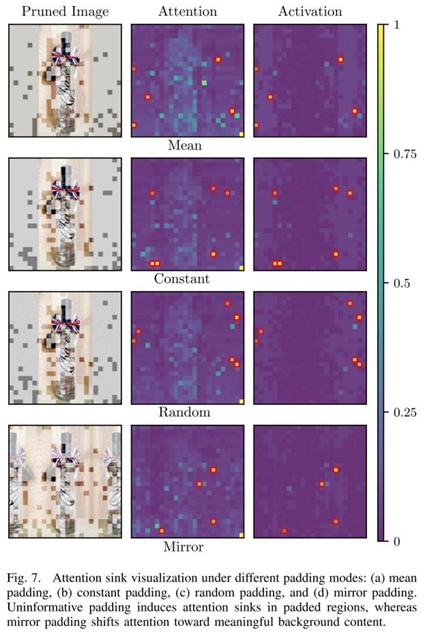
2. Padding Attention Sink:空白区域为何获得高attention?
除了位置偏置之外,该团队还观察到另一类更隐蔽的问题:padding区域的attention异常偏高。在许多VLM中,由于输入图像尺寸不一致,padding是不可避免的操作,但这些区域在语义上并不包含任何有用信息。
尽管如此,研究发现padding对应的视觉token在attention计算中经常获得异常大的权重,其根源在于hidden state中出现了极端激活值,从而诱发了所谓的attention sink现象。这会直接误导基于attention的pruning策略,使模型错误地保留空白区域。
核心思路:对Attention本身进行Debiasing
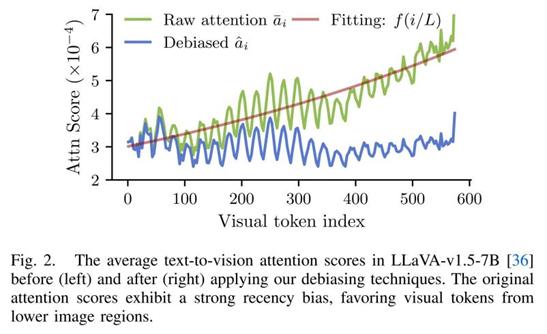
针对上述问题,上海大学曾丹团队并没有提出新的pruning方法,也没有引入额外的训练过程,而是从一个更基础的角度出发:既然attention本身是有偏的,是否可以先对attention进行修正?
该团队的核心观察是,attention中的偏置并非随机噪声,而是呈现出稳定、可建模的整体趋势。因此,研究人员通过对attention随token位置变化的整体趋势进行拟合,显式建模其中的位置偏置,并在此基础上对原始attention进行去偏修正,从而有效削弱与内容无关的位置因素,使attention更加接近真实的语义相关性。
与此同时,对于padding区域,该团队在pruning阶段显式抑制其attention贡献,避免attention sink对token排序产生干扰。整个过程不涉及模型结构修改,也不需要重新训练,可在推理阶段直接使用。
实验结果
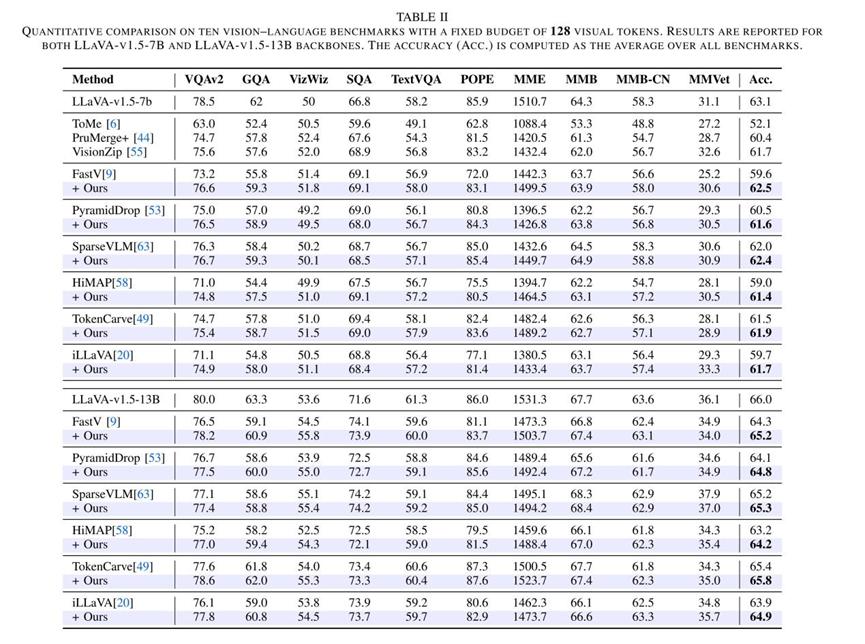
在系统实验中,该团队将attention去偏策略作为plug-and-play模块,集成到多种主流attention-based visual token pruning方法中进行评估。实验覆盖6种pruning baselines,在 多个主流VLM(7B/13B)上进行测试,并验证于10个图像理解任务与3个视频理解任务。
实验结果表明,在几乎所有设置下,经过attention去偏修正后,剪枝模型均取得了稳定的性能提升,且在更激进的token压缩条件下效果尤为明显。

结论
研究结果表明,attention并非天然等价于语义重要性。在Vision-Language Models中,如果忽视attention中固有的结构性偏置,基于attention的剪枝策略很容易被误导,从而影响模型整体性能。
通过对attention进行简单而有效的去偏修正,上海大学曾丹团队在不引入额外训练成本的前提下,显著提升了visual token pruning的可靠性与泛化能力。该工作为多模态模型的高效部署提供了新的视角,也为后续更稳健的attention机制设计奠定了基础。
文章链接:https://arxiv.org/abs/2508.17807
文章代码:https://github.com/intcomp/attention-bias
作者:上海大学、南开大学Kai Zhao¹,Wubang Yuan¹,Yuchen Lin¹,Liting Ruan¹,Xiaofeng Lu¹,Deng-Ping Fan²,Ming-Ming Cheng²,Dan Zeng¹¹上海大学 通信与信息工程学院/计算机工程与科学学院,²南开大学 计算机学院
