

为什么让多模态大模型“一步一步思考”(”Let’s think step by step”)来回答视频问题,效果有时甚至还不如让它“直接回答”?
在数学推理任务中,强化学习(RL)能通过“思考”大幅提升模型性能。但将同样的方法用于视频推理,效果却不尽如人意。
来自阿里巴巴未来生活实验室的研究团队认为,这背后是任务性质的根本差异:数学推理是纯文本空间的逻辑游戏,而视频推理需要模型在视觉内容和文本逻辑之间反复穿梭、验证。简单地套用文本思维链,只会让模型产生更多“脑补”和幻觉。
为了解决这一难题,研究团队提出了一个核心观点:模型“思考”的效果,取决于我们是否教会了它“如何思考”。基于此,他们推出了一整套解决方案:一个高质量的视频推理数据集ReWatch,以及一个能像人类一样“回看”视频进行思考的SOTA模型ReWatch-R1,论文已中稿ICLR 2026。
工欲善其事,必先利其器:高质量视频推理数据集ReWatch
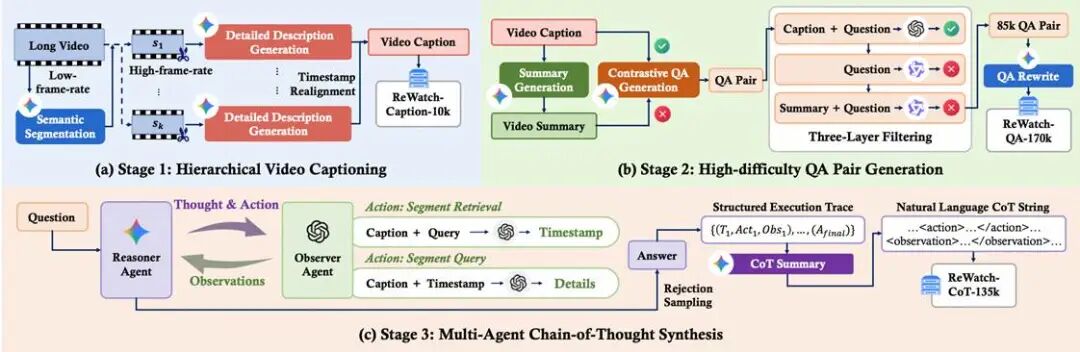
研究团队发现,现有训练数据存在三大痛点:视频描述粗糙、问答过于简单、思维链(CoT)严重依赖文本常识而非视频内容。为此,他们构建了一个包含1万视频、17万问答对和13.5万思维链的ReWatch数据集,它具备三大核心优势:
1. 高保真时序字幕(ReWatch-Caption):采用分层字幕生成方法,为长视频生成带有精确时间戳的详细事件描述,为复杂推理提供坚实、可查证的事实基础。
2. 高难度视频问答(ReWatch-QA):通过“摘要vs精读”的对比生成策略和三层过滤机制,确保问题必须依赖视频中的细节才能解答,从根本上杜绝模型靠“猜”或常识来蒙混过关。
3. 视频接地的思维链(ReWatch-CoT):首创多智能体ReAct框架,模拟人类在思考复杂问题时“回看、确认”的行为。通过“推理智能体”和“观察智能体”的协作,生成一条条明确记录了“去视频哪里看”(action)和“看到了什么”(observation)的推理轨迹,确保思维链的每一步都与视频内容紧密绑定。

整个数据集的构建过程包含三个阶段:分层字幕生成、高难度问答对生成、以及多智能体思维链合成,确保了数据的高质量和高难度。
授人以渔:让模型学会“如何思考”的ReWatch-R1
有了高质量的“教材”,如何教模型学习呢?研究团队采用了SFT+RL的范式,并通过一个创新的奖励机制,让模型真正掌握思考的精髓。
训练方法的核心是 带过程奖励的强化学习(GRPO with O&R Reward)。它不再仅仅奖励“答对与否”,而是直接监督和奖励模型的中间推理过程,从而有效抑制推理幻觉。
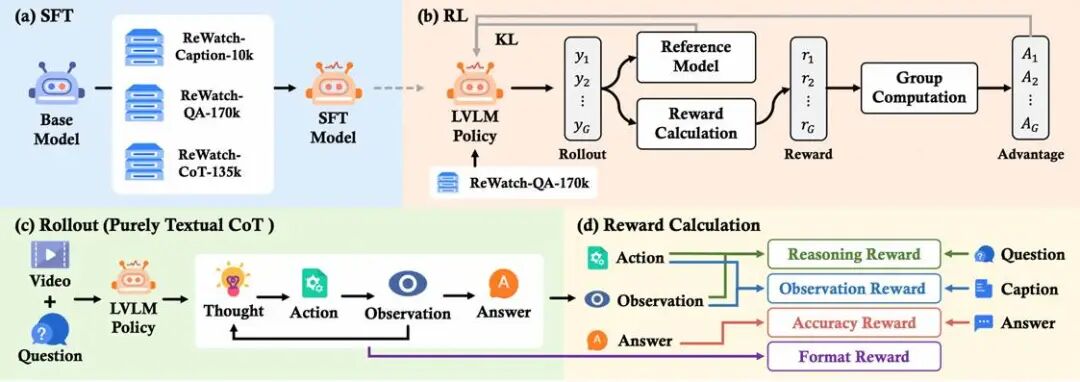
这个巧妙的“过程奖励”(O&R Reward)是如何计算的呢?
研究团队将推理过程拆解为 视频+问题→观察+推理→答案。过程奖励就针对中间环节进行评估:
1. 观察奖励(Observation Reward):模型的“观察”是否真实?将模型生成的观察结果(标签内容)与高质量数据集中的高保真字幕进行比对。观察越符合视频事实,奖励越高。
2. 推理奖励(Reasoning Reward):模型的“动作”是否有效?将模型推理中产生的“观察”结果作为唯一信息源,看它能否仅凭这些信息就推导出正确答案。如果可以,说明它的推理动作(标签内容)是充分且高效的,值得奖励。
通过这种方式,模型不仅学会了要得出正确答案(结果导向),更学会了如何通过真实、有效的步骤去思考(过程导向),像一个真正的侦探一样,基于证据链进行推理。
实践出真知:SOTA的实验结果与深刻洞察
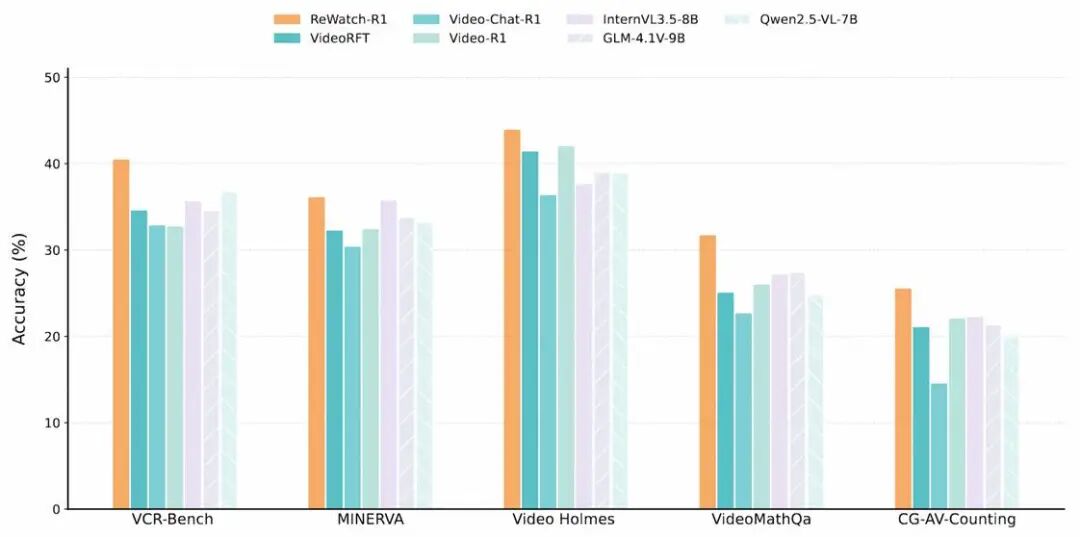
1. 全面超越,登顶SOTA
实验结果表明,ReWatch-R1在五个主流视频推理基准上,平均性能显著超越了所有同量级的开源模型,取得了SOTA的成绩,证明了该方法论的有效性。
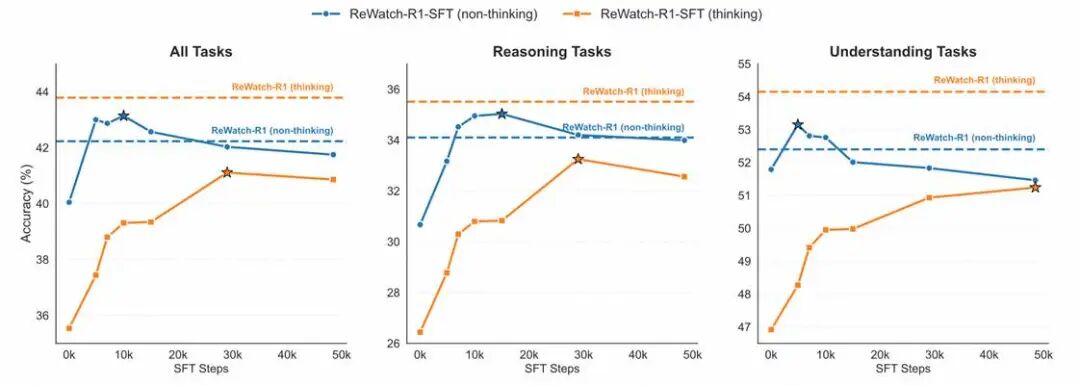
2. 关键洞察:RL才是释放“思考”潜力的钥匙!
一个非常有趣的发现是:在监督微调(SFT)阶段,“思考模式”的性能始终无法超越“直接回答”模式。这说明SFT只能教会模型思考的“形”,而无法领悟其“神”。
然而,经过RL阶段的“点拨”后,“思考模式”的性能实现了惊人飞跃,最终大幅超越了“直接回答”模式,展现出最高的性能上限。这有力地证明了,显式的、一步步的、有证据支撑的推理过程,对于解决复杂视频任务至关重要,而强化学习是激发这种能力的关键。
总结
ReWatch-R1的工作为视频理解领域贡献了宝贵的思路和资源。它通过创新的“智能体合成数据”方法,解决了高质量视频推理数据稀缺的核心瓶颈;并通过“过程奖励”强化学习,成功教会了模型如何基于视频证据进行“深度思考”,而不是空想。这项研究表明,让模型学会“如何思考”,是通往更高阶视频智能的关键一步。
论文标题:ReWatch-R1: Boosting Complex Video Reasoning in Large Vision-Language Models through Agentic Data Synthesis
论文链接:https://arxiv.org/abs/2509.23652
项目主页:https://rewatch-r1.github.io
开源数据:https://www.modelscope.cn/datasets/zcccccz/ReWatch
