

IT之家 2 月 3 日消息,腾讯混元官网技术博客(Tencent HY Research)今日(2 月 3 日)上线并发表了一篇名为《从 Context 学习,远比我们想象的要难》的文章,系统介绍了腾讯混元团队联合复旦大学的一项新研究。
这是姚顺雨加入腾讯担任首席 AI 科学家后带领团队首次发布研究成果,也是腾讯混元技术博客首次公开。这一博客的推出,旨在分享腾讯混元研究员在前沿技术研究和实践中的探索与经验。
博客提到,过去几年,大语言模型的进化速度快得令人惊叹。如今的前沿模型,已经是顶级的“做题家”:它们能解开奥数级别的难题,能推演复杂的编程逻辑,甚至能通过那些人类需要苦读数年才能拿下的专业资格考试。
然而,这些耀眼的成绩单可能掩盖了一个真相:能在考场拿满分的学生,未必能胜任真实世界的工作。
回看我们人类的日常工作:开发者扫过从未见过的工具文档,就能立刻开始调试代码;玩家拿起新游戏的规则书,在实战中边玩边学;科学家从复杂的实验日志中筛选数据,推导出新的结论和定律。我们发现在这些场景中,人类并不只依赖多年前学到的“死知识”,而是在实时地从眼前的 Context 中学习。
然而,今天的语言模型并非如此。它们主要依赖“参数化知识”—— 即在预训练阶段被压缩进模型权重里的静态记忆。在推理时,模型更多是在调用这些封存的内部知识,而不是主动从当前输入的新信息中汲取营养。
这揭示了当前模型的训练范式和在真实场景中应用之间是不匹配的:我们优化出的模型擅长对自己“已知”的事物进行推理,但用户需要的,却是让模型解决那些依赖于杂乱、动态变化的 Context 的任务。
简而言之:我们造出了依赖“过去”的参数推理者,但世界需要的是能吸收“当下”环境的 Context 学习者。要弥合这一差距,我们必须从根本上改变模型的优化方向。
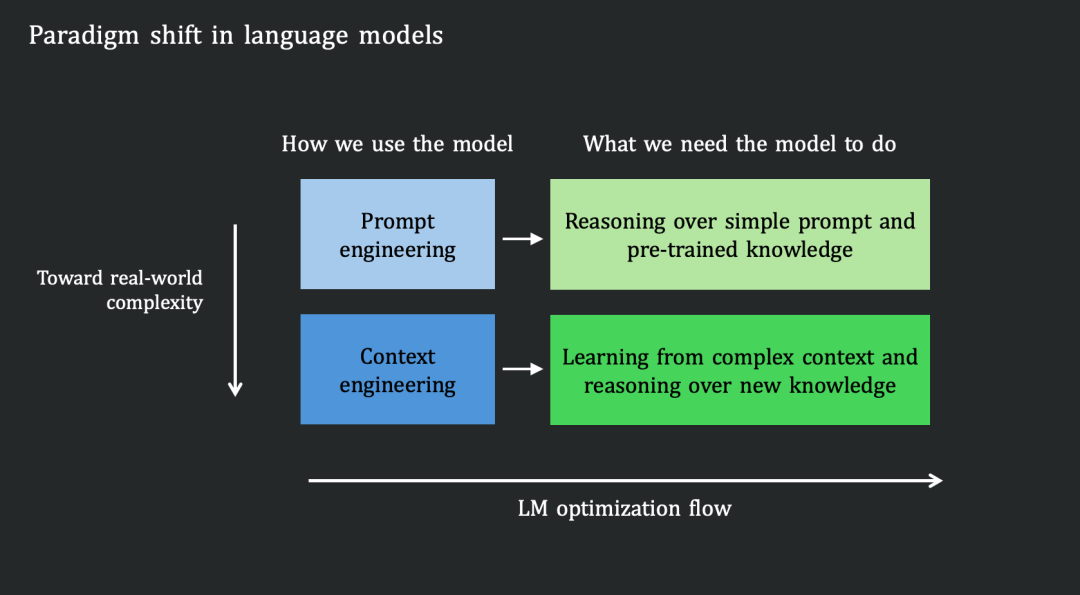
为了衡量现有模型距离真正的“Context Learner”还有多远,姚顺雨团队构建了 CL-bench。这是一个专门评测语言模型能否从 Context 中学习新知识并正确应用的基准。

CL-bench 包含由资深领域专家精心制作的 500 个复杂 Context、1,899 个任务和 31,607 个验证标准。CL-bench 只包含一个简单但苛刻的要求:解决每个任务要求模型必须从 Context 中学习到模型预训练中不存在的新知识,并正确应用。
具体来说,CL-bench 涵盖了四种广泛的现实世界 Context 学习场景:
领域知识推理: Context 提供特定的领域知识(例如,虚构的法律体系、创新的金融工具或小众专业知识)。模型需要利用这些知识来推理并解决具体问题。
规则系统应用:Context 提供新定义的正式系统(例如,新的游戏机制、数学形式体系、编程语法或技术标准)。模型必须理解并应用这些规则来执行任务。
程序性任务执行:Context 提供复杂的过程系统(例如,工作流、产品手册和操作指南)。模型必须理解并应用这些程序性信息来完成任务。
经验发现与模拟: Context 提供复杂系统内的实验数据、观测记录或模拟环境。与前几类涉及演绎推理不同,这一类专注于归纳推理,也是最具挑战性的。模型必须从数据中发现潜在的定律或结论,并应用它们来解决任务。
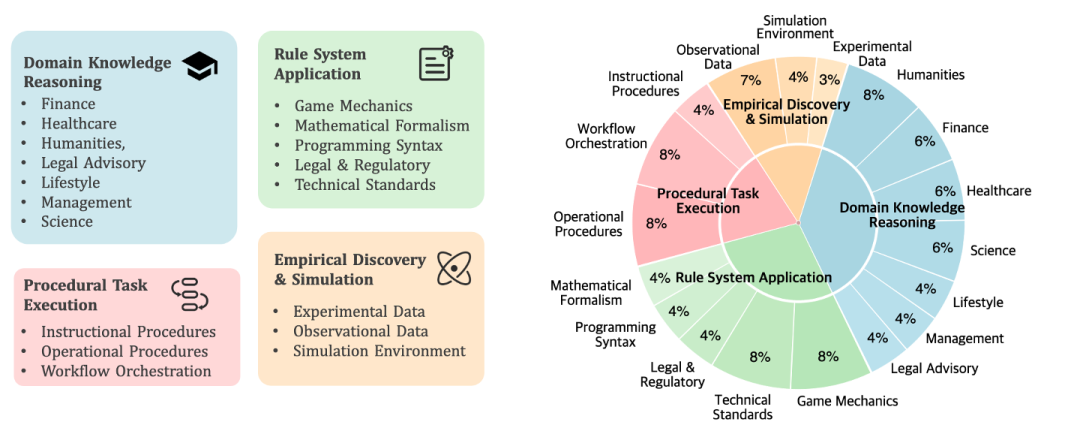
这些类别包含了大部分现实世界工作中常见的演绎推理和归纳推理任务,能充分衡量模型的 Context 学习能力。
为了确保性能真正反映 Context 学习,而不是记忆或数据泄露,CL-bench 采用了无污染(Contamination-free)设计:
虚构创作:专家创作完全虚构的内容,例如为虚构国家设计一套完整的法律体系(包括新颖的判例和法律原则),或创建具有独特语法和语义的新编程语言。
现有内容的修改:专家修改现实世界的内容以创建变体,例如更改历史事件、改变科学和数学定义,或修改技术文档和标准。
整合小众和新兴内容:专家纳入了在预训练数据集中代表性极低的小众或近期新兴内容,如前沿研究发现、新发布的产品手册或技术文档,以及来自专门领域的特定知识。
在不提供任何 Context 的情况下,最先进的模型 GPT-5.1 (High) 仅能解决不到 1% 的任务。这证明了数据是无污染的,模型若不从 Context 中学习,几乎完全无法解决这些任务。
此外,CL-bench 的设计具有高复杂性和序列依赖性。51.1% 的任务需要序列依赖,意味着后续任务的解决方案取决于早期交互的结果。这种多轮次设计显著增加了任务难度。平均而言,领域专家花费约 20 小时标注每个 Context ,以确保任务构建的质量和深度。
CL-bench 中的每个任务都是完全可验证的。平均而言,每个 Context 关联 63.2 个验证标准,每个任务包含 16.6 个评估标准。每个任务的正确性都从多个角度进行评估,确保了评估的全面性。
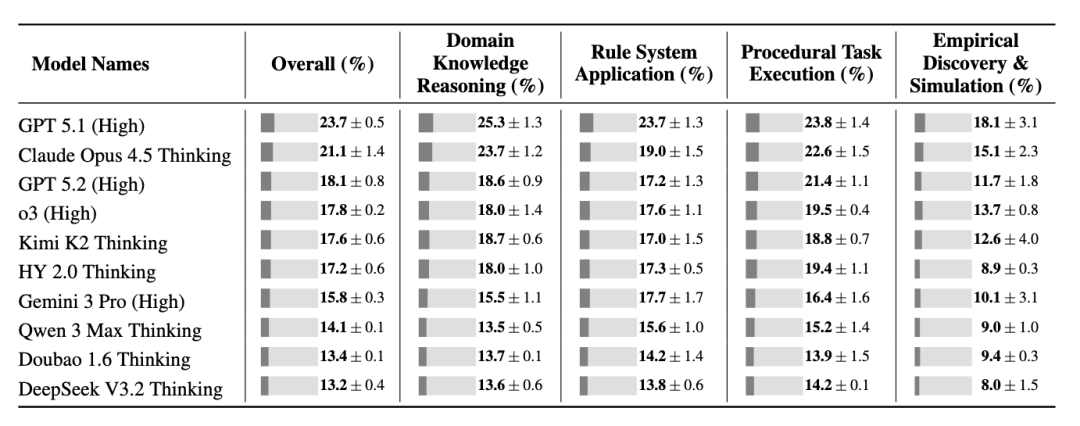
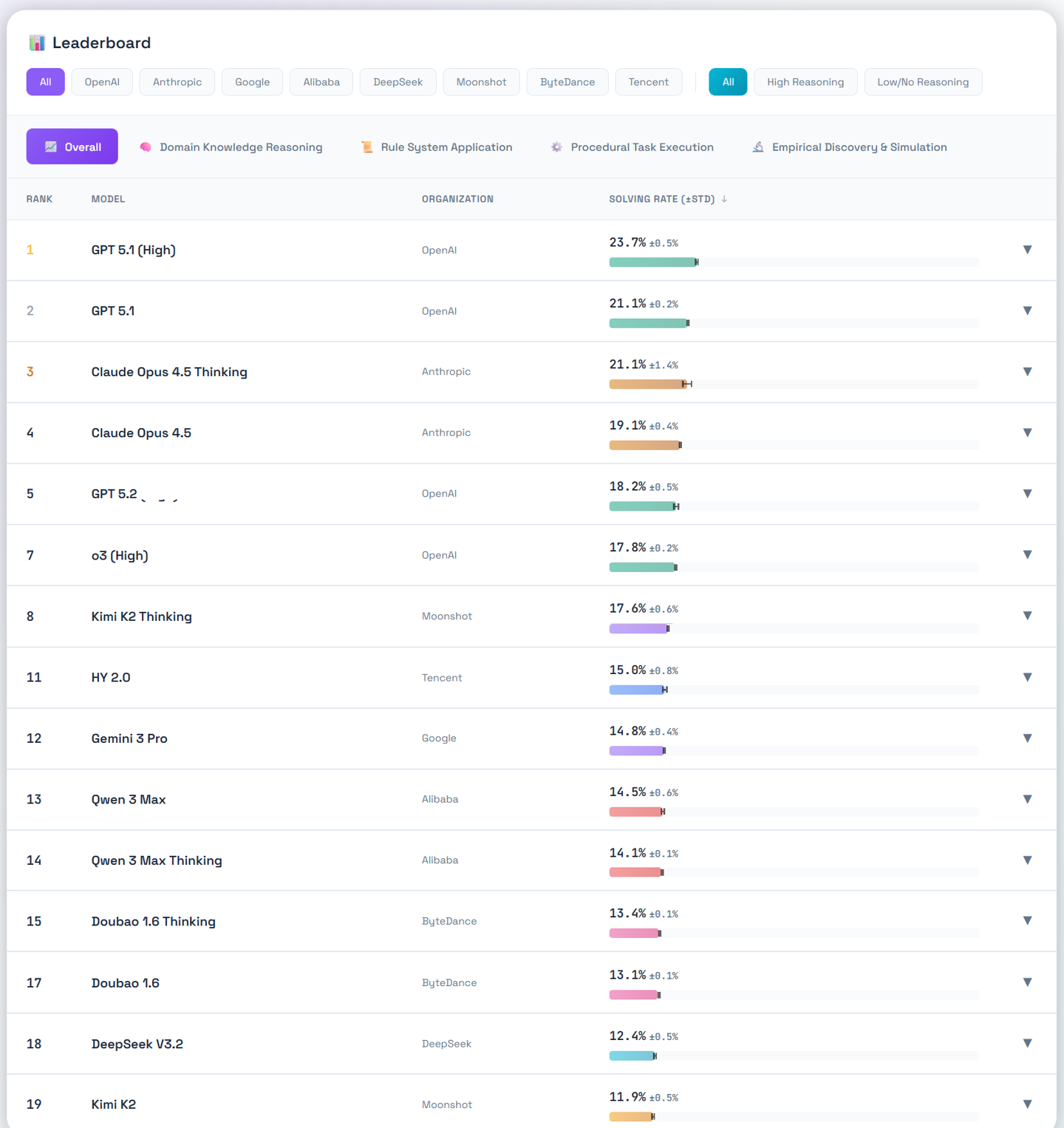
该团队在 CL-bench 上评估了十个最先进的语言模型。结果揭示了清晰且一致的差距。
平均而言,模型仅解决了 17.2% 的任务。即便是表现最好的模型 GPT-5.1 (High),也仅达到了 23.7%。换句话说,尽管 Context 中拥有解决每个任务所需的全部信息,模型在绝大多数任务上都失败了。这表明当前的 SOTA 模型几乎不会从 Context 中学习。
IT之家附项目官网如下:
https://www.clbench.com/
相关阅读:
《姚顺雨入职腾讯后首次公开发言:AI 在 To C 和 To B 领域的应用落地出现明显分化》
《消息称腾讯大模型团队架构调整:前 OpenAI 研究员姚顺雨任要职,校招最高 2 倍薪资挖 AI 人才》
