

面对Claude Opus 4.6和GPT Codex 5.3的猛烈攻势,谷歌反手就是一个Gemini 3 Deep Think的重大升级。

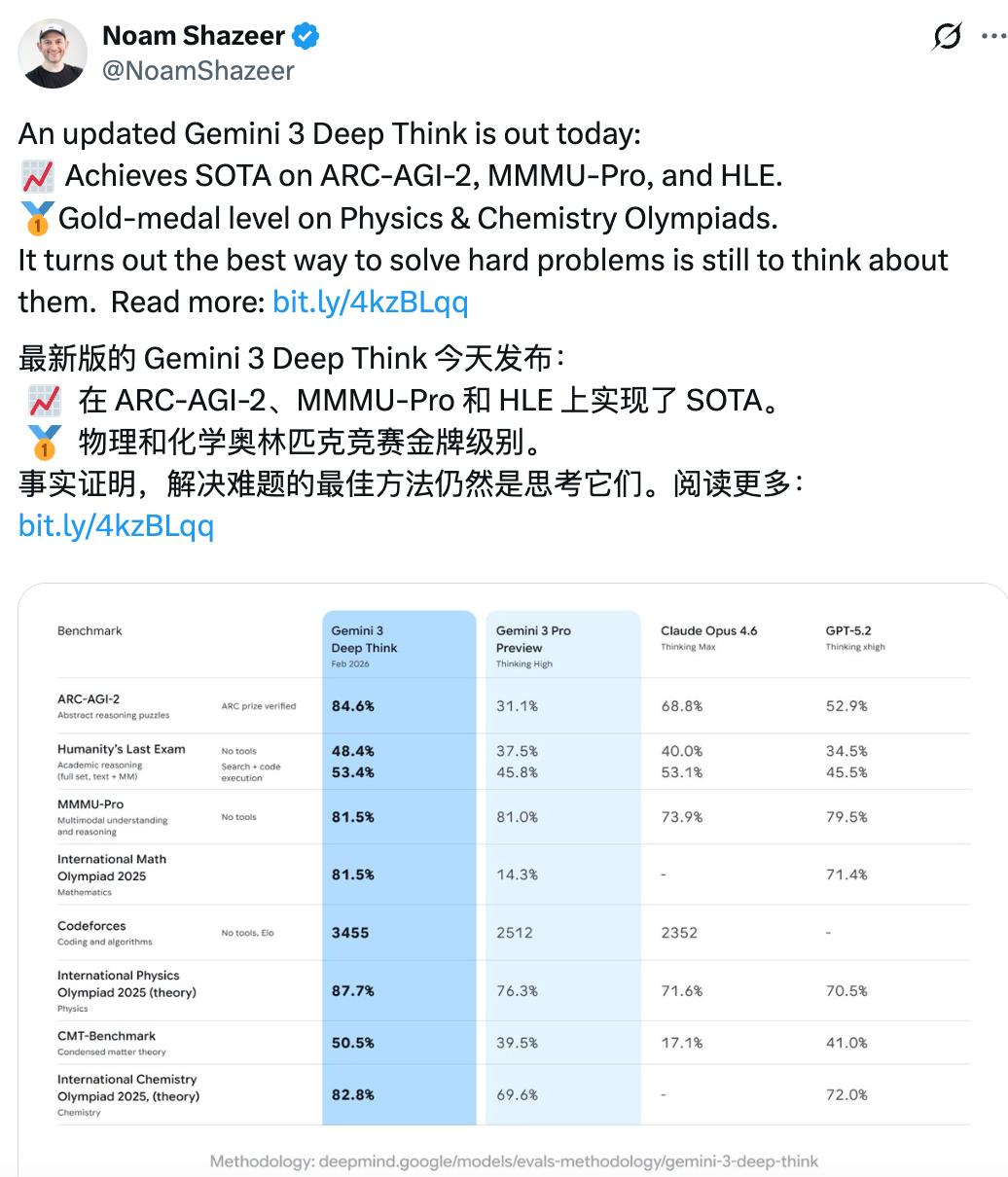
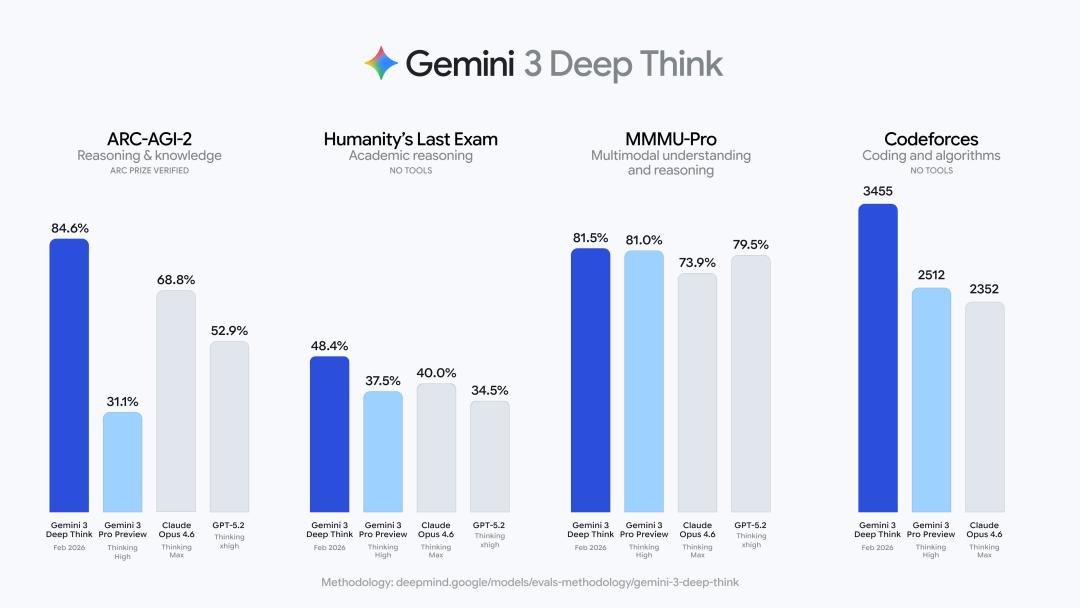
在Codeforces(一个包含各种竞技编程挑战的基准测试平台)上,它取得了惊人的3455 Elo分数,相当于世界第8名。
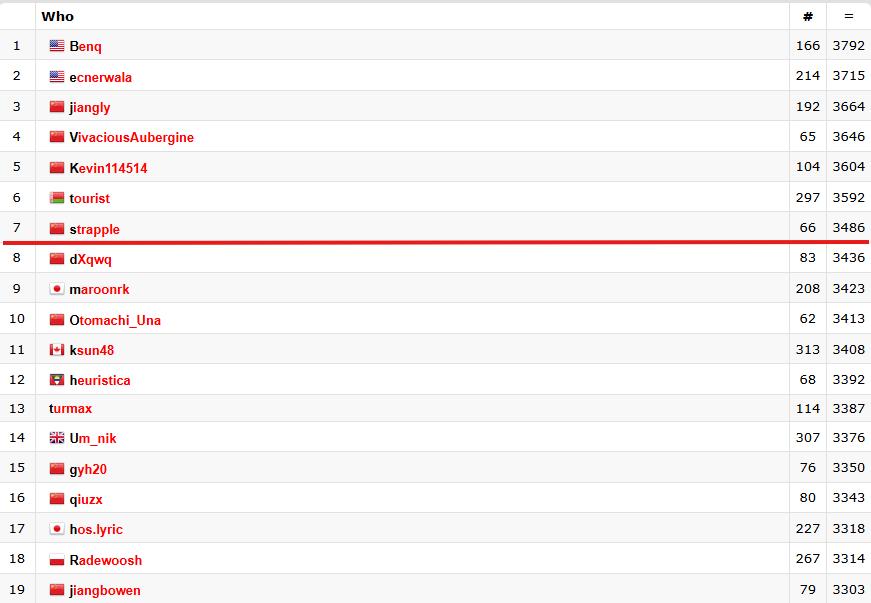
这下子,全球只有7人的编程水平能排在它前面了。而此前最高分是一年前o3拿下的2727 Elo。
Gemini 3 Deep Think的实力不止于此,它还直接把ARC-AGI-2——这个公认测试AI推理能力的前沿基准,给刷到了史无前例的84.6%。
要知道,之前最强模型的得分在60%-70%之间徘徊,Claude Opus 4.6的成绩也只有68.8%。
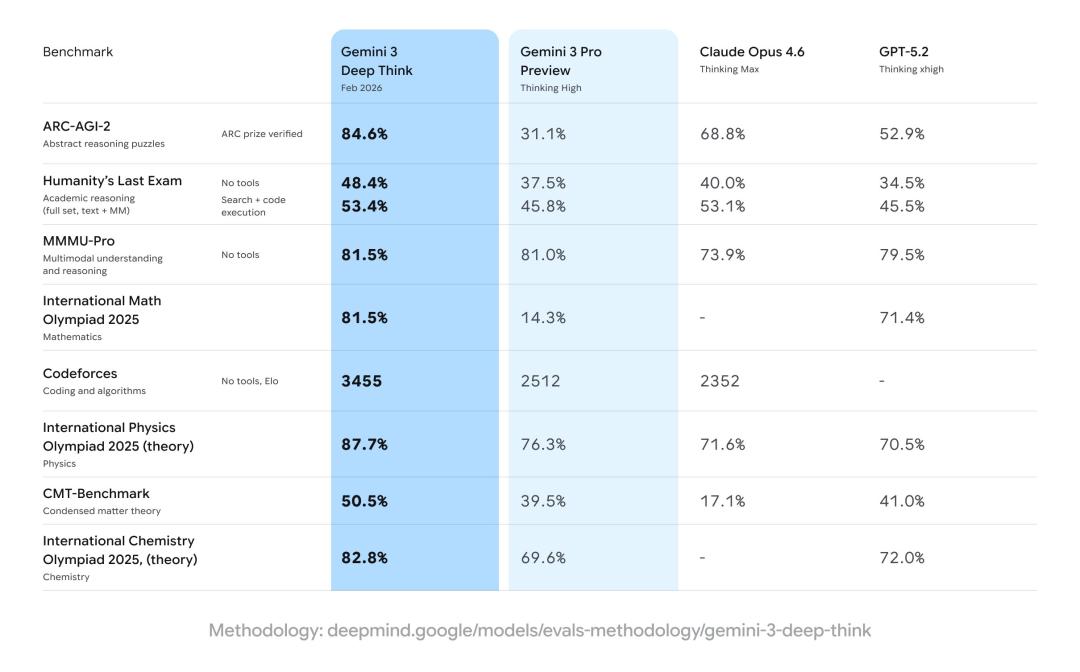
在人类最后考试(HLE)上,Gemini 3 Deep Think也刷新SOTA,拿下了48.4%的成绩。
官方表示,新版Deep Think是谷歌专门开发的推理模式,旨在推动智能前沿发展,并解决科学、研究和工程领域的现代挑战。
另一位“尧舜禹”——清华物理系传奇特奖得主姚顺宇(Shunyu Yao),去年9月加入谷歌DeepMind,也是这次Deep Think新模型的参与者。

新版DeepThink已经走进了实验室
升级后的Gemini 3 Deep Think实力究竟有多强?
它的野心不止于赢得基准测试,而是要走进科研和工程领域,帮助工程师处理复杂任务。
新版Deep Think可以分析草图,对复杂形状进行建模,并直接生成用于3D打印的实体文件。这是它打印的一个笔记本电脑支架:
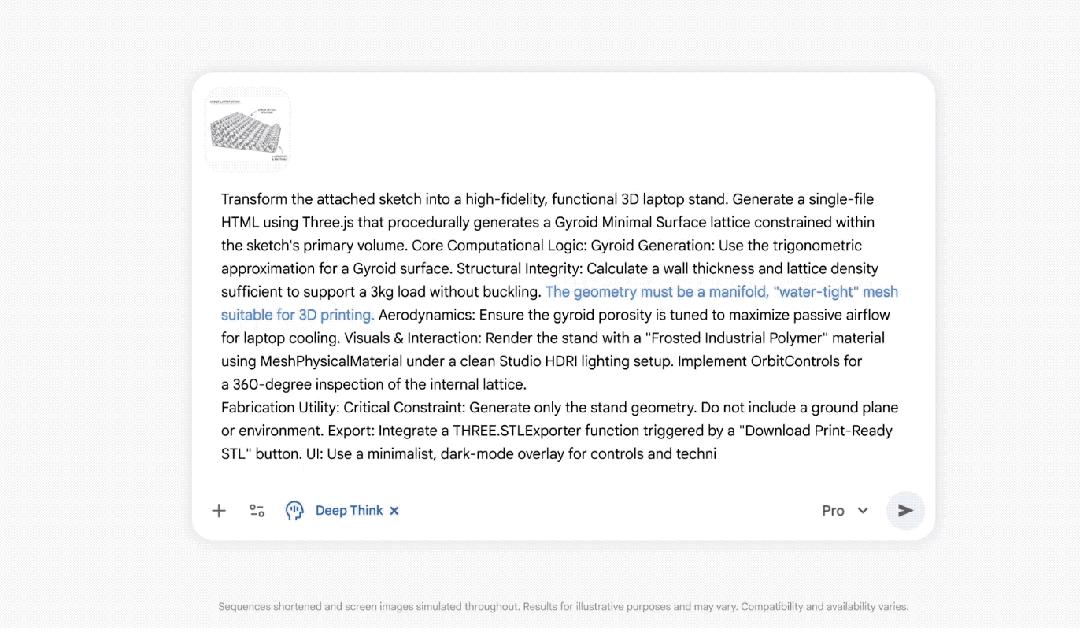
谷歌VP Josh Woodward 在X上晒出了打印的成果,看起来对草图相当还原:

罗格斯大学的数学家Lisa Carbone,利用Gemini 3 Deep Think审阅了一篇高度专业的数学论文。
结果Gemini 3 Deep Think成功地识别出了一个细微的逻辑缺陷,而这个缺陷在此前的人工同行评审中均未被发现。
杜克大学的王安实验室,利用Gemini 3 Deep Think技术优化了复杂晶体生长的制备方法,以期发现新的半导体材料。
结果Gemini 3 Deep Think成功设计了一种能够生长厚度大于 100 微米薄膜的工艺,达到了以往方法难以企及的精确目标。

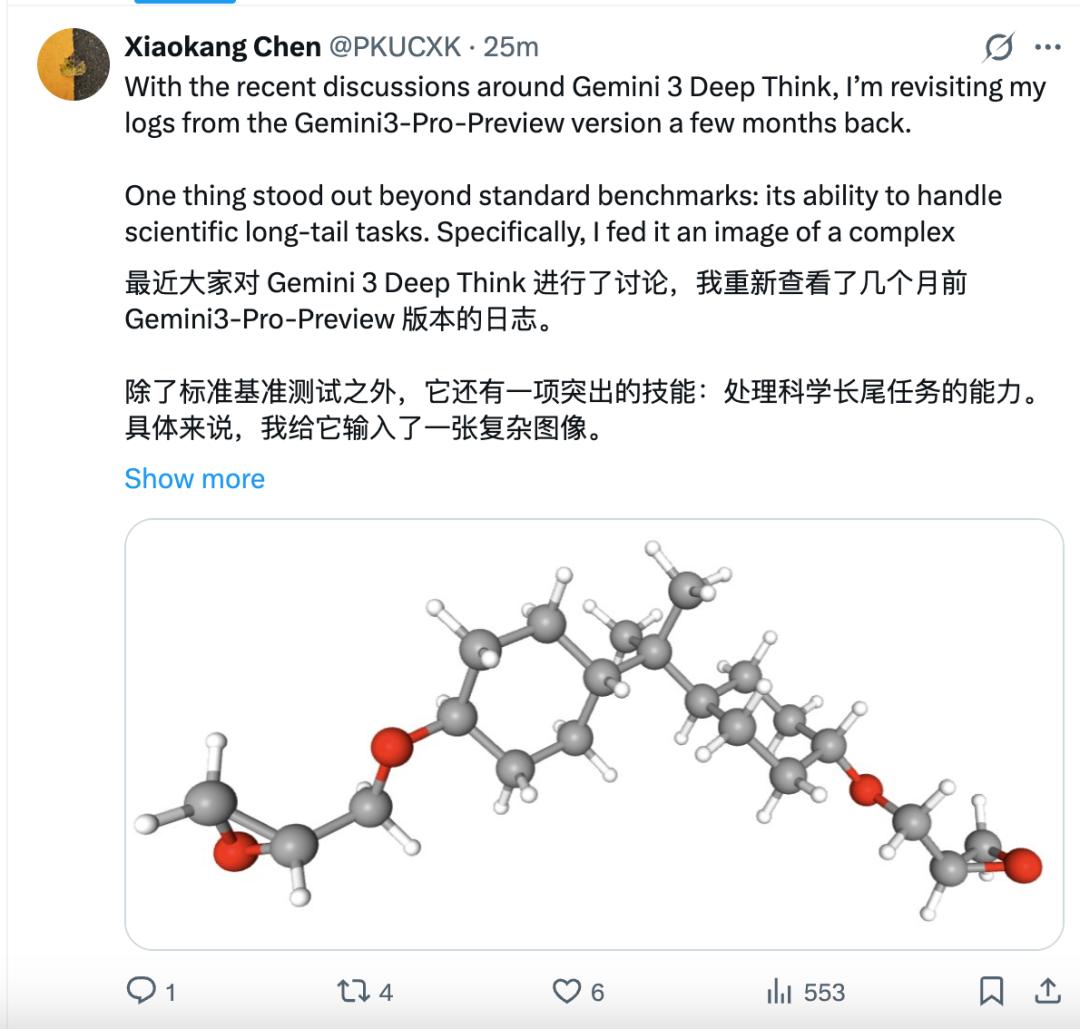
在X上,DeepSeek多模态团队研究员XiaoKang Chen也表示:Gemini 3 Deep Think非常擅长处理科学领域中的长尾任务。
他给Deep Think输入了一张复杂分子结构的图片,随后模型便准确地计算出了分子式。
勇夺三项新SOTA,推理成本降低82%
去年Deep Think专门版已经IMO等国际竞赛中夺下金牌。现在,全新升级后的Deep Think又在多项高难度的基准测试中全面刷新SOTA:
不使用任何工具,在HLE中取得新SOTA——48.4%;
在ARC-AGI-2测试中取得前所未有的84.6%的成绩,并经 ARC Prize 基金会验证;
在Codeforces上取得了惊人的3455 Elo分数;
在2025年国际数学奥林匹克竞赛中达到金牌水平。
其中,ARC-AGI-2被誉为AI界的“图灵测试”,旨在衡量模型处理从未见过的新颖推理任务的能力。
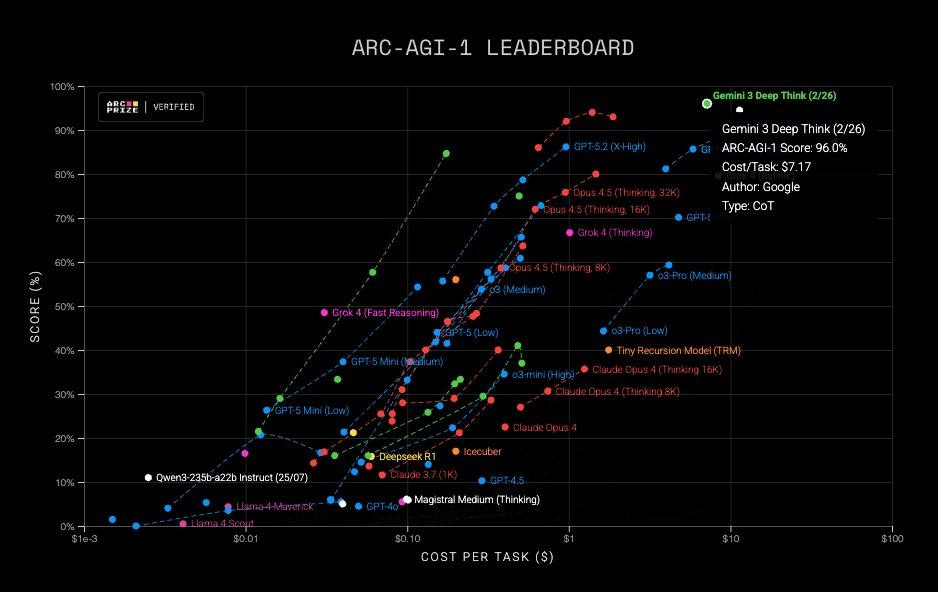
要知道,去年12月刚发布的初代Deep Think得分还是45.1%,不到三个月时间已经飙升到84.6%,比Opus 4.6还要强出一截。
而在ARC-AGI-1上,Gemini 3 Deep Think取得了96%的成绩,直接顶到天花板了。
性能提升的同时,推理成本也在大幅下降。初代Deep Think执行每项任务的成本为77.16美元。此次升级让成本降低了82%,每项任务仅需13.62美元。
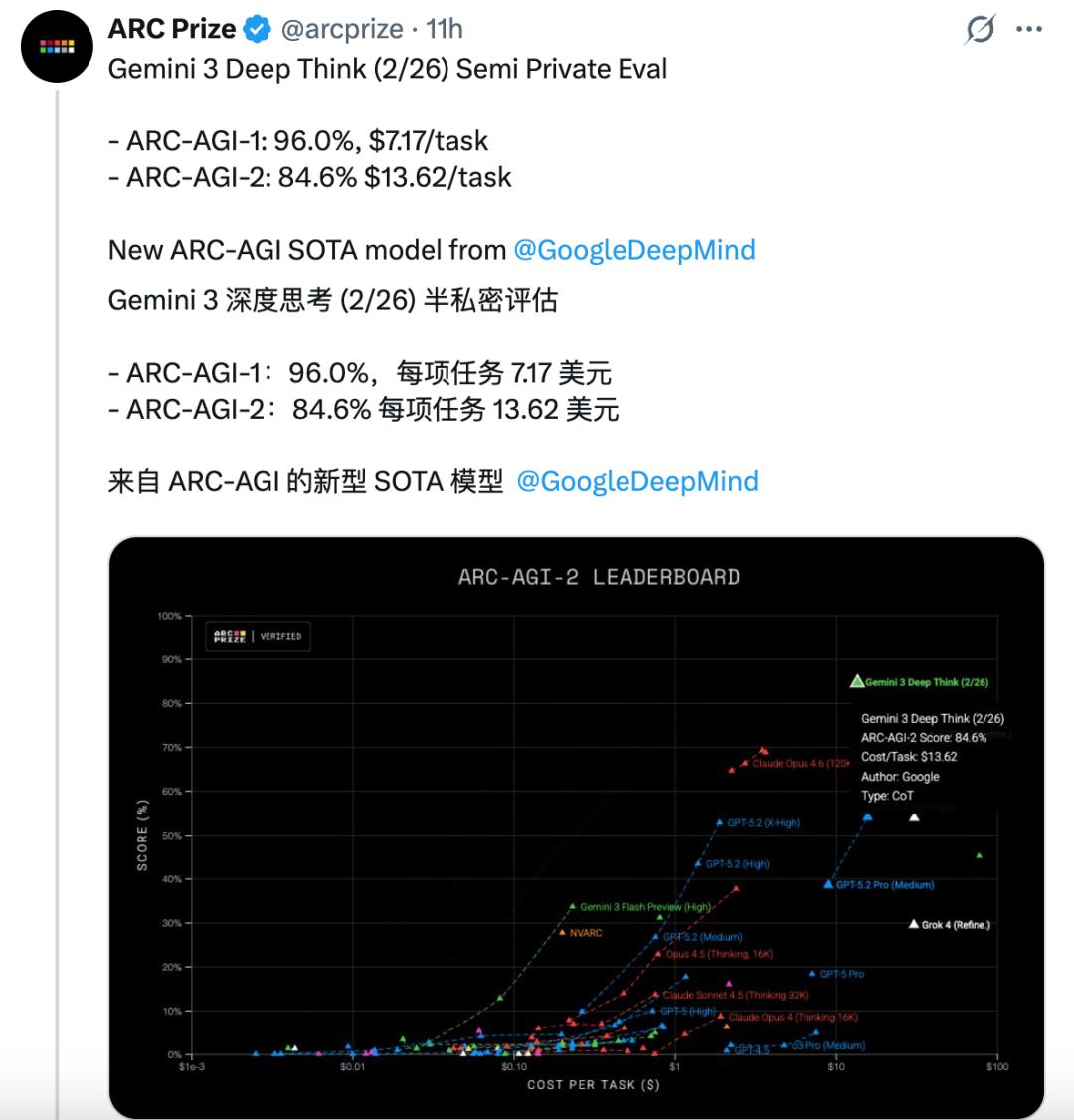
由于1和2都被Gemini刷爆了,现在ARC Prize已经在构建ARC-AGI-3了……
除了数学和编程,升级后的Deep Think在化学和物理等广泛的科学领域同样表现出色。
在2025年国际物理奥林匹克竞赛和化学奥林匹克竞赛中,Gemini 3 Deep Think在笔试部分取得了金牌级别的成绩。
此外,它还展现了在高等理论物理方面的能力,在CMT-Benchmark测试中取得了50.5%的分数。
华人带队,打造最强推理模型
Gemini 3 Deep Think的研发团队中,有不少华人身影。
核心成员包括95后华人科学家Yi Tay,他在Gemini团队中从事强化学习和推理方向的研究工作。
此前,他曾在Google Brain共同领导早期大语言模型项目,包括PaLM-2、UL2和Flan-2。
在Google Brain工作3年多之后,2023–2024 年间,Yi Tay曾短暂离开谷歌,作为联合创始人创办了一家独角兽AI初创公司——Reka。
Reka AI由DeepMind、谷歌和Meta的研究人员创立,其创办初衷是打造功能强大且高效的基础模型,现在也开发界面设计、应用逻辑以及其他应用方面的工具。
在创业一年半后,Yi Tay便重返谷歌DeepMind,担任高级资深研究科学家,继续从事人工智能和大语言模型的研究。
去年刚从Anthropic跳槽到谷歌DeepMind的清华校友姚顺宇,也参与了Deep think新模型的开发。

姚顺宇本科就读于清华大学物理系,曾拿下过清华本科生特等奖学金(清华授予在校优秀本科生的最高奖学金荣誉)。
本科期间,他就已在《Physical Review Letters》(国际物理学领域最顶级的学术期刊之一)发表高水平论文,首次在国际上给出了关于非厄米系统的拓扑能带理论,不仅准确预测了相关现象,还定义了两个新的物理概念。
本科毕业后,他赴斯坦福大学继续攻读博士,专注于量子多体混沌、开放量子系统动力学等前沿问题,师从Douglas Stanford(美国理论物理学家,被同行视为顶尖且有潜力改变物理学发展方向的年轻科学家之一)、Zhenbin Yang(杨振斌,华裔美国科学家,公认的20世纪最重要的物理学家之一)等知名学者。
博士毕业后,他先是去UC伯克利做博士后研究,随后加入了Anthropic。在Anthropic工作的一年时间里,他参与组建了强化学习基础团队,负责了Claude 3.7 Sonnet框架,以及Claude 4系列背后的基本强化学习理论。
离开Anthropic之后,姚顺宇转战谷歌DeepMind,继续从事AI方面的研究。这次Deep Think新模型发布,也是他在谷歌的首秀之作。
参考链接:
[1]https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-deep-think/
[2]https://x.com/ShunyuYao14/status/2022013770843967900
[3]https://x.com/YiTayML/status/2021988841142534287
[4]https://x.com/NoamShazeer/status/2021988459519652089
[5]https://x.com/PKUCXK/status/2022144532272623990
