

【导读】清华大学团队推出的Dolphin模型突破了「高性能必高能耗」的瓶颈:仅用6M参数(较主流模型减半),通过离散化视觉编码和物理启发的热扩散注意力机制,实现单次推理即可精准分离语音,速度提升6倍以上,在多项基准测试中刷新纪录,为智能助听器、手机等端侧设备部署高清语音分离开辟新路。
视听语音分离(Audio-Visual Speech Separation, AVSS)技术旨在模拟人类的「鸡尾酒会效应」,即利用说话人的面部视觉线索(如口型变化),从背景噪声或多人混合语音中精准提取出目标说话人的声音。这项技术在智能助听器、移动通信、增强现实及人机交互等领域具有极其重要的应用价值。
然而,长期以来,该领域面临着「性能与效率难以兼得」的困境:高性能模型往往依赖庞大的预训练参数和高昂的计算开销,难以在资源受限的边缘设备上部署;而轻量化模型则通常以牺牲分离精度为代价,且常依赖高延迟的迭代计算。
针对这一痛点,清华大学计算机系胡晓林副教授团队提出了一种全新的高效视听语音分离模型Dolphin。
该模型通过引入离散化视觉语义表征和基于物理先验的全局-局部注意力机制,在大幅降低计算复杂度的同时,刷新了多项基准数据集的性能记录。
Dolphin不仅是首个将参数量压缩至6M级别(计入视觉编码器)的兼顾高质量与高性能的AVSS模型,更在GPU推理速度上实现了相对于现有SOTA模型6倍以上的提升。

论文地址:https://arxiv.org/pdf/2509.23610
论文主页:https://cslikai.cn/Dolphin/
代码地址:https://github.com/JusperLee/Dolphin
现有的主流AVSS方法主要面临三大挑战:
- 视觉编码器的「路径依赖」问题。为了提取与语音高度对齐的语义特征,现有方法通常直接使用在唇读任务上预训练的大型视频编码器,这导致视觉分支的计算量巨大,甚至超过了音频处理本身;而简单的轻量化替代方案往往只能提取浅层的像素级特征,导致语义信息丢失,分离效果大幅降低。
- 迭代推理的高延迟。为了在有限参数下提升性能,轻量化模型(如RTFS-Net等)常采用循环迭代策略,即多次通过分离器来逐步优化结果。这种方式虽然减少了参数,但成倍增加了推理时间和计算延迟,无法满足实时交互需求。
- 特征建模的局限性。传统模型难以在单次前向传播中同时兼顾长时序的全局语境依赖和短时序的局部精细结构,导致在处理复杂声学环境时容易出现伪影或细节丢失。
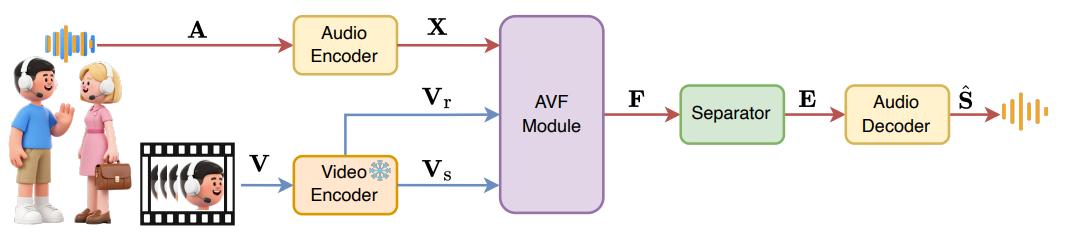
图1. Dolphin模型的整体pipeline架构图
针对上述问题,Dolphin提出了一套完整的解决方案,其核心架构包含以下三个关键创新点:
DP-LipCoder:基于矢量量化的双路径离散视觉编码器
为了在轻量化前提下获取高质量的视觉语义,团队设计了一个基于矢量量化的双路径离散视觉编码器DP-LipCoder(如图2所示)。
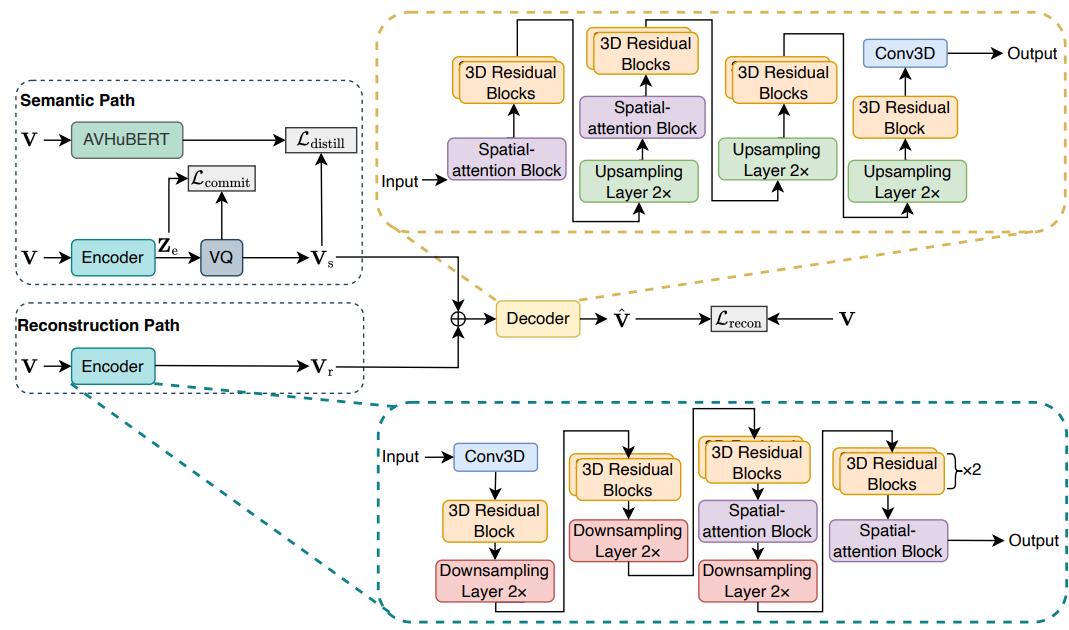
图2. DP-LipCoder网络结构
这是一个双路径架构,包含「重建路径」和「语义路径」。重建路径负责捕捉说话人的身份、面部表情等基础视觉线索。语义路径则引入了矢量量化(Vector Quantization, VQ)技术。
它通过将连续的视频帧映射为离散的token序列,并利用预训练的AV-HuBERT模型进行蒸馏,强制编码器学习与音频高度对齐的深层语义信息。这种离散化设计使得Dolphin能够以极低的计算成本,提取出具有极高判别力和抗噪性的视觉特征,有效解决了视觉编码器轻量化与编码语义信息丰富度冲突的问题。
GLA模块:单次迭代下的全局-局部协同建模
Dolphin摒弃了耗时的多轮迭代机制,使用了单轮编码器-解码器架构,并设计了高效的全局-局部注意力(Global-Local Attention, GLA)模块(如图3所示),确保模型在单次前向传播中即可完成高质量分离。 其中GLA模块的核心模块介绍如下:
全局注意力(GA):采用粗粒度自注意力机制,通过在低分辨率下捕捉长达数秒的全局语境信息,大幅降低了计算复杂度。
局部注意力(LA):这是该模型的另一大亮点。团队创造性地引入了基于物理学热扩散方程的「热扩散注意力(Heat Diffusion Attention, HDA)」。利用热扩散过程的平滑特性,HDA能够自适应地对特征进行多尺度滤波,在去除噪声干扰的同时,精准保留语音的瞬态细节。
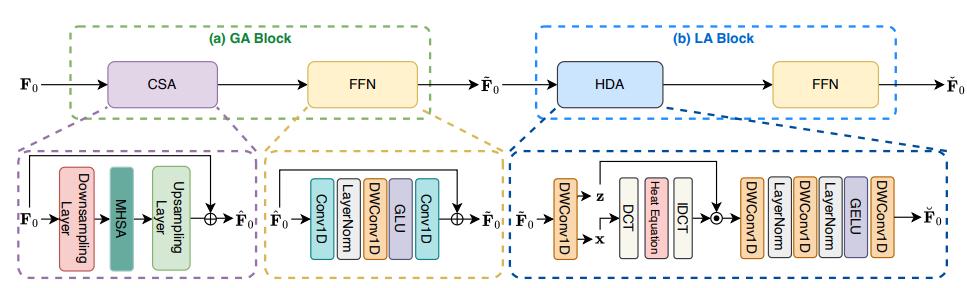
图3. GLA模块结构示意图
直接特征回归机制
与主流方法采用的掩码策略不同,Dolphin采用了直接映射策略。传统掩码方法通过预测一个0到1之间的掩码乘回混合语音,容易引入非线性失真。Dolphin则直接回归目标语音的深层表征,实验证明这一策略能有效提升信号的还原度,在SI-SNRi指标上带来了约0.5dB的额外提升。
一级实验结果与性能突破
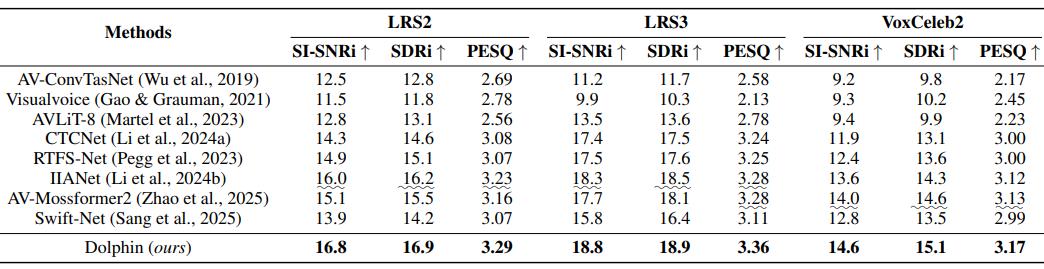
在LRS2、LRS3和VoxCeleb2三个权威的视听分离基准数据集上,Dolphin均展现了统治级的分离质量与性能优势:
- 分离质量全面领先:在LRS2数据集上,Dolphin的尺度不变信噪比(SI-SNRi)达到了16.8 dB,显著优于当前的SOTA模型IIANet(16.0 dB)和AV-Mossformer2(15.1 dB)。
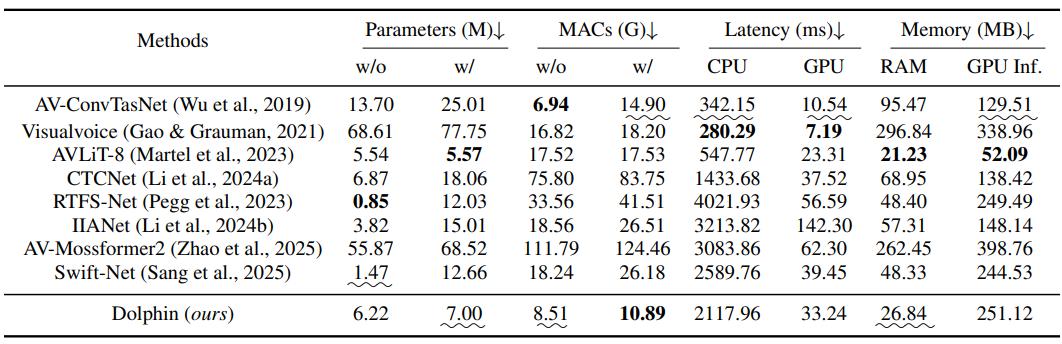
- 极高的模型性能:在模型参数量上,在计入视觉编码器参数的情况下,Dolphin的模型总参数量仅为6.22M,相比之下,IIANet的参数量高达15.01M,参数量减少了50%以上;在GPU推理延迟测试中,Dolphin处理1秒音频仅需33.24毫秒,比IIANet快了4倍以上,比轻量化模型RTFS-Net也快了近50%;同时,模型的计算量(MACs)仅为10.89 G,相比IIANet,RTFS-Net等模型降低了50%以上。
- 高鲁棒性与优越实际听感:在面对3-4人混合说话、高强度背景音乐干扰以及真实世界辩论视频等「在野」场景时,Dolphin表现出了极强的鲁棒性。在主观听感测试(MOS)中,Dolphin获得了3.86的高分,远超对比模型的2.24分,证明其分离出的语音更加清晰、自然且无人工痕迹。
总结
随着大模型技术的不断发展,视听语音分离领域也在追求大模型来提升分离质量。然而,这对于端上设备并不是可行的。Dolphin的提出打破了视听语音分离领域长期存在的「参数量换性能」的固有思维。
通过引入离散化语义表征和受物理启发的热扩散注意力机制,Dolphin证明了轻量化模型完全有能力在性能上超越大模型。这项工作为未来在智能眼镜、手机端侧大模型以及实时会议系统等资源受限场景中部署高精度语音分离技术,提供了全新的技术路径和理论支撑。
参考资料:https://arxiv.org/pdf/2509.23610
