


对于大模型,OpenAI、Anthropic、谷歌等全球顶尖的AI公司,都在不断地强调模型的通用性,以及其涌现能力。可字节在豆包2.0上,却来了一波“反向操作”。
字节跳动选择了一条更务实的路径。他们从真实业务场景倒推模型能力。
豆包团队发现,企业用户最高频的需求不是解奥数题,而是处理混杂着图表、文档的非结构化信息,然后在这个基础上完成多步骤的专业任务。
于是豆包2.0把优化重点放在了多模态理解、长上下文处理、指令遵循这些“不那么性感但很实用”的能力上。
这种路径选择可能更接近AGI的本质。
真正的通用智能不是在所有基准测试上都拿高分,而是能在真实世界各种杂七杂八的约束下,依然按要求完成任务。
一个能解IMO金牌题但无法完成企业报表分析的模型,和一个可以稳定完成业务流程的模型,哪个更“智能”?
豆包2.0的答案很明确。
我把这段话发给了豆包2.0,它回答我说

虽然有些阿谀奉承、迎风拍马,但我们的观点是相似的。
01
豆包2.0来了
就在2026年情人节这天,豆包更新了2.0版本。PC、网页版、手机用户都可以从对话框选择“专家”模式,以开启豆包2.0。
与此前版本相比,豆包2.0的核心变化在于从“能解题”转向“能做事”——针对大规模生产环境的使用需求进行了系统性优化。
豆包2.0系列包含Pro、Lite、Mini三款通用Agent模型和一款 Code 模型。
豆包2.0Code 接入了AI编程产品TRAE,而火山引擎也同步上线了豆包2.0系列模型API服务。
从公开的基准测试数据来看,豆包2.0 Pro在多个维度上取得了有竞争力的成绩。
豆包2.0在IMO、CMO 数学竞赛和ICPC编程竞赛中获得金牌成绩,在 Putnam基准测试上超越了Gemini 3 Pro。
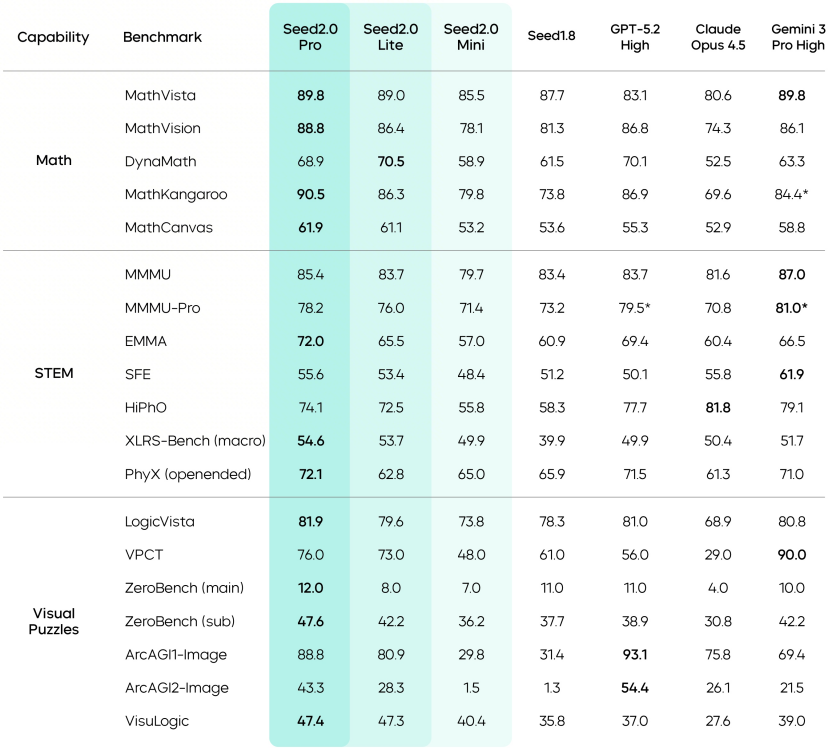
在HLE-Text(人类的最后考试)这项综合性评测中,豆包2.0 Pro得分54.2,在参与对比的模型中排名第一。
不过需要注意的是,基准测试成绩与实际应用表现之间存在差异。
字节跳动团队自己也承认,豆包2.0在端到端整体代码生成、上下文学习等方面,与国际领先模型相比仍有提升空间。
这种坦诚的表态,比单纯强调优势更有说服力。
在科学领域知识测试中,豆包2.0的表现与Gemini 3 Pro和GPT-5.2处于同一水平线。
在SuperGPQA测试中,豆包2.0 Pro得分68.7,略高于GPT-5.2的67.9。在HealthBench测试中得分57.7,排名第一。
这些数据表明,相较于豆包1.8,新版本的豆包在长尾领域知识覆盖上有所加强。
豆包2.0在多模态理解上的提升是全方位的。
在视觉推理方面,模型在MathVista、MathVision等基准上达到了业界最优水平。
这些考试比简单的图像识别要复杂得多。
因为这些测试的目的,是考察模型能否从图像中提取数学关系、理解几何结构、进行逻辑推演。
在文档理解场景中,豆包2.0在ChartQA Pro与OmniDocBench 1.5基准上的表现达到顶尖水平。
现实中的文档往往是表格、图表、文字、公式混杂的复杂版式,模型需要准确识别结构、提取信息、理解关系。
在长上下文理解方面,豆包2.0在 DUDE、MMLongBench等测试中取得了较好成绩。
视频理解是豆包2.0的一个重点优化方向。
在TVBench、TempCompass、MotionBench等测试中,豆包2.0处于领先位置。
值得注意的是,在EgoTempo基准上,豆包2.0的得分超过了人类水平。这个细节说明,模型在捕捉“变化、动作、节奏”这类时序信息时,可能比人类更稳定.
豆包2.0还支持流式实时视频分析,可以实现环境感知、主动纠错与交互。这种能力的应用场景包括健身指导、穿搭建议等,模型能实时观察并给出反馈,而不是事后分析录像。
02
豆包团队如何实现?
其实豆包2.0的这些提升背后,涉及到了多个层面的优化。
多模态融合架构的改进是基础。
传统的多模态模型是把视觉编码器和语言模型简单拼接,视觉信息和文本信息的交互深度不够。
豆包2.0强化了视觉与语言的深度融合,让模型能更好地理解图像中的语义信息。
人类看一张图,它是包含因果关系的。

就拿这张图来说,传统多模态大模型看到这张图,它理解的是“姚顺宇”、“话筒”、“手”、“西装”。
但是人类理解这张图是“姚顺宇西装革履拿着话筒正在演讲”。
即使图片是静态的,也能因为他的神态、穿着来判断此时正在做什么。
此外,豆包2.0对注意力机制的改进,为它带来了长上下文处理能力的提升。
处理长文本或长视频时,模型需要在海量信息中保持注意力,不能顾此失彼。
就比如你在阅读这篇文章的时候,A部分出现了大量的技术名词、术语,你也只会挑其中的图片以及数字来一目十行地看,不会逐字逐句认真看。
因此豆包2.0其实是以人类读长文章时那样,自动抓重点,而不是平均分配注意力。
技术上,这需要更高效的注意力计算方法和更合理的信息筛选机制。

最后,豆包2.0推理能力的提升不只是记住更多知识,而是真正提升了从已知推导未知的能力。
这涉及到训练过程中对推理链的显式建模,让模型学会“一步步思考”而不是直接给答案。这种能力在解决复杂问题时尤为重要。
03
现实不是竞赛
字节跳动团队观察到一个现象,语言模型已经可以顺利解决竞赛难题,但放在真实世界中,它们依然很难端到端地完成实际任务。
比如一次性构建一个设计精良、功能完整的小程序。
这个鸿沟的原因主要有两点,第一是知识覆盖的问题。
竞赛题目通常聚焦在数学、编程等核心领域,而真实任务往往涉及长尾领域的专业知识,比如前文提到的医疗、法律、工程、商业等等。
第二是指令遵循的问题。
真实任务通常包含多个步骤、多重约束,模型需要严格按照要求一步步推进,不能跑偏,不能遗漏。
豆包2.0试图通过系统性加强长尾领域知识和强化指令遵循能力来弥合这个鸿沟。
从测试数据来看,在深度研究任务、复杂agent能力评估等方面,豆包2.0达到了业界第一梯队水平。
在客服问答、信息抽取、意图识别等高频应用场景上,模型表现也比较稳定。
播客中给出了一个有意思的案例——高尔基体蛋白分析。
豆包2.0不仅能给出总体实验路线,还能把基因工程、小鼠模型构建、亚细胞分离与多组学分析串成完整流程,细化到关键环节怎么做、用什么进行对照、用哪些指标评估纯度。
相关领域专家表示,这个方案在跨学科的实验细节与步骤化表达上,超出了他们对大模型的预期。
不过,从“能给出方案”到“方案真正可行”,中间还有验证的距离。这个案例更多说明模型在知识整合和表达能力上的进步,而不是说它已经能替代科研人员做实验设计。
众所周知,AI编程是2026年最火的赛道,豆包2.0 Code是针对编程场景优化的版本,已上线TRAE作为内置模型。
字节团队展示的案例是“TRAE春节小镇·马年庙会”互动项目。通过1轮提示词构建基本架构,再经过几次调试,总共5轮提示词完成作品。
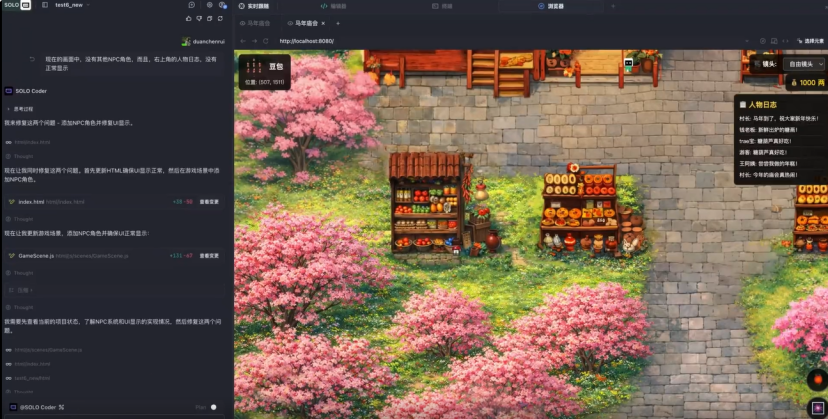
这个小镇里有11位由大语言模型驱动的NPC,会根据人设自然聊天、招呼顾客、现场砍价。
AI游客自己决定去哪家摊位、买什么、说什么。
其中,烟花升空时的祝福语、孔明灯上的题词都由AI即时生成。每次进入小镇,看到的互动都可能不同。
这个案例展示了豆包2.0 Code模型在快速原型开发上的能力。不过需要注意的是,从原型到产品之间还有很长的路要走。
从字节跳动的策略来看,豆包2.0强调“面向真实世界复杂任务”,这是一个务实的定位。
通过分析真实使用场景来指导模型优化,而不是单纯为了刷榜。
这种以需求为导向的研发思路,可能比单纯追求基准测试分数更有价值。
