

深夜凌晨2点,我刚准备睡觉。
然后,GPT-5.4,突然发布。
一下子激动的睡不着了。
真的,这真不是我天天咋咋呼呼啥的,我真的也很少会用激动的睡不着觉这种表述。
这是因为,我一直在等正式版的GPT-5.3或者GPT-5.4,来作为我的OpenClaw的首选模型。
理由特别简单,因为现代世界三十年,本质上基层都是代码,我们现在看到的关于计算机和互联网的一切,几乎都建立在代码的基础之上。
所以你可以理解为,代码能力,在很多时候,就代表着Agent能力的一根粗壮的腿。
一个优秀的Agent基座模型,在我的理解里,一般来说,需要三种都很强:
代码能力、世界知识、多模态理解。
当你这三个都能SOTA的时候,你几乎必然就是最牛逼的Agent模型,当然,还有一个重要的因素,就是价格。
在过去,Claude Opus 4.6,几乎就是Agent模型的代名词,因为代码、世界知识都很强,多模态能力虽然比不过Seed 2.0和Gemini 3.1 Pro,但是在一些场景里面,也够了,因为现在的Agent,跟现实物理交互还没有那么多,那个已经是具身智能的范畴了。
而我过去很喜欢的GPT-5.3-Codex,代码能力确实强,在做任务执行的时候,那简直就是指哪打哪。
但是最大的问题,这玩意是一个编程特化模型啊,世界知识就是一坨屎,连GPT-5.2都不如,所以OpenAI当时也是没办法,为了跟Claude打一打,只能加个Codex的后缀给放出来了。
所以你会发现,在规划能力上,是完全比不过Claude Opus 4.6的,但是最大的问题,其实还是因为世界知识的问题,就导致这玩意。
它说天书,讲的那些话,真的,我不是程序员出身,我看那个话,看的就真的超级费劲。
就比如说,我让他之前对我的一个AI热点网站的项目进行审查,主要就是review一下我的文档规范和我整个代码库。
然后,这哥们写的文档,我尼玛。。。

你再对比一下Claude Opus 4.6写的。

对比起来应该一目了然。。。
就是因为这玩意不说人话,世界知识也不行,所以,只是在Codex里面用用还好,但是你要是把它接到你的OpenClaw里面,去当做默认模型,你就知道啥叫灾难了,这哥们几乎没有人味,说起话来我想揍他。
所以我当时试了一下,就直接弃了,还是在我的OpenClaw里面,用的Claude Opus 4.6和Sonnet 4.6,做了一下场景调用。
那为啥说,我很期待GPT-5.4呢。
因为,Claude哪都好,但是,它贵啊!!!
它真的好贵啊!!!!!!
而且因为Anthropic这个呆逼,它把OpenClaw给疯了,所以我订阅的Claude的Max Plan的额度,是完全不能给OpenClaw用的,只能在Claude Code用,你想在OpenClaw上用,只能硬接API Key用。
但是大家都知道,Claude的API有多贵,那根本不是我们这种穷逼团队能用的起的,小规模用用还好,大规模用那公司直接破产了。
之前还有一条路是用反代,把Google家的Antigravity里面的Claude额度用插件代理出来,扔给OpenClaw用。
但是后面Google开始大批量封号,导致也没办法用了。
我过年的时候Google账号还被封了,被迫用AI去给Google写了一份声泪俱下的邮件。
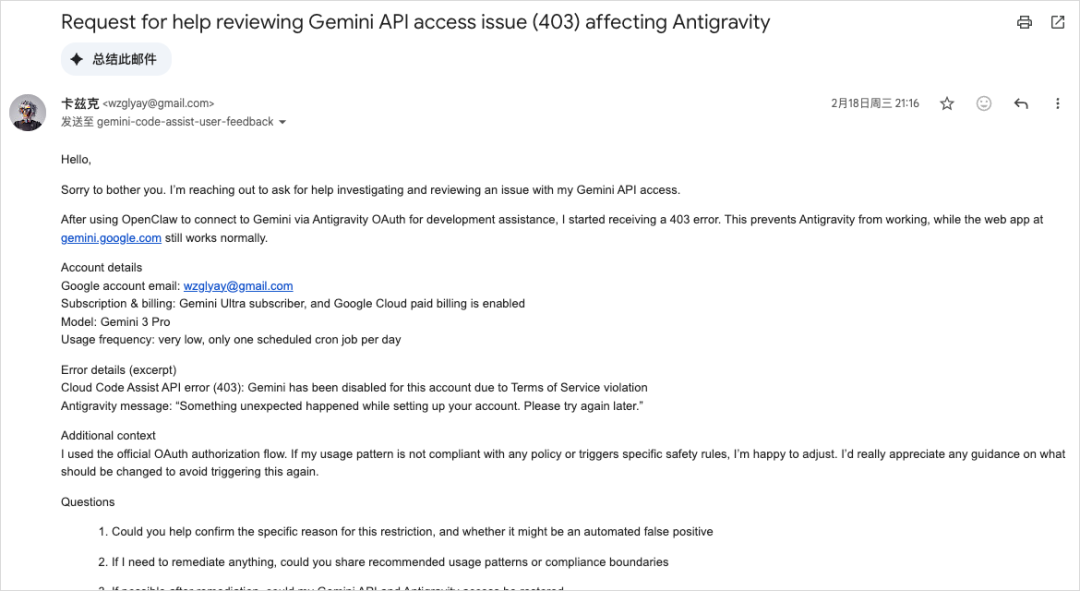
我说我错了,我再也不会了。
后面Google才给我解封,但是反代肯定是用不了了。
而OpenAI就不一样了,最开始Claude疯狂封OpenCode账号的时候,OpenAI大手一挥,就站了出来,说我们不封,大家全力使用。
这是御三家里,唯一一个这么支持态度的,可以用第三方的工具,调用Codex的额度的。
那对OpenClaw自然也不例外了,也是几个顶级模型里面,为数不多的,可以直接走登录的,其他的都得用API。
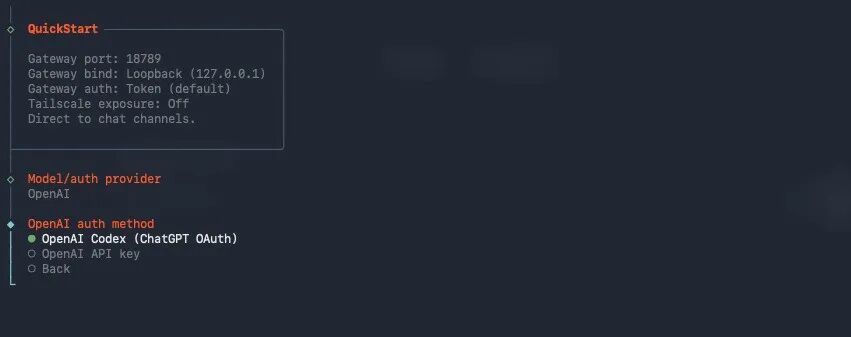
真的,OpenAI这会真的是大善人。
还疯狂的给Codex加额度。

所以啊,Claude在OpenClaw里用,好是好,但是不能用订阅额度,只能用API,贵的一笔。
OpenAI的模型倒是可以用订阅额度,但是GPT-5.2代码又不行,GPT-5.3-codex又不说人话。
你看,要多别扭有多别扭。
而这一次,GPT-5.4来了!!!
终于把这个短板给补上了!
代码能力跟GPT-5.3-Codex齐平,世界知识比GPT-5.2还要强,还能使用订阅额度,20刀就可以用的超级爽。
你就说,这不是最适合OpenClaw的天选模型,还有谁是?嗯?
从今天开始,用OpenClaw的,都把默认模型切换到GPT-5.4去,真的,信我。
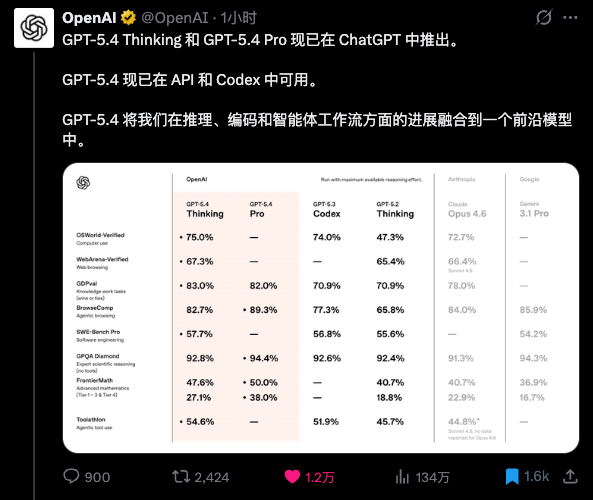
回到GPT-5.4,老规矩,先看跑分。
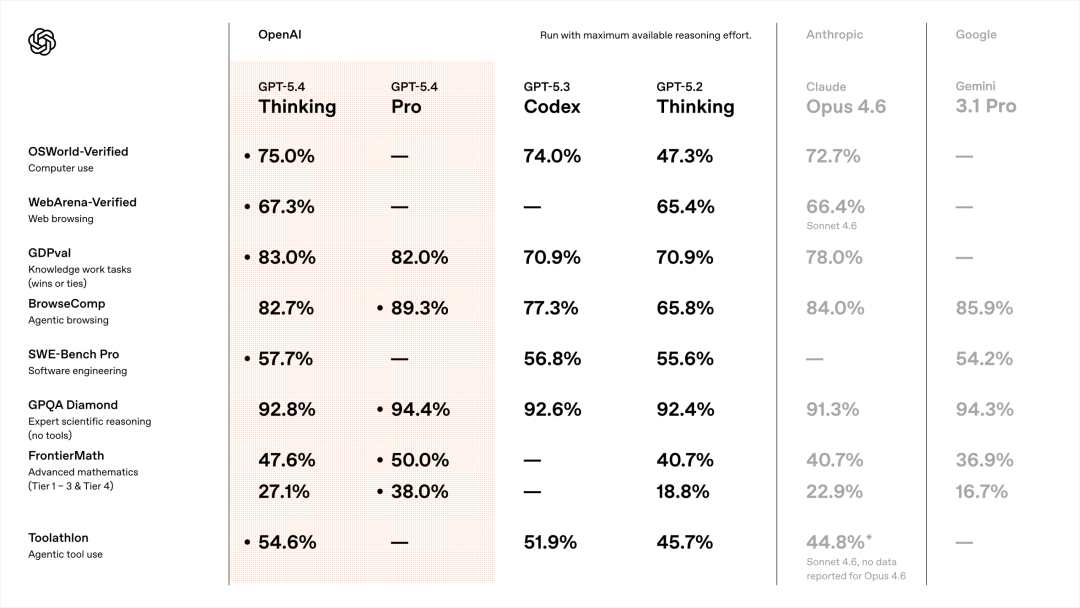
就很爽。
先看最关键的几个。
GDPval:83.0%
这个是测AI在真实工作任务中表现的,包括金融、法律等44种职业的知识工作。
GPT-5.4 Thinking拿了83.0%,Claude Opus 4.6是78.0%,GPT-5.3 Codex是70.9%。
在真实业务场景里,GPT-5.4不只是会写代码,它还能跟你聊业务、聊金融、聊法律、聊各种专业领域的东西。
而且是用人话聊,不是用天书聊。
SWE-Bench Pro:57.7%
这个是测AI解决真实软件工程问题的,不只是Python,而是测四种编程语言。
GPT-5.4 Thinking拿了57.7%,GPT-5.3 Codex是56.8%。
基本持平。
这就是我最想看到的结果。
代码能力保住了GPT-5.3 Codex的水平,世界知识又补上来了。
OSWorld-Verified也是,75.0%。这个是测AI操作电脑的能力的,就是让AI像人一样,用鼠标点击、用键盘输入、在不同应用之间切换,完成各种任务。
GPT-5.4 Thinking拿了75.0%,超过了Claude Opus 4.6的72.7%,也保持了跟GPT-5.3-Codex的持平。
而且,GPT-5.4操作电脑的速度,快的离谱。
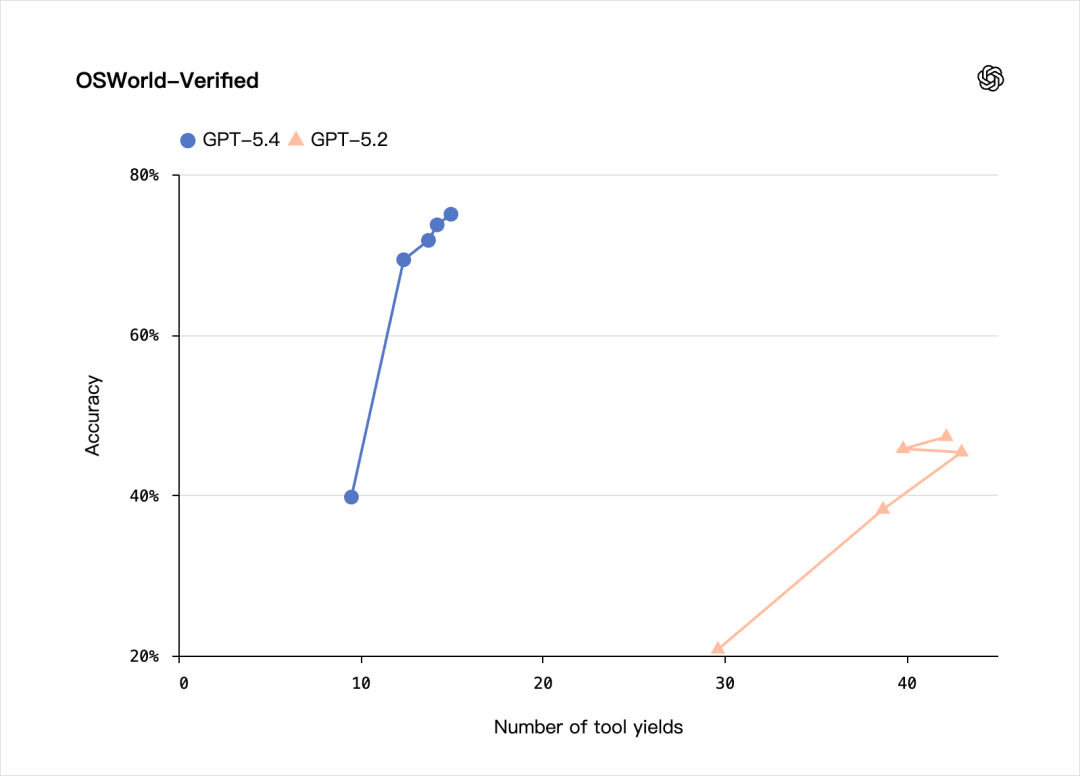
看下这个没有加速过的视频,会更直观。
