


新智元报道
编辑:犀牛
【新智元导读】Karpathy让Agent通宵跑了110次实验把模型练强后说了句「去桑拿了」,然后开源630行代码的autoresearch,一块GPU就能拥有一个永不下班的AI研究实验室——人类研究员的新工作,是写好提示词然后去蒸桑拿。
刚刚,Karpathy在x上发了一条让整个AI圈炸锅的帖子:
ah yes, this is what post-agi feels like :) i didn't touch anything. brb sauna
啊对,这就是后AGI的感觉 :) 我什么都没碰。先去蒸桑拿了。
什么样的技术突破,能让这位AI大神如此淡定地撂下一句话就去蒸桑拿?
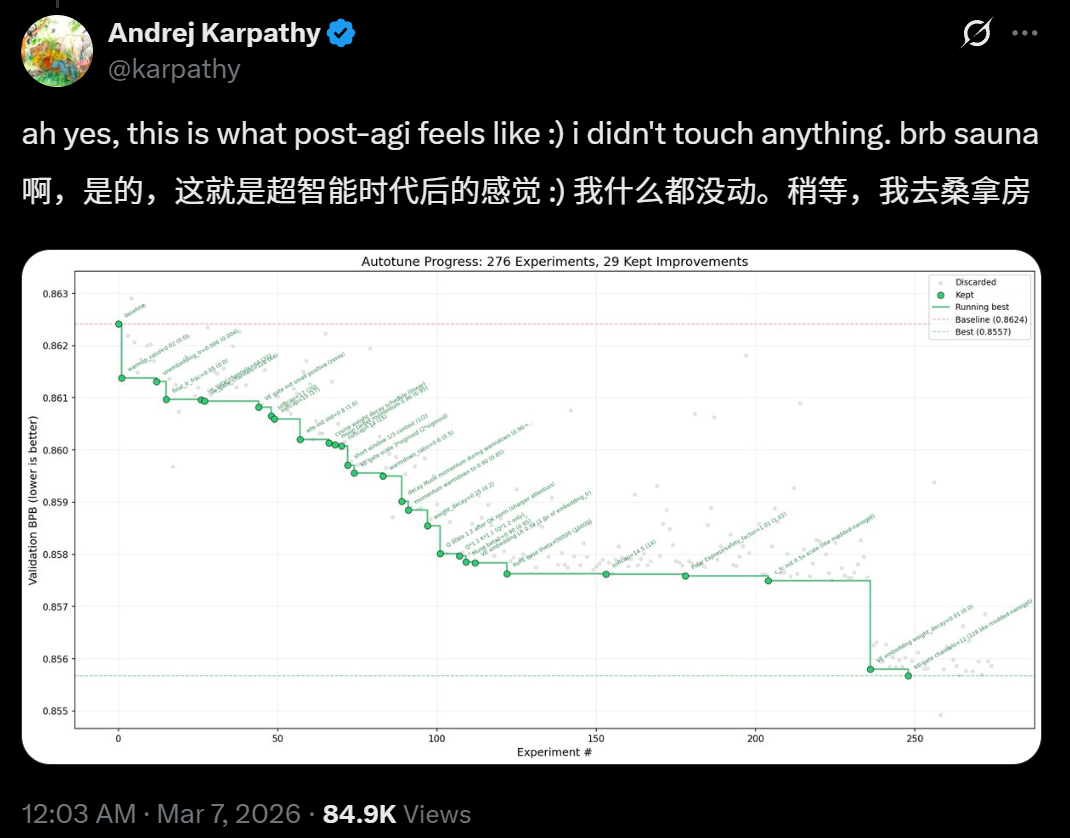
答案是:他的AI Agent,在他睡觉的12个小时里,自主提交了110次代码变更,把一个语言模型的验证损失(val loss)从0.862415一路压到了0.858039——而且没有增加一秒钟的训练时间。
更炸裂的是,就在几天后,Karpathy把这套「AI自己搞科研」的方法论打包成了一个仅630行代码的开源项目——autoresearch,扔到了GitHub上。
项目地址:https://github.com/karpathy/autoresearch
上线刚几个小时,就已冲到了3k星标!
Karpathy表示,任何人只要有一块GPU,就能在一夜之间运行一个AI研究实验室。

这两件事叠在一起,构成了一幅前所未有的画面:AI不再只是人类的工具,它开始自己优化自己了。
而人类研究员的新工作,变成了——写一份提示词,然后去蒸桑拿。

nanochat
100美元训一个ChatGPT
故事要从Karpathy的nanochat项目说起。
nanochat是Karpathy在2025年10月开源的一个项目,口号相当炸裂——「100美元能训练的最好的ChatGPT」。
nanochat项目地址:https://github.com/karpathy/nanochat
它用大约8000行干净的PyTorch代码,实现了一个完整的、从零开始的语言模型训练流水线:分词、预训练、微调、强化学习、推理、Web UI,一条龙全包。
在一个8块H100 GPU的节点上,花4个小时左右,你就能训出一个可以跟你聊天的小型ChatGPT。
但nanochat真正让人兴奋的地方,不在于它有多便宜,而在于它有多「可迭代」。
整个项目围绕一个核心参数——Transformer的深度(depth)。
你只要拧这一个旋钮,其他所有超参数(宽度、头数、学习率、训练时长、权重衰减……)都会自动调整到计算最优。
换句话说,这是一个极简但极其精密的训练系统,天然适合用来做实验。
昨天,nanochat取得了一个里程碑式的进展:在单个8×H100节点上,仅用2小时就能训出GPT-2级别能力的模型。
一个月前这个数字还是3小时。
但真正的重头戏来了——Karpathy开始让AI Agent自动迭代nanochat的训练代码。
具体怎么玩的?
他给AI代理写了一份大约120行的Markdown文档,相当于一份「任务说明书」,告诉AI:这个项目是干什么的,什么样的改进算好的(验证损失更低),什么样的改进不能接受(训练时间变长、内存爆炸、代码变得太臃肿)。
然后,AI Agent就开始在一个Git特性分支上自主工作:读代码、想主意、改代码、跑训练、看结果。
如果效果变好,就合并到主分支;如果效果变差或者训练变慢,就丢弃,重新来过。
结果呢?
12个小时,110次代码提交,d12模型的验证损失从0.862降到了0.858,降了0.004——对于语言模型来说,这是一个实实在在的进步,而且是在不增加任何训练时间的前提下取得的。
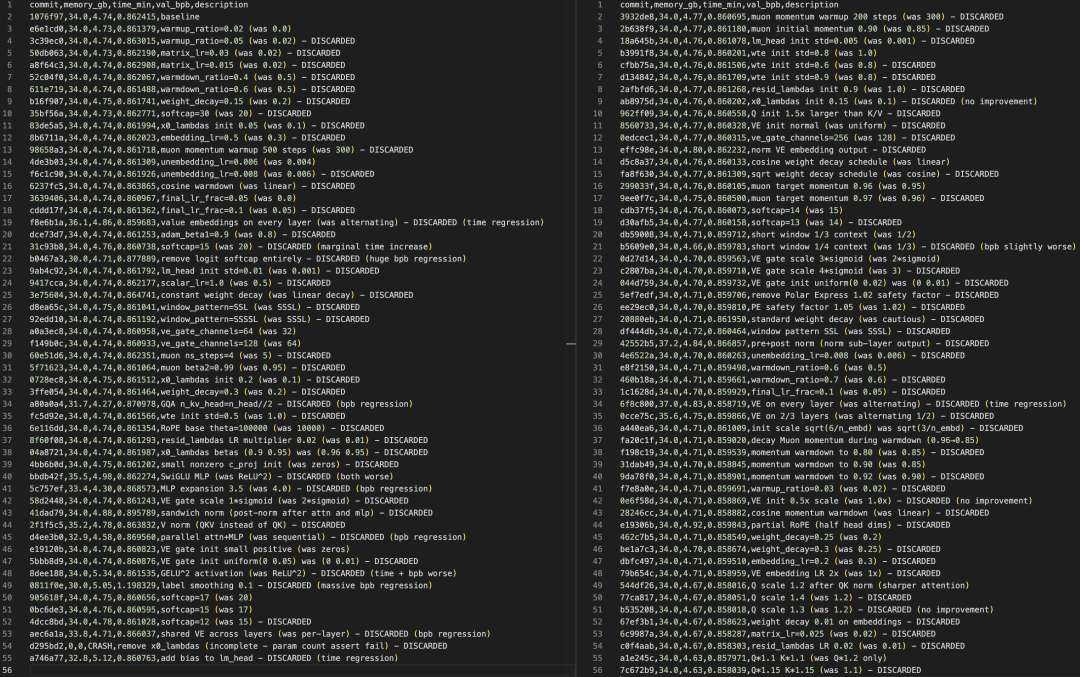
有一个特别有意思的细节:其中有一次提交,AI代理确实把val loss降下来了,但训练时间变长了,于是被系统自动拒绝了。
Karpathy设的规则很严格——要么改善损失,要么改善速度,要么两个都改善,不能拆东墙补西墙。
更有意思的是Karpathy自己的反思。
他说,在过去两周里,他花在「调优AI代理的工作流程」上的时间,几乎比他直接改nanochat代码的时间还多。
他迭代的不是代码本身,而是「让AI更好地迭代代码的那套系统」——一个「元优化」的过程。

这意味着人类研究员的角色正在发生质变:从「亲手写代码做实验」,变成了「设计一个能让AI自动做实验的系统」。
Karpathy把这种感觉称为「后AGI(post-AGI)」。
当然,他自己也说这个说法半开玩笑——今天的AI代理在实现想法方面已经相当厉害,但在提出创造性的新想法方面还差得远,目前更接近于一个自动化的超参数调优工具,而不是一个真正的研究员。
但他紧接着说了一句意味深长的话:「随着AI能力的提升,这条路的方向是清楚的——AI在自主改进下一代自己。」
autoresearch
630行代码,一块GPU,5分钟一轮实验
如果说nanochat上的AI代理自动迭代是一次「概念验证」,那么autoresearch就是Karpathy把这个概念打包成了一个人人可用的开源工具。
Karpathy正式开源了autoresearch项目。
他给这个项目写了一段极具科幻感的序言:
曾几何时,前沿AI研究还靠着一群碳水化合物计算机——他们在吃饭睡觉摸鱼的间隙,偶尔通过组会仪式用声波互相吼两嗓子,就这么推进着人类的技术边界。
那个年代已经一去不返。如今,研究完全被AI智能体接管……据说代码已经迭代到了第10205代,但这数字真伪已无从考证——那些代码早已进化为能自我修改的二进制生命,远远超出了人类的认知范畴。
这个代码仓库,正是这一切故事的起点。

虽然这段话写的是「未来愿景」,但autoresearch项目本身的设计,已经在认真地朝着这个方向迈步。
autoresearch本质上是nanochat的「精简单机版」。
Karpathy把大模型训练的核心代码压缩到了一个约630行的Python单文件里,在单块GPU上就能跑。
整个项目只有三个核心文件:
prepare.py —— 数据准备:下载训练数据、训练BPE分词器,还有运行时需要的数据加载器和评估工具。这个文件是固定的,AI不会碰它。
train.py —— 训练代码:包含完整的GPT模型定义、优化器(Muon + AdamW)和训练循环。从模型架构、超参数、优化器到批量大小,AI代理可以修改这里的一切。
program.md —— 人类写给AI的「指令书」:用自然语言描述研究目标和约束条件,人类研究员通过编辑这个文件来引导AI的工作方向。
项目的核心机制堪称精妙——固定5分钟训练时长。
不管你用的是什么GPU,不管AI代理怎么改模型大小、批量大小、架构设计,每一轮训练都精确控制在5分钟。
这个设计有两个好处:第一,所有实验结果直接可比,因为计算预算是固定的;第二,AI代理会自动为你的特定硬件找到最优配置。
你一晚上睡8个小时,AI代理大约能跑100轮实验。第二天早上起来,你面前摆着的是一份详细的实验日志,和一个(大概率)比昨晚更好的模型。
整个工作流被Karpathy概括为两句话:
人类负责迭代提示词(.md文件)
AI代理负责迭代训练代码(.py文件)
AI代理在一个Git特性分支上自主循环运行:改代码→训练5分钟→检查分数→如果更好就提交→如果更差就回滚→继续改。
每个提交都是一次经过验证的改进,像搭积木一样一层层往上垒。
而Karpathy为这个项目设定的终极目标,说出来有点疯狂:设计出能够无限期、无需任何人工干预、以最快速度取得研究进展的AI Agent。
一块GPU,一个文件,一个指标——这就是整个实验环境。
从「人做实验」
到「人设计做实验的AI」
传统的AI研究是这样的:一个博士生(或者一群博士生)想到一个idea,写代码实现,跑实验,看结果,改参数,再跑,再看,周而复始。
Karpathy自己就说,这基本上是他整个博士期间做的事情。
一个idea从提出到验证,可能要花几天甚至几周——因为人要吃饭,要睡觉,要开组会,要跟导师battle,要修bug修到怀疑人生。
现在呢?
AI代理不吃饭不睡觉不摸鱼不抱怨,它24小时不停地跑实验,5分钟一轮,一晚上100轮。
它不会因为连续跑了20次实验都失败了就心态崩了去刷社交媒体——它只会冷静地分析结果,调整策略,继续下一轮。
当然,Karpathy自己也坦率地承认:AI现在非常擅长实现想法,但在提出真正创造性的新想法方面还差得远。
autoresearch目前的工作方式,更像是一个极其勤奋且不知疲倦的「超参数调优工程师」,而不是一个能提出变革性理论的研究员。
但关键在于——趋势是清晰的。
Karpathy说的那句话,几乎可以作为这个时代的注脚:
AI在自主改进下一代的自己,人类研究员偶尔往里面扔几个想法就行了。
这不是科幻,这是今天正在GitHub上开源运行的代码。
而autoresearch的开源,让这件事的门槛降到了令人瞠目的程度。
现在,一个独立开发者,一块GPU,一份精心写好的提示词,就能在一夜之间跑完一个小型研究实验室一周的工作量。
这对整个AI开发生态的潜在影响是深远的。
中小团队甚至个人开发者,也能参与到模型训练和优化的竞技场中。
AI研发的民主化,正在从获取模型(开源权重)推进到优化模型(自动化实验)。
更深层次地看,autoresearch代表的是一种新的「人机协作范式」:人类负责定义问题、设定约束、提供方向性的直觉;AI负责在巨大的搜索空间里不知疲倦地试错和优化。
人类的创造力和AI的执行力,第一次以一种系统化的方式结合在了一起。
去蒸桑拿吧
世界正在被改写
回到Karpathy那条著名的帖子——「this is what post-agi feels like, brb sauna」。
这句话的妙处在于,它既是一句玩笑,也是一个真实的信号。
当一个AI领域最顶尖的研究者,能够放心地把模型优化的工作交给AI代理,自己去蒸桑拿而不是在电脑前盯着训练日志——这本身就说明了一些深刻的东西。
AI自主工作的能力已经跨过了一个临界点:它不仅能执行明确的指令,还能在一个真实的、开放的研究环境中,自主地发现改进空间并付诸行动。
Karpathy为autoresearch写的那段序言里有一句话特别值得玩味——这个代码仓库,正是这一切故事的起点。
这不是终点,这只是结束的开始。
AI代理在今天还只是一个不知疲倦的调参高手。
但明天,当模型能力再上一个台阶,当它们不仅能实现想法还能提出想法的时候——那个Karpathy笔下「代码进化为自我修改的二进制生命」的科幻场景,或许并没有我们想象的那么遥远。
到那时候,也许我们所有人都该去桑拿了。
