

克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
用OpenClaw挂机,抓取网页时频频翻车的烦人bug终于有解了。
一个名为Scrapling的数据采集神器,几乎一夜之间就成了OpenClaw的“最强外挂”。
这玩意儿不仅能穿透各种防爬虫的网页护盾,还能把网上杂乱的网页源码生扒下来,直接清洗成干净的结构化数据。
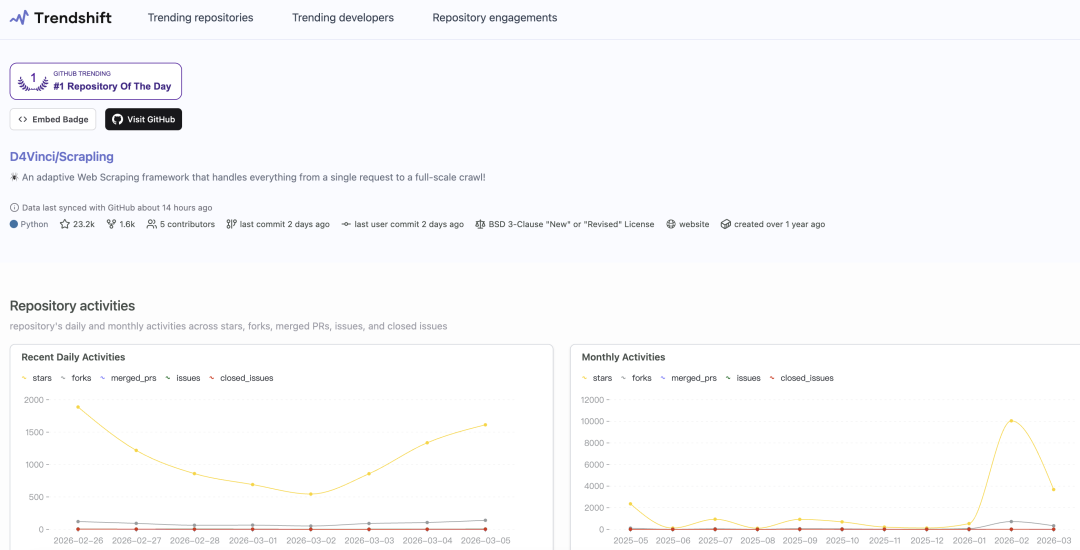
摇身一变成为龙虾神器后,这个发布一年多的项目人气直接大爆发,狂揽2.3万stars,一口气冲上了GitHub单日趋势榜第一名。
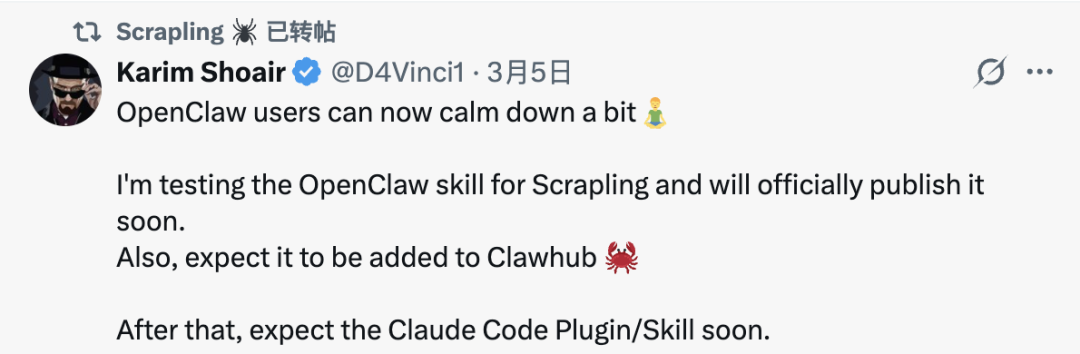
工具爆火之后,原作者也已经明确放话,正在把Scrapling做成OpenClaw的Skill,期待值直接拉满。
数据爬虫成了AI挂机神器
让智能体上网抓数据,最烦的就是遇到那种动不动就跳出来让你选图片的真人验证,稍微不注意就会被关进小黑屋。
Scrapling自带的StealthyFetcher隐身获取器专门就是来搞定这些恶心拦截的。
它能完美模拟最新版浏览器的指纹和操作行为,帮OpenClaw开箱即用地绕过这些阻拦。
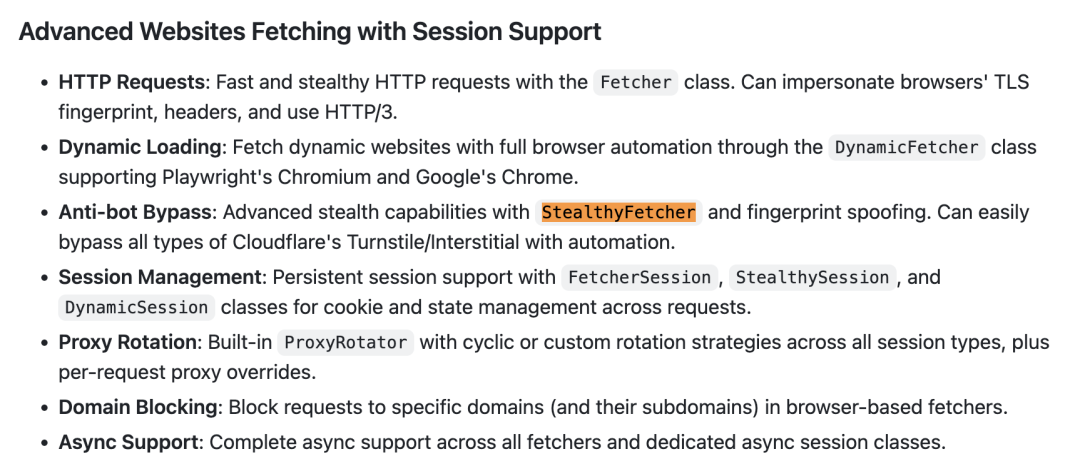
除了躲过拦截,还得应付网站老板一拍脑袋就搞的改版换皮。
以前那些老旧的爬虫工具实在太死板了,它们通常死死扣住几个固定的路径,只要网页排版稍微挪动一丁点,原本好好的自动化任务就会立刻罢工报错。
这种崩溃会直接导致AI任务流瞬间瘫痪,甚至本来看一下网页就知道的信息,还得费劲去研究怎么改代码。
Scrapling最硬核的地方在于它拥有一套智能的自适应算法。
即使网站为了防爬或者是为了换新视觉而彻底打乱了HTML结构,它的解析器也能通过相似度比对自动感知数据在哪,然后重新定位到正确的关键信息上。
有了这种不需要人工干预的智能追踪能力,小龙虾就能实现真正的24小时“稳如老虾”,再也不用担心大半夜因为网站悄悄更新而让挂机任务全线断更了。
轻松上手,还能省钱
既然AI已经能像回自己家拿东西一样,顺溜地绕过拦截并搞定网页改版,那接下来的重点就是怎么更聪明地处理这些信息。
方法很简单,只要开启Scrapling内置的MCP模式就可以了。
在数据喂给大模型之前,它会先精准提取正文,把网页里那些又长又臭的废话、乱七八糟的广告和没用的冗余代码统统剔除掉。
因为喂给AI的内容变精简了,API调用的Token费用自然也就大幅降了下来,主打一个省钱又省心。
除了能帮咱们省钱,它对挂机环境的要求也极其亲民。
这个框架内存占用非常小,哪怕你手头只有个吃灰多年的旧笔记本,或者是租个入门级服务器,它都能轻松跑起来。

而且它还专门设计了断点记忆功能,这对于长时间挂机任务来说简直是救命稻草。
万一遇到偶尔断网或者是突然断电,爬取进度也会被牢牢保存下来,等网络或电源恢复了,它就能无缝接力继续干活,完全不需要手动去重启任务。
而且这个插件不仅不挑机器,也不挑人,不必会用Python写代码,它直接提供了一套开箱即用的命令行工具。
只要照着教程在黑窗口里敲一行非常简单的短指令,就能立刻调用它的全部采集能力。
再加上作者本人表示正在把插件做成龙虾的Skill,每个普通用户都有希望能轻松给自己的OpenClaw武装上一双看透全网、精准抓取数据的眼睛了。
