

Agent类型的AI应用,在2025年和2026年迎来了爆发,典型的产品是Claude Code和OpenClaw。它们分别服务的是程序员群体和知识工作者群体,其中Claude Code的年化收入在今年2月已突破25亿美元。
尽管ChatGPT已经拥有近10亿月活用户,但以ChatGPT为代表的ChatBot范式,用户平均每日的token消耗量大概在十万到百万量级。而在Agent范式下,用户每日token消耗量可达到千万甚至上亿,直接提升了一个数量级。
单用户token消耗量的指数级提升,对于推理计算系统提出了新要求。
对于NVIDIA,以往它们的GPU是针对模型训练计算需求优化的,对于推理计算需求,它有精度冗余(训练要求FP32,推理只需要INT8),能耗高,延迟高的问题,其实并不适用。
此后,NVIDIA通过在硬件上引入Tensor Core,在软件上加入TensorRT,一定程度上缓解了在推理算力上的不足,但是直到2026年的NVIDIA GTC大会,它才真正解决了这个问题。
Groq LPU的加入,平衡了推理算力的高吞吐、低延迟需求
先分析下推理算力对于算力系统有什么需求。
站在云厂商的角度,首先是吞吐量,也就是计算中心每花一兆瓦的能量,在每秒可以生成多少token。这既是一个性能指标,也是一个成本指标。
一个算力数据中心的总瓦数是确定的,每兆瓦能产生更多的token,在给定的成本下,能效和经济效益都会提升。
吞吐量是ToB客户关心的指标,对于C端用户,延迟是使用体验中感知最明显的部分。但是在技术上,高吞吐和低延迟是互斥的。
这背后主要的技术瓶颈在于推理计算式批处理 (Batching) 带来的等待和内存墙 (Memory Wall)。
内存墙的主要问题是,在高吞吐(高并发)状态下,多个请求同时去抢夺有限的显存带宽,会导致数据传输拥堵,计算单元被迫排队等待数据,从而拉长了所有请求的延迟。
GPU在吞吐量上本身很有优势,所以打破内存墙,成为现在AI推理算力产品主要优化的方向。
此前,我们介绍过Google TPU团队创立的MatX,它解决这个内存墙的方法是采用混合存储架构(SRAM和HBM结合)。HBM储存适用于高吞吐的并行计算,SRAM则适合低延迟的decode和token生成。

图片来源:NVIDIA官方
NVIDIA的解决办法也是SRAM和HBM结合,只不过它是通过一整个算力系统实现的。
在2025年12月花200亿美金收购来Groq后,NVIDIA在2026年GTC上发布了Groq 3 LPU,而且已经量产。
Groq 3 LPU搭载的是片上SRAM储存,但是问题在于SRAM虽快但容量极小,单颗Groq 3 LPU只有500MB SRAM。与Groq 3 LPU搭配使用的Rubin GPU,它有288GB HBM4储存。但这就有一个问题,它们俩的储存容量差了500多倍,根本存不下万亿参数的模型。
NVIDIA对此的解决方法是一套叫Dynamo的软件,它可以把推理过程拆成两半,Rubin负责prefill和attention(高并发运算部分,处理上下文),Groq负责feed-forward部分的decode和token生成(需要极低延迟和极高带宽)。
两者通过数据中心内部的以太网紧耦合,实现了延迟减半。黄仁勋在发布会上把这种技术定义为解耦推理(disaggregated inference)。在这种架构下,每兆瓦推理吞吐量最高可提升35倍。
事实上,与以往的发布会不同,此次NVIDIA拿出的不是单个的GPU,而是算力系统平台。上文讲的Groq 3 LPU+Rubin GPU的结合,在实际部署中,是平台与平台的结合。
Vera Rubin平台包括Vera CPU(ARM架构)、Rubin GPU、NVLink 6交换机、NVIDIA ConnectX 9网卡、BlueField4 DPU和Spectrum-6以太网交换机。
具体来说,Vera Rubin NVL72机架上集成了72个Rubin GPU和36个Vera CPU,它们通过NVLink 6连接,并配备ConnectX-9 SuperNIC和BlueField-4 DPU。

图片来源:NVIDIA官方
Groq 3 LPU以LPX机架形式存在,可以无缝集成到Vera Rubin平台中,一个LPX机架包含了256个LPU处理器,提供128GB片上SRAM和640TB/s的纵向互联带宽。
在大规模部署时,大量LPU可以协同工作,像一个巨型单一处理器一样运行;当与Vera Rubin NVL72机架一起部署时,它们可以很好的实现万亿参数模型与百万token上下文的推理,在功耗、内存与计算效率之间实现平衡。
黄仁勋还剧透了Feynman架构,在2028年,现有计算系统的七个组件将全部换代,会有全新GPU、LP40 LPU、Rosa CPU、BlueField 5 DPU,ConnectX-10 SuperNIC,NVLink 8。并且机架会同时支持铜缆和CPO光学互连。
所谓CPO(共封装光学),指的是将光通信模块与核心计算芯片(如交换机ASIC或GPU)直接封装在同一个物理基板上的技术。它能让交换机的网络能效提升约3.5倍到5倍,网络延迟大幅降低,同时可靠性大幅度提升,NVIDIA宣称其网络信号完整性提升了64倍。LPX机架无缝集成到Vera Rubin平台中,靠的就是这种技术。
Agent应用爆发,倒逼推理算力和模型革新
除了硬件,NVIDIA此次发布的软件,重点集中在Agent上,包括NemoClaw和Nemotron 3 Super。
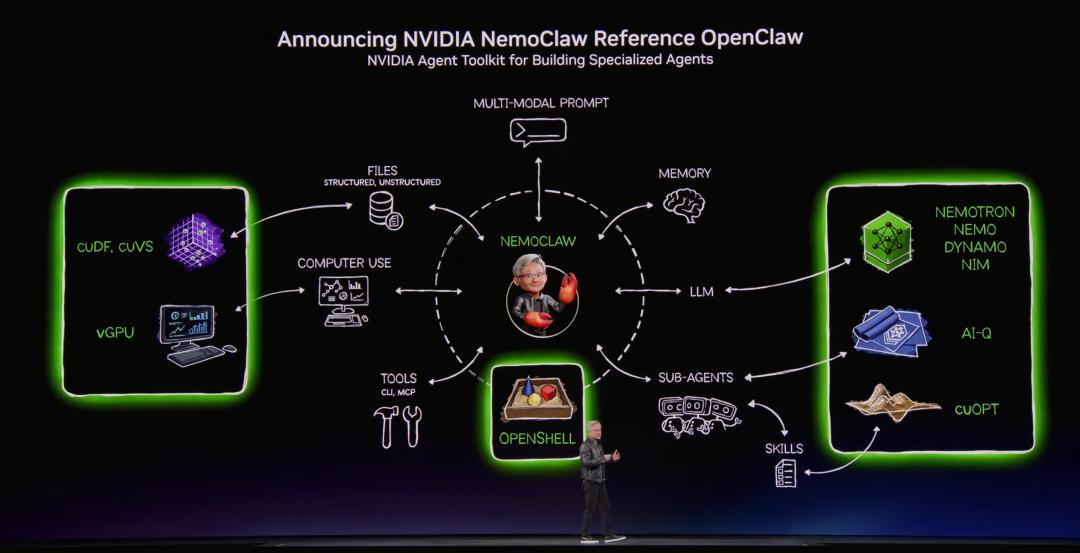
图片来源:NVIDIA官方
NemoClaw本质就是一套让OpenClaw更容易部署、也更安全运行的基础软件工具,相当于给它套了一层安全的壳,让企业更容易使用。
它的核心组件叫OpenShell,包含策略引擎接口(对接企业已有的安全合规系统)、网络护栏(限制Agent网络访问边界)和隐私路由(防止敏感数据外传)。
它让 AI 智能体在执行任务、调用工具或访问外部网络时,依然能够受到安全、网络和隐私策略的约束。
Nemotron 3 Super是专为Agent打造的模型,黄仁勋展示了一张图,表示它在OpenClaw上的表现排行前列,仅次于Anthropic和OpenAI的顶尖模型。

图片来源:NVIDIA官方
从这两个软件类产品的发布,可以看出NVIDIA并不满足于当一个单纯的AI基础设施厂商,它们渴望向AI价值链的更前端攀升。黄仁勋在GTC前写了一篇署名文章,提出了AI的“五层蛋糕”架构,现在NVIDIA就要从第四层的算力,第三层的基础设施,往第二层的模型攀登。
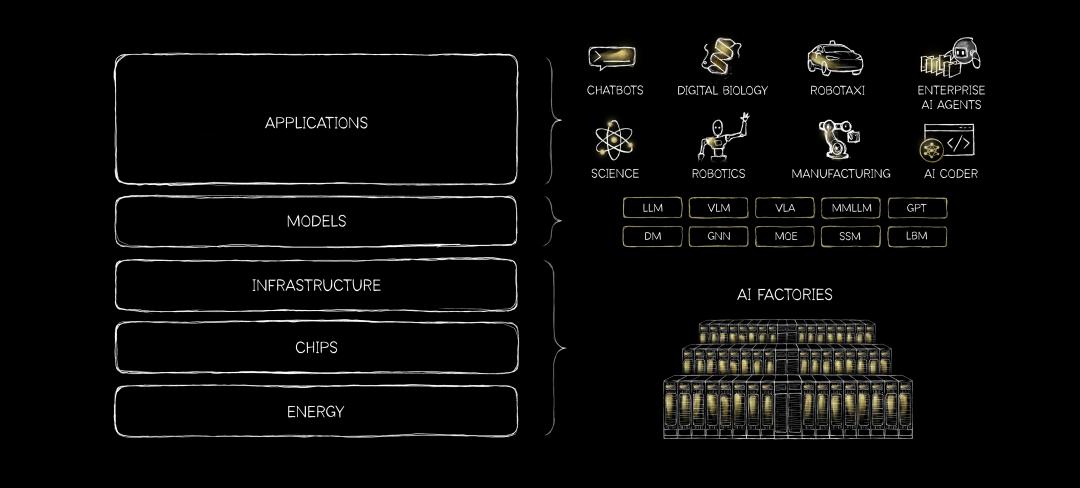
图片来源:NVIDIA官方
毕竟,算力是AI的基石,但是AI的价值,终究要在应用层真正体现。
而且,在生成式AI发展几年后,现在AI在应用端的需求已经明确,开始倒逼模型和基础设施根据应用需求进行针对性的优化了。
在2023-2024年,产品思路是以模型能力为基础,进行应用的搭建,那时还有一些套壳应用的生存空间。
当Agent崛起后,AI真正切入生产环境,开始产生真实的商业价值(很多企业的程序员已经大比例使用Agent编程,法律和客服等领域的Agent渗透率也较高),就出现了Claude这样为编程优化的模型,以及Nemotron 3 Super和GLM5-Turbo这样针对Agent优化的模型。
另一方面,与云端AI相比,物理AI还处于早期,无论是AI原生硬件、端侧模型,AI OS,还是具身智能数据,都还大有机会,阿尔法公社已经在这个领域布局了不少优秀的创业公司。
