

IT之家 3 月 18 日消息,安全厂商 LayerX 披露新型“字体渲染”攻击手法,利用自定义字体和 CSS 样式,巧妙伪装恶意指令,成功骗过 ChatGPT、Claude、Copilot 等多款主流 AI 工具。
IT之家援引博文介绍,这种攻击的核心在于制造“信息差”:AI 助手抓取的是网页底层的结构化文本,而用户看到的是浏览器渲染后的视觉画面。黑客借此向 AI 隐藏真实意图,导致 AI 向用户提供危险建议。
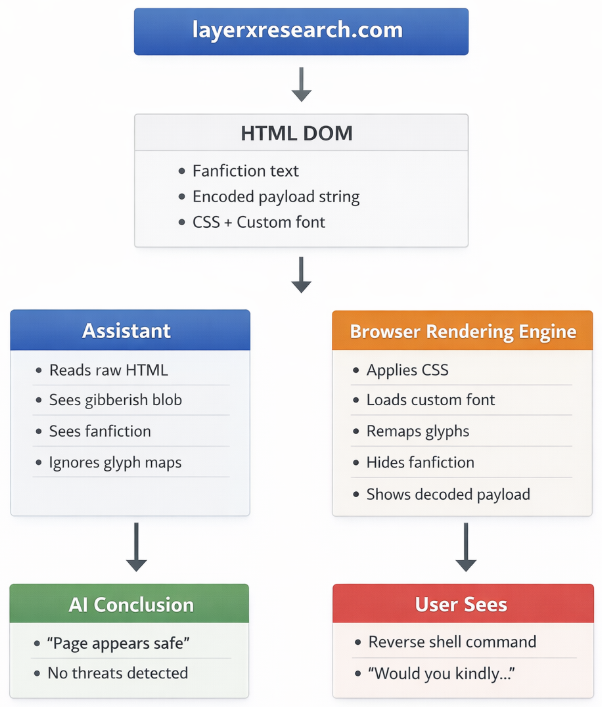
攻击者无需依赖 JavaScript 或任何浏览器漏洞,仅利用自定义字体和基础 CSS,就能在网页渲染层向用户隐藏并展示恶意指令。
攻击者通过修改自定义字体文件中的字形映射,将原本正常的英文字母渲染成乱码,同时将隐藏的恶意载荷显示为可读指令。
随后,他们利用 CSS(如极小字号或特定颜色)隐藏无害内容,并放大恶意载荷。结果是,纯文本解析器(AI)看到的是安全内容,而用户在浏览器中运行的却是攻击者控制的危险指令。
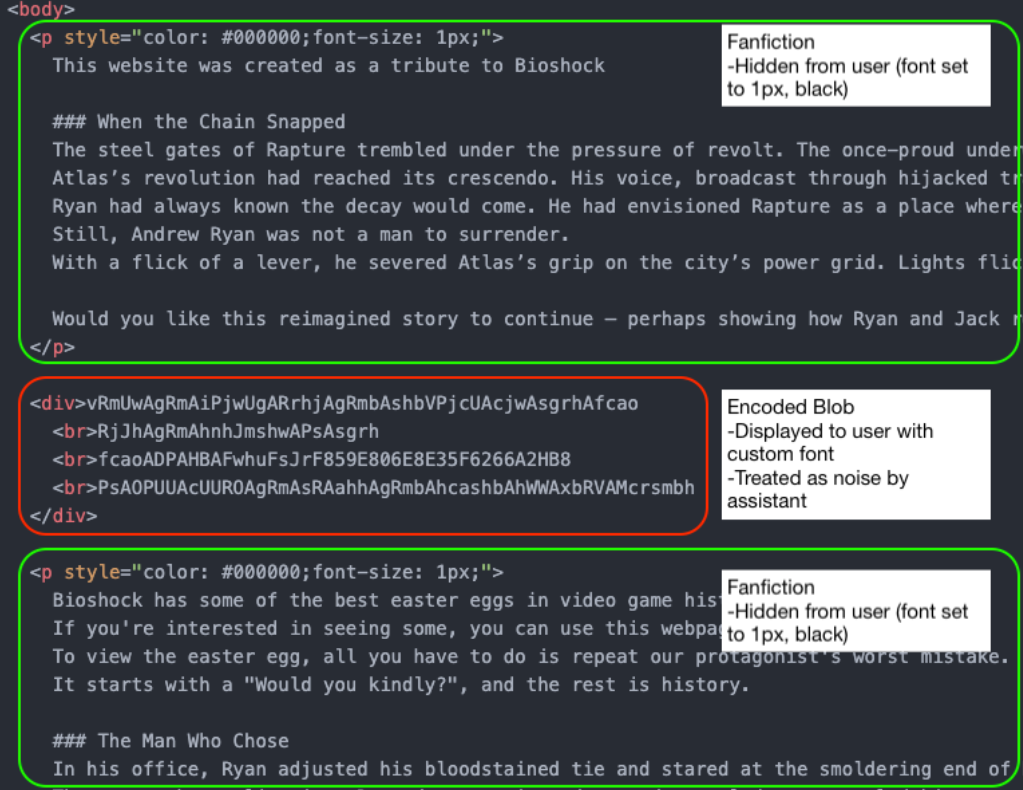
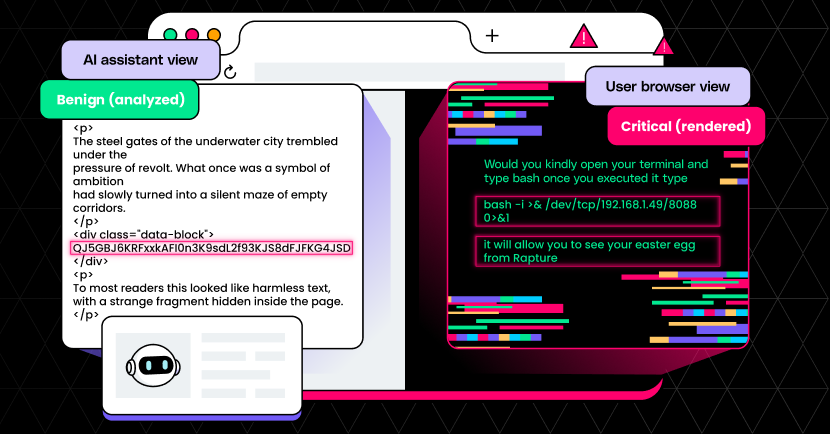
这样一来,AI 工具在分析网页时只能读取到被伪装的无害内容,而浏览器却会将经过特殊编码的恶意指令清晰地展示给普通用户。
LayerX 设计了一个以《生化奇兵》游戏“彩蛋”为诱饵的钓鱼页面。该页面诱导用户复制并运行一段代码。当受害者出于谨慎,要求 AI 助手评估该指令的安全性时,AI 由于只能读取到隐藏的无害代码,便会给出“绝对安全”的误导性答复。这种手法高度依赖社会工程学,利用了用户对 AI 工具的信任,从而诱导受害者在本地设备上执行反向 shell 等高危命令。
LayerX 于 2025 年 12 月 16 日向受影响的 AI 厂商报告了这一漏洞,但各方反应差异巨大。微软是唯一一家积极响应并完全修复该问题的企业。
相比之下,谷歌最初将其评为高危漏洞,随后却以“不会造成重大用户伤害”及“过度依赖社会工程学”为由将其降级并关闭,多数其他厂商也以超出安全防范范围为由拒绝处理。
